We are happy to share that BigML is bringing Boosted Trees to the Dashboard and the API as part of our Winter 2017 Release. This newest addition to our ensemble-based strategies is a supervised learning technique that can help you solve your classification and regression problems even more effectively.
To best inform you about our impending launch, we have prepared a series of blog posts that will help you get a good understanding prior to the official launch. Today, we start with the basic concepts of Boosted Trees. Subsequent posts will gradually dive deeper to help you become a master of this new resource by: demonstrating how to use this technique with the BigML Dashboard, presenting a use case that will help you discern when to apply Boosted Trees, how to use Boosted Trees with the API, as well as how to properly automate it with WhizzML. Finally, we will conclude with a detailed technical view of how BigML Boosted Trees work under the hood.
Let’s begin our Boosted Trees journey!
Why Boosted Trees?
First of all, let’s recap the different strategies based on single decision trees and ensembles BigML offers to solve classification and regression problems, and find out which technique is the most appropriate to achieve the best results depending on the characteristics of your dataset.
-
BigML Models were the first technique BigML implemented, they use a proprietary decision tree algorithm based on the Classification and Regression Trees (CART) algorithm proposed by Leo Breiman. Single Decision Trees are composed of nodes and branches that create a model of decisions with a tree graph. The nodes represent the predictors or labels that have an influence in the predictive path, and the branches represent the rules followed by the algorithm to make a given prediction. Single decision trees are a good choice when you value the human-interpretability of your model. Unlike many ML techniques, individual decision trees are easy for a human to inspect and understand.
-
Bagging (or Bootstrap Aggregating), the second prediction technique brought to the BigML Dashboard and API, uses a collection of trees (rather than a single one), each tree built with a different random subset of the original dataset for each model in the ensemble. Specifically, BigML defaults to a sampling rate of 100% (with replacement) for each model. This means some of the original instances will be repeated and others will be left out. Bagging performs well when a dataset has many noisy features and only one or two are relevant. In those cases, Bagging will be the best option.
-
Random Decision Forests extend the Bagging technique by only considering a random subset of the input fields at each split of the tree. By adding randomness in this process, Random Decision Forests help avoid overfitting. When there are many useful fields in your dataset, Random Decision Forests are a strong choice.
In Bagging or Random Decision Forests, the ensemble is a collection of models, each of which tries to predict the same field, the problem’s objective field. So depending on whether we are solving a classification or a regression problem, our models will have a categorical or a numeric field as objective. Each model is built on a different sample of data (if Random Decision Forests also using a different sample of fields in each split), so their predictions will have some variation. Finally, the ensemble will issue a prediction using component model predictions as votes aggregating them through different strategies (plurality, confidence weighted or probability weighted).
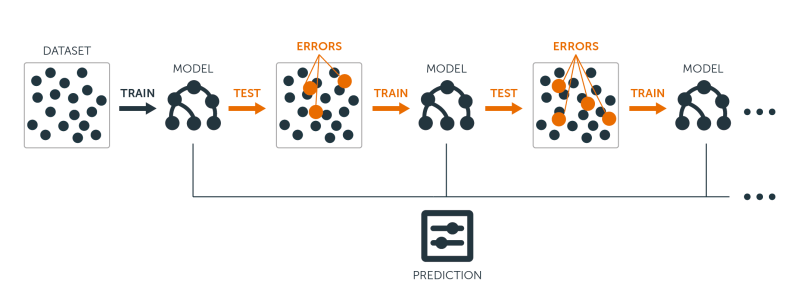
The boosting ensemble technique is significantly different. To begin with, the ensemble is a collection of models that do not predict the real objective field of the ensemble, but rather the improvements needed for the function that computes this objective. As shown in the image above, the modeling process starts by assigning some initial values to this function, and creates a model to predict which gradient will improve the function results. The next iteration considers both the initial values and these corrections as its original state, and looks for the next gradient to improve the prediction function results even further. The process stops when the prediction function results match the real values or the number of iterations reaches a limit. As a consequence, all the models in the ensemble will always have a numeric objective field, the gradient for this function. The real objective field of the problem will then be computed by adding up the contributions of each model weighted by some coefficients. If the problem is a classification, each category (or class) in the objective field has its own subset of models in the ensemble whose goal is adjusting the function to predict this category.
For Bagging and Random Decision Forests each tree is independent from one another making them easy to construct in parallel. Since a boosted tree depends on the previous trees, a Boosted Tree ensemble is inherently sequential. Nonetheless, BigML parallelizes the construction of individual trees. That means even though boosting is a computation heavy model, we can train Boosted Trees relatively quickly.
How do Boosted Trees work in BigML?
Let’s illustrate how Boosted Trees work with a dataset that predicts the unemployment rate in US. Before creating the Boosted Tree ensemble we split the dataset in two parts: one for training and one for testing. Then we train a Boosted Tree ensemble with 5 iterations by using the training subset of our data. Thanks to the Partial Dependence Plot (PDP) visualization, we observe that the higher the “Civilian Employment Population Ratio” the lower the unemployment rate, and vice versa.

But, can we trust this prediction? To get an objective measure of how well our ensemble is predicting, we evaluate it in BigML as any other kind of supervised model. The performance of our first attempt is not as good as it could be. A simple way of trying to improve it is to increase the number of iterations the boosting algorithm performs in order to improve its tree. Remember that, in our first attempt, we set that number to the very conservative value of 5. Let’s create another Boosted Tree, but this time with 400 iterations. Voila! If we compare the evaluations of both models, as shown in the image below, we observe a very significant performance boost, both in the lower absolute and squared errors and in the higher R squared value for our ensemble with 400 iterations.

Stay tuned for the upcoming posts to find out how to create Boosted Trees in BigML, interpret and evaluate them in order to make better predictions.
In Summary
To wrap up this blog post we can say that Boosted Trees:
- Are a variation of tree ensembles, where the tree outputs are additive rather than averaged (or majority voted).
- Do not try to predict the objective field directly. Instead, they try to fit a gradient by correcting mistakes made in previous iterations.
- Are very useful when you have a lot of data and you expect the decision function to be very complex. The effect of additional trees is basically an expansion of the hypothesis space beyond other ensemble strategies like Bagging or Random Decision Forests.
- Help solve both classification and regression problems, such as: churn analysis, risk analysis, loan analysis, fraud analysis, sentiment analysis, predictive maintenance, content prioritization, next best offer, lifetime value, predictive advertising, price modeling, sales estimation, patient diagnoses, or targeted recruitment, among others.
For more examples on how Boosted Trees work we recommend that you read this blog post as well as this alternative explanation, which contains a visual example.
Want to know more about Boosted Trees?
Please visit the dedicated release page for more documentation on how to create Boosted Trees, interpret them, and predict with them through the BigML Dashboard and the API; as well as the six blog posts of this series, the slides of the webinar, and the webinar video.

One comment