Machine Learning is accelerating its transition from academia to industry. We see more and more media outlets reporting about it, but most of the time they exclusively focus on the final results and not in all the human-powered tasks that happen behind the scenes and that really make the magic possible. So for most people Machine Learning continues to be some sort of elusive magic. We were recently approached by One, the Vodafone-sponsored section of El Pais, to explain how Machine Learning works and, after giving it some thought, we decided to explain it using a simple example in a domain everyone is familiar with. As the 89th annual Academy of Motion Picture Arts and Sciences Award ceremony draws near and movie fans all over the world are getting ready for their office pools, we couldn’t resist the temptation to take a stab at predicting the 2017 Oscars by applying some BigML-powered Machine Learning courtesy of our own Teresa Álvarez and Cándido Zuriaga.
Of course, picking Oscar winners remains a favorite pastime for many people every winter. As usual, there’s no shortage of opinions ranging from those of movie critics to POTUS Donald J. Trump to established media outlets that publish more data-driven analysis. One thing that many of these crystal balls have in common is the fact that none of them give the reader access to the underlying data, logic or models. Time for us to change that for the better!
Caveat Emptor
No model is perfect, so before we go ahead and reveal our picks, a word of caution is in order.
Our main objective with this exercise is to demonstrate the process that is usually followed in order to make a prediction by using Machine Learning.
The Oscars nominees and winners are selected by vote of the Academy members. To properly model this problem, we should also model the Academy members and all the factors that influence how they pick and choose their favorite movies. However, we have restricted our effort to publicly available information about the movies and not about the Academy members.
Furthermore, the nature of the problem itself is ever evolving. The Academy is not a monolithic structure and the body of membership, the rules that apply to the nomination, and voting processes are subject to change over the years. A great example of that is the recent introduction of a new batch of Academy members in response to the complaints on the lack of diversity. So past behavior is not always the best predictor of future behavior.
- Finally, tastes change. One can argue that “The Academy” has stronger roots in tradition as than other movie industry awards, but we can’t deny that what works in one era is not guaranteed to translate to another without any changes. In our digital age, it is no longer a pipe dream to imagine a small budget art house movie released with the right timing at the right festivals and riding a big wave of word-of-mouth promotion on social media to finally steal the show from blockbusters that major movie studios bankroll. The times they are a’changin!
So let’s begin!
1. Problem Definition and Context Understanding
Stating the predictive problem is the most critical step in any Machine Learning workflow, as it totally shapes the rest of our solving process. Predicting an Oscar winner can be modeled as a classification task, that is, we need to create a predictive model that given a movie released in 2016 will output ‘yes’ when it predicts that the movie will win the Oscar and ‘no’ otherwise. In predicting this year’s Oscar winners, we decided to limit our predictions to only 8 out of the 24 awarded categories.
The next step is to collect and prepare some data about movies and what made them winners in those categories in the past, as well as those same attributes for 2016 movies. The more context and business understanding of the problem you have, the more prepared you are to decide what data to collect. A couple of business insights guided our data collection process:
- Of the total of approximately 600 films nominated since 2000, 62% are from the USA with an average budget of $50M, more than 3 times higher than the European budgets and 20 times higher than the Latin American countries.
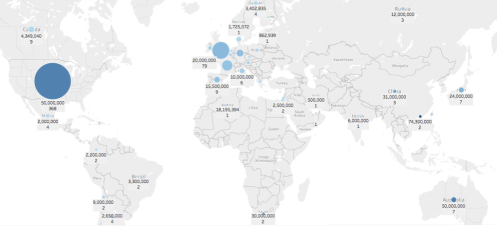
- The budget amount is correlated with subsequent income from the movie, but it does not seem to be strongly correlated to winning an Oscar. Moreover, for the analyzed period, the difference in the average budget between films that win Oscars and those that don’t varies wildly. So we are not expecting budget to be a significant factor in our models.
2. Data collection and data transformations
In virtually all Machine Learning projects, the most time consuming task is collecting and structuring data. In our case, due to time constraints, we anticipate that we have left out a lot of data that could be very valuable in making predictions. For example: actresses and actors with previous nominations or awards, or the number of Oscars previously received by the nominated director, scriptwriter, etc. It is also very important to select how far back in time your training data should go; not going far enough might mean missing something useful, but going too far back is going to pick up patterns that are probably no longer relevant (in the business we sometimes call this bad practice “doing archeology”). We decided to use movies between the years 2000 and 2016.
