In this blog post, the third one in our six post series on Boosted Trees, we will bring the power of Boosted Trees to a specific example. As we have seen in our previous post, Boosted Trees are a form of supervised learning that combine every tree in the ensemble additively to answer classification and regression problems. With BigML’s simple and beautiful dashboard visualizations, we’ll revisit our answer to who will win the Oscar for Best Actor.
The Data
Already engineered for our recent Oscar predictions post, we took data from many sources, particularly including many related awards, to see if we can answer one of the biggest questions in Hollywood: who will win at the Oscars this year? We did generally well with our Random Decision Forests. Of the eight categories we attempted, we got five correct and another two were knife’s edge calls between the winner and our picks. But can we do even better with Boosted Trees?
The Chart
One major way Boosted Trees differ from Random Decision Forests is that there are more parameters than can be changed. This is both powerful as we can tune the tree to exactly what we want but also intimidating as there are so many knobs to turn! In a future blog post, we will show how to automatically choose those parameters. In this example, however, we will be working with the iterations slider.
As we have seen, Boosted Trees work by using every iteration to improve on the previous one. This may seem like more iterations are always better, however, this is not always the case. In some cases, we could slowly be stepping toward some optimal answer, but our improvements are so slight with each iteration that it’s not worth the time invested in them. So how to know when to stop? That’s what early stopping does for us. BigML has two forms of early stopping, Holdout and Out of Bag. Holdout reserves some subset of the training data to evaluate how far we have come with each iteration. If the improvement is minimal, the ensemble stops building. It then reruns using all of the data for the chosen number of iterations. Out of Bag uses some of the training data that is not currently being used to build this iteration to gauge the improvement. It is faster than Holdout early stopping, in general, but because it is reusing data that was used for training in earlier iterations it is not as clean a test.
In this example, we chose just 10 iterations with a learning rate of 30%. In general, lower learning rates can help find the best solutions, but need more iterations to get there. Our example also uses the Out of Bag early stopping option.
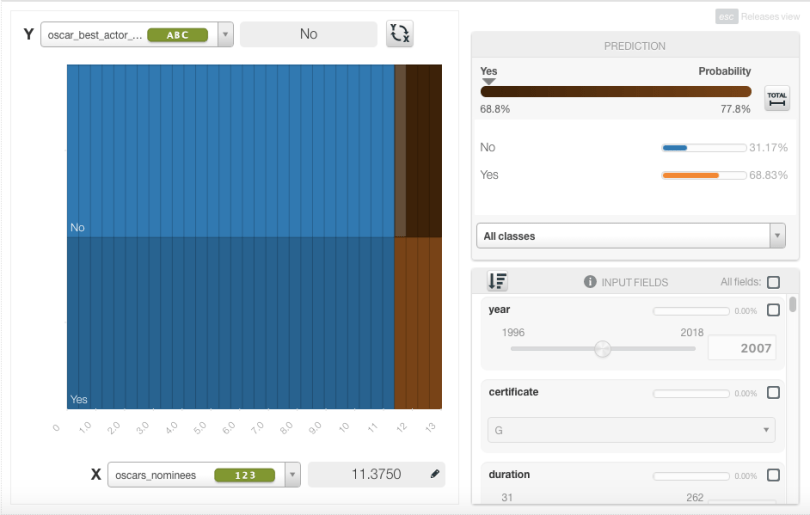
With the Ensemble Summary Report we can see that the two most important fields to this decision are the number of Oscar Categories Nominated and whether it had a Best Actor Nomination.