For that period of time, we have compiled a dataset that combines:
- Movie metadata such as genre, year, budget etc. as well as user ratings and reviews from IMDb for the 50 most popular movies of each year
- Each year’s nominations and winners of 20 key industry awards, including The Academy Awards, Golden Globes, BAFTA, Screen Actors Guild, Critics Choice, Directors Guild, Producers Guild, Art Directors Guild, Writers Guild, Costume Designers Guild, Online Film Television Association, People’s Choice, London Critics Circle, American Cinema Editors, Hollywood Film, Austin Film Critics Association, Denver Film Critics Society, Boston Society of Film Critics, New York Film Critics Circle, and Los Angeles Film Critics Association.
An added complexity is that, for data like ratings and reviews, it is difficult to determine if they were impacted by the fact that the movie was nominated for an Oscar or not. In other words, we don’t have the ability to reconstruct the exact timeline of our data’s construction.
We must also note that despite our best efforts to cleanse the dataset, there may still be some inaccuracies in the data itself. The final dataset that we have compiled is a wide one with fairly small number of rows, due to the nature of the problem (after all this is a once a year event with a different set of contestants each year). This makes models prone to noise and overfitting, even though the selection of ensembles as our algorithm mitigates this risk to some extent. You can get access to our input dataset via this BigML shared link or via BigML’s dataset gallery here.
3. Data Exploration
A good warm-up exercise in any predictive task is a visual perusal of the data. One such fishing expedition using BigML’s Association Discovery capabilities netted some interesting associations:
Nominees for best film are usually dramas and biographies and seldom action films. Among the winners, we did not find a strong correlation with genre since the nominees already belong to a tight group of genres.
When using Association Discovery to find the most important correlations between the Oscars and other awards, we saw especially notable correlations with the Golden Globes or the Critics Choice awards, among a few others.
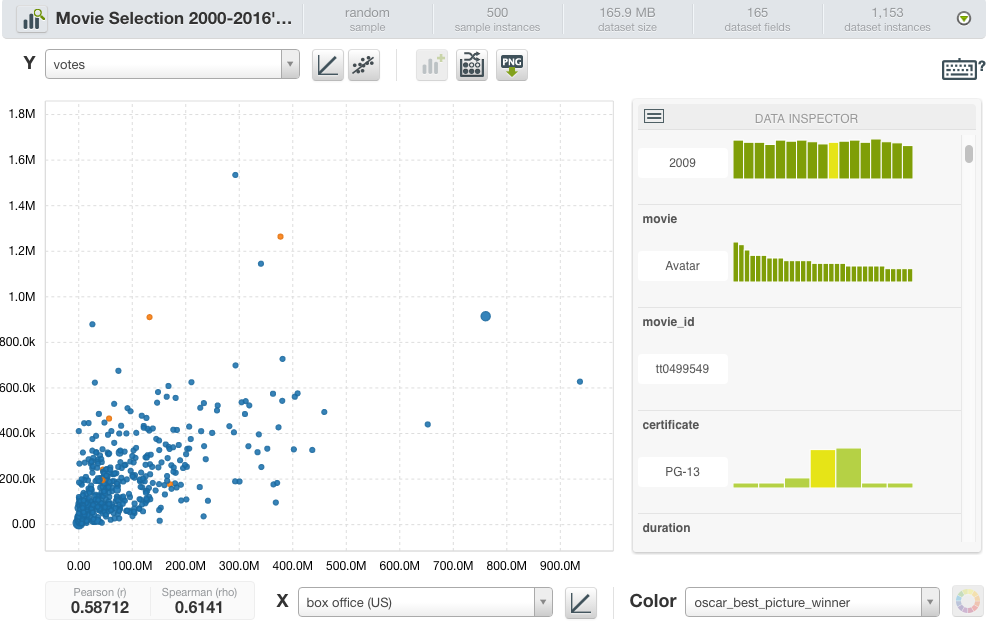
- As shown in the scatter plot below, not always the movies with higher box office or more votes win the Oscar to the best picture.
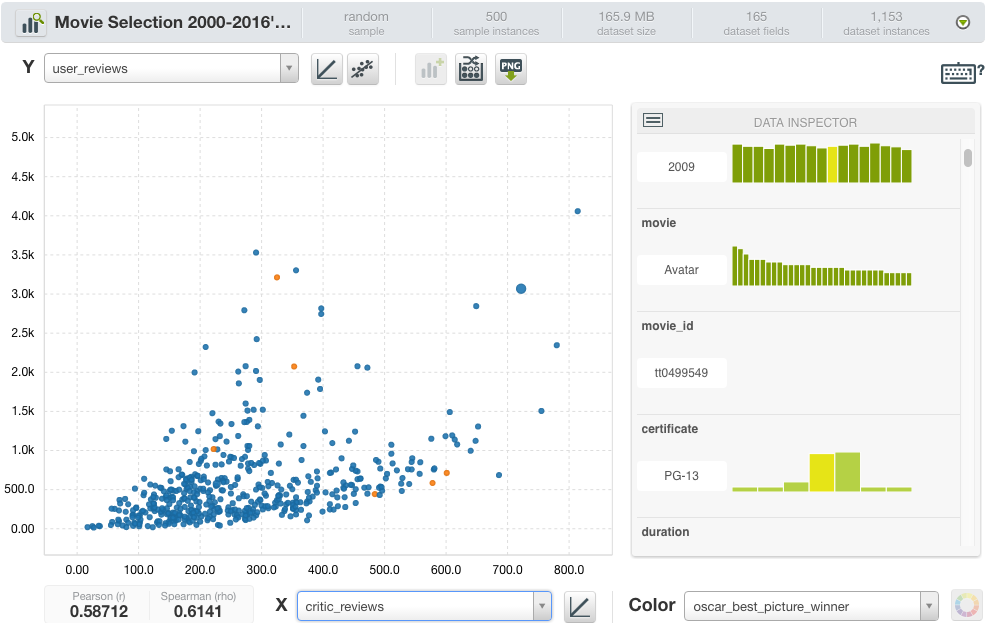
- Something similar happens with user and critics review:
4. Feature Engineering
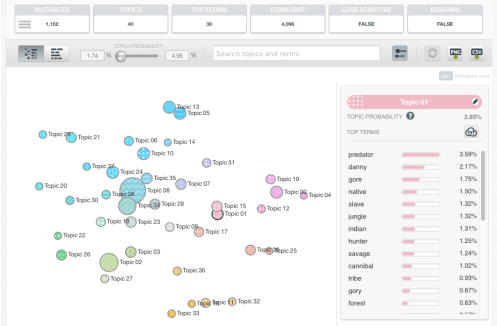
Most datasets can be enriched with some extra features, derived from existing ones, that can increase the predictive power of the data. In our case, since the unstructured movie reviews can be challenging to analyze, we ran all the IMDb user review data through a Topic Model analysis, which automatically discovers a set of topics that can be used to characterize each data row. Then, for each movie, the set of topics and their associated probabilities were added as new features to our dataset. All told, our Machine Learning-ready dataset is composed of 256 different fields for 1,152 movies produced since 2000. Once the a dataset is ready, the modeling and evaluation tasks become easy-peasy-lemon-squeezy with BigML.
5. Modeling
Usually predictive modeling involves comparing and selecting the appropriate classification algorithms and their specific parameters. Most of this process can be fully automated, although you need to be aware of the hype around full-automation. In our case, after a few tries and given our limited historical data and the need to avoid overfitting, we opted for tree ensembles over a decision tree or logistic regression. So we created 8 separate binary classification models (one per award category) with the objective field (the column we want to predict) being “winner”.
6. Evaluation
To assess the predictive impact of each group of variables per category (e.g., metadata, ratings, reviews to unveil the Best Picture Winner), we took a stepwise approach, where we made different predictions based on different ensembles built on different subsets of our dataset. This approach showed us the contribution of different types of data to the final combined prediction, and helped guide our efforts to pull together more data on certain aspects when needed. For instance, discovering that focusing on award data yields better results, translated into the collection of even more historical award data for better final predictions.
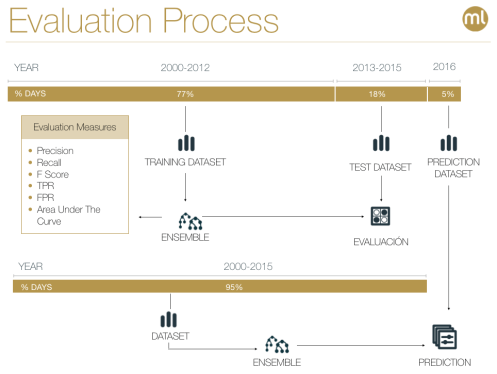
To evaluate our classification models, we used the period between 2000-12 as the training period, and 2013-15 as the test period. We then input the data for 2016 nominees to the already validated ensembles to arrive at our final predictions.