With the field importance chart, we can also see what other categories are important: Reviews, BAFTA winner, Screen Actors Guild winner, and LA Film Critics Association nominee. We can already see an aberration with this model; clearly an actor must be nominated for best actor to win the award. So we’d expect that to be the most important field, not the second.
Looking at the PDP, we see it is broken into four main sections. The two bluish sections are where the probability is greatest that the movie doesn’t win a Best Actor award, while the red sections are where the probability is that it does. Again, something strange is going on here. The upper right quadrant is coded red which means the model believes an actor could win the award even without a nomination!
Let’s create a different Boosted Tree, this time with 500 iterations and a 10% learning rate. As before, we will employ tree sampling at 65%, building each iteration on a subset of the total training data. For classification problems, there is one tree per class per iteration, for regression problems, just one tree per class.
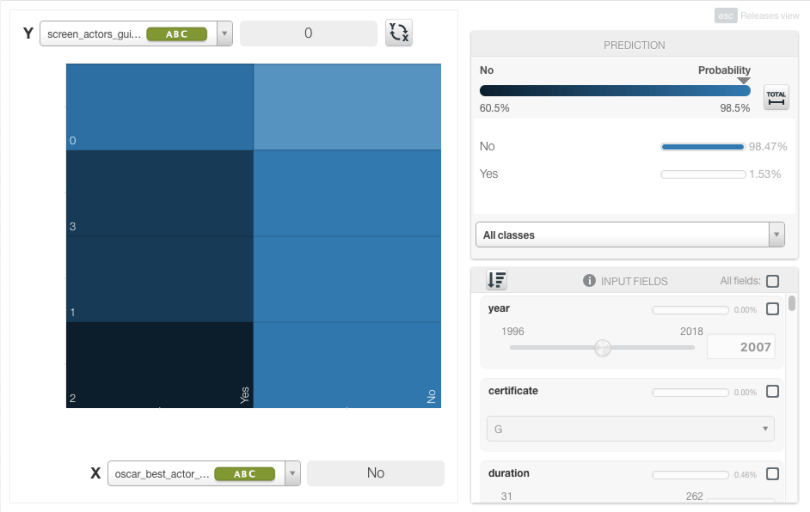
Already we see an improvement. Whether the film is nominated for a Best Actor Oscar is now the most important field. The other top fields include whether it won a Screen Actors Guild award for Best Actor, User Reviews, and its overall rating. This is very different from our first example, which relied heavily on other awards. We also see, as we expect, that movies that didn’t get nominated will not get a best actor award.
Predictions
But what exactly do our Boosted Trees predict? Looking just at the more promising second model, we can create a Batch Prediction with the movies data just from 2016.
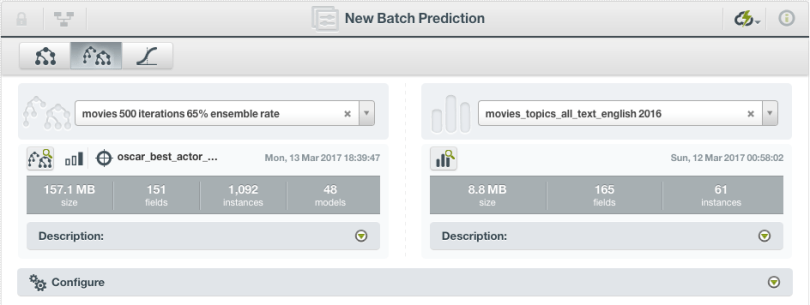
In order to get the probabilities of each row, we will go under Configure, and then Output Settings to select the percent sign icon. This will add two columns to our output dataset, one for each class in our objective field: the probability that the movie wins a Best Actor Oscar and the probability that it does not. This way, we can see not only whether the model predicts a win, but also by how much.

Our Boosted Trees predict… drumroll please… four different actors might win the Oscar! That is, four different actors have a very good chance of winning. Let’s see who we have: Ryan Gosling in La La Land, Denzel Washington in Fences, Andrew Garfield in Hacksaw Ridge, and finally Casey Affleck in Manchester by the Sea.
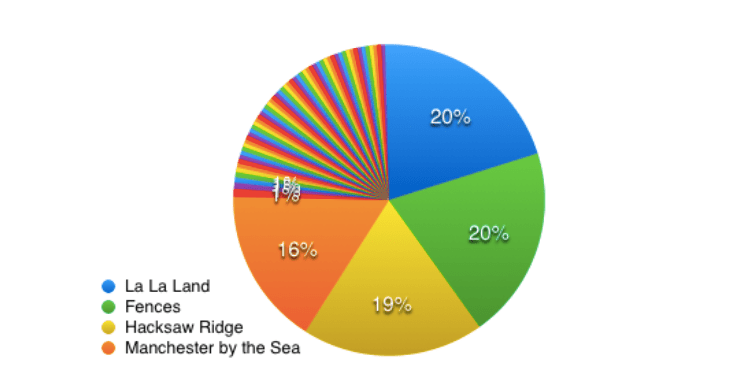
Here are the normalized probabilities. All four of these candidates are within a few percent of each other, with Mr. Affleck perhaps the furthest behind. No wonder our model picked four winners! And no wonder we had such a hard time predicting the win with our Random Decision Forest. The race was simply too close to call until the big night.
In the next post, we will see how to create Boosted Trees from the BigML API.
Would you like to know more about Boosted Trees? Please visit the dedicated release page for more documentation on how to create Boosted Trees, interpret them, and predict with them through the BigML Dashboard and the API; as well as the six blog posts of this series, the slides of the webinar, and the webinar video.

2 comments