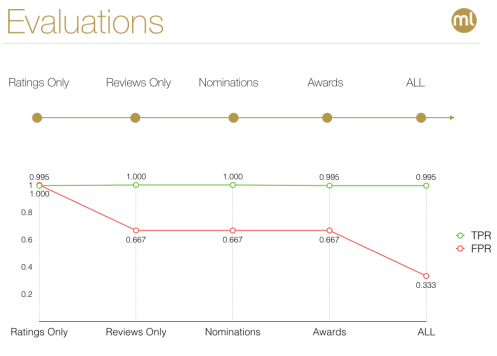
Evaluation results demonstrated that combining all available variables yields the best results by essentially reducing the False Positives, while maintaining a very high True Positive hit rate.
7. The Predictions: Drum rolls, please…
So let’s finally see what our models found out!

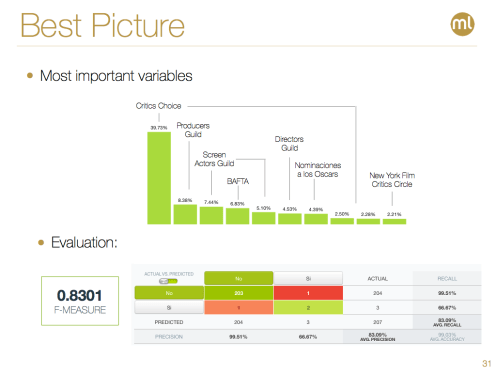
It seems everyone’s sentimental favorite musical La La Land will have a big prize to show for the record 14 nominations it received this year. When we delve into the major drivers behind this prediction, we observe that the Critics Choice nomination and award it received along with its other award performances (with the Producers Guild, Screen Actors Guild and BAFTA especially sticking out) explain why La La Land is the favorite with a pretty high F-measure to boot.
However, if we dig deeper and look at how non-award data have played into the predictions we see a different picture, where IMDb user reviews are favoring Fences, and award nominations are accentuating the small budget wonder Moonlight. But when actual award winnings are added and all the factors are combined, La La Land emerges as the #1 pick. Can we be in for a surprise Sunday night? Maybe so, but it would have to be one epic upset, so the chances are rather low.
Now that we have lifted the veil of mystery regarding the most anticipated award of the night, let’s quickly recap the remaining categories.
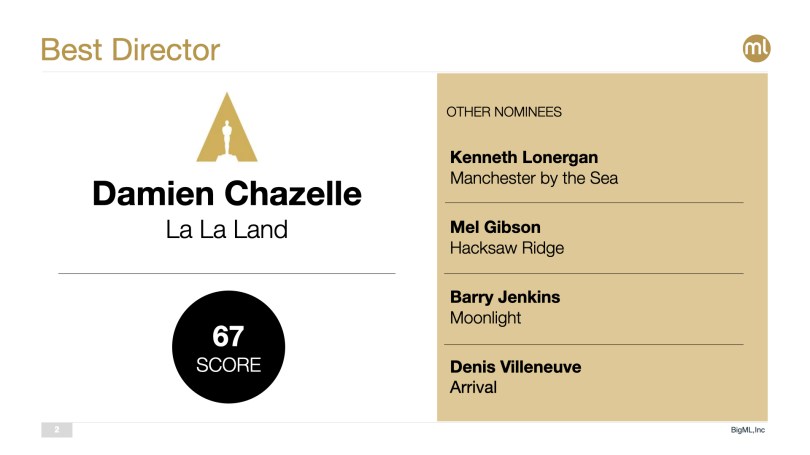
No big surprises here with Damien Chazelle expected to pick up the Best Director award consistent with his success in the awards circuit—especially Directors Guild.

Best Actress will go to Emma Stone carrying the tally for La La Land even higher. Again, Golden Globe and Screen Actors Guild pickups are the biggest forces pushing her nomination forward.
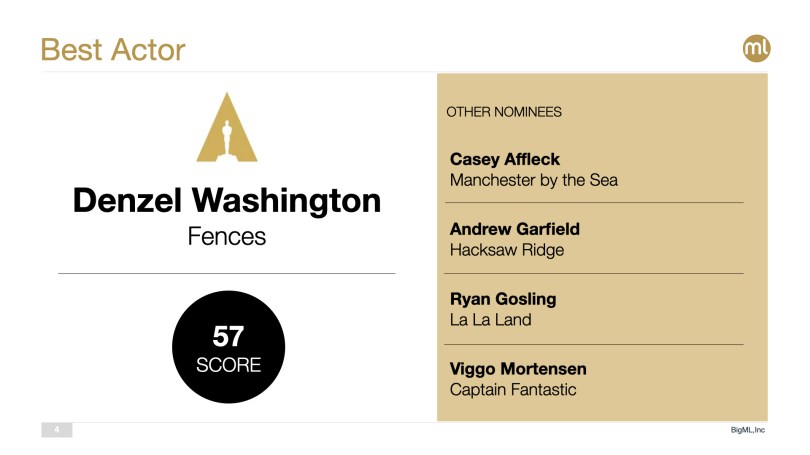
This year’s Best Actor category is a close call between Casey Affleck (Manchester by the Sea) and Denzel Washington (Fences), thus the lower confidence prediction here. Screen Actors Guild award going to Denzel Washington definitely makes a difference for him, but Casey Affleck has picked up more awards in total and, per our model, that seems to help him get a slight edge. We’ll only find out on Sunday whether The Academy’s judgement was at all clouded by the personal troubles of Mr. Affleck despite what most agree was a stellar acting performance.

Viola Davis (Fences) is the popular favorite for Best Supporting Actress thanks mainly to her performance in BAFTA, Screen Actors Guild and New York Critics Circle awards.

Best Supporting Actor award is another category with a number of viable choices. Our pick is Mahershala Ali (Moonlight). Most critics seem to be highlighting Mahershala Ali and Dev Patel as the favorites in this category as well. Mahershala Ali is somewhat handicapped by the model since he wasn’t able to pick up the Golden Globe for this category, which translates into a rather low confidence value for this prediction. Interestingly, the Nocturnal Animals actor Aaron Tayor-Johnson won the Golden Globe, but he is not even a nominee for the Oscars. Actually, in one of our preliminary models we made the mistake of inputing the Golden Globes wins for Michael Shannon and as it has been nominated to best supporting model, our model predicted him as the winner. This was helpful to remind us how careful you need to be not only collecting and cleaning the right data for training your models, but also making sure you input the right one at prediction time.
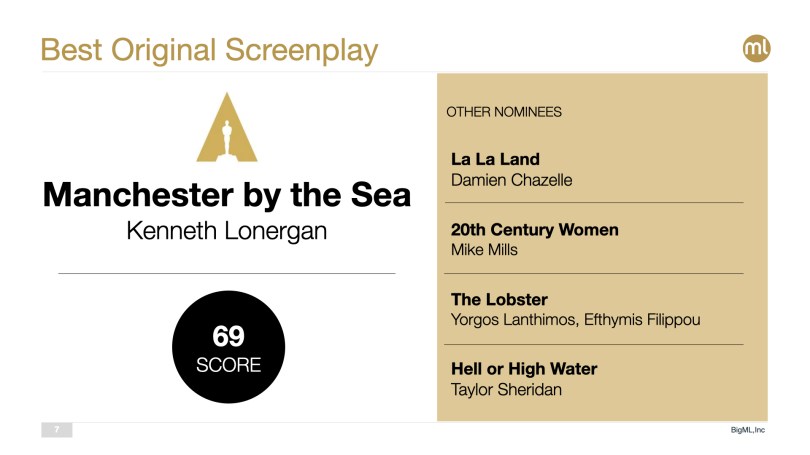
Best Original Screenplay is also very much in play with La La Land and Manchester by the Sea vying for the award. La La Land seems to have a very slight edge on the back of its BAFTA success, but don’t count out Manchester by the Sea just yet.

Finally, Best Adapted Screenplay will likely go to Arrival since the movie did quite well within the award circuit for the category.
Lessons Learned
Besides being a fun undertaking, this exercise has been further testament to the power and importance of working with the right dataset and paying due attention to feature engineering. Being able to construct the best features remains the biggest return on time invested, especially in the presence of a solid Machine Learning platform like BigML where:
- Some of the most versatile algorithms ever invented are offered via an intuitive interface (as well as a thorough API).
- Scalability concerns are abstracted away for the end-user to concentrate on the analytical task at hand.
- Flexible deployment options make it a breeze to operationalize chosen models working with the right data.
At the end of the day, feature engineering is the reflection of true expertise in a given domain into the models you build.
We hope you will find these predictions useful as you grab a glass of wine and follow Jimmy Kimmel kicking off the ceremonies on Sunday. Good luck with your picks!
