If you’ve been following our blog posts recently, you know that we’re about to release another variety of ensemble learner, Boosted Trees. Specifically, we’ve implemented a variation called gradient boosted trees.
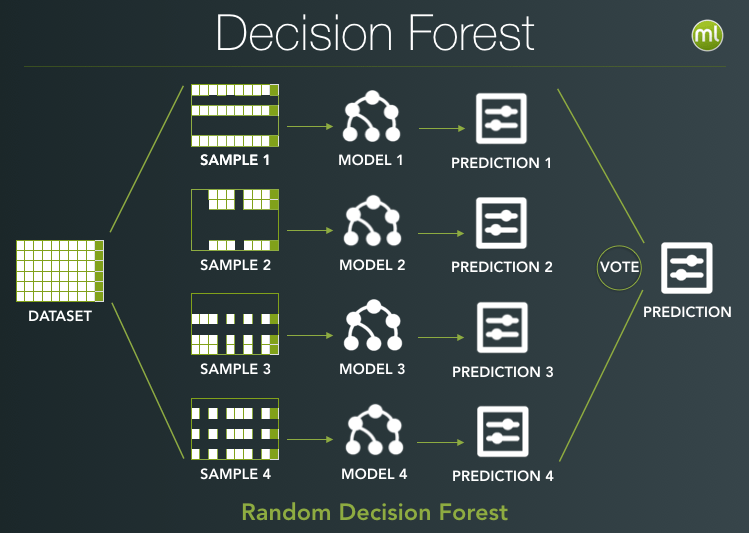
Let’s quickly review our existing ensemble methods. Decision Forests take a dataset with either a categorical or numeric objective field and build multiple independent tree models using samples of the dataset (and/or fields). At prediction time, each model gets to vote on the outcome. The hope is that the mistakes of each tree will be independent from one another. Therefore, in aggregate, their predictions will come to the correct answer. In ML parlance, this is a way to reduce the variance.
With Boosted Trees the process is significantly different. The trees are built in serial and each tree tries to correct for the mistakes of the previous. When we make a prediction for a regression problem, the individual Boosted Trees are summed to find the final prediction. For classification, we sum up pseudo-probabilities for each class and run those results through Softmax to create final class probabilities.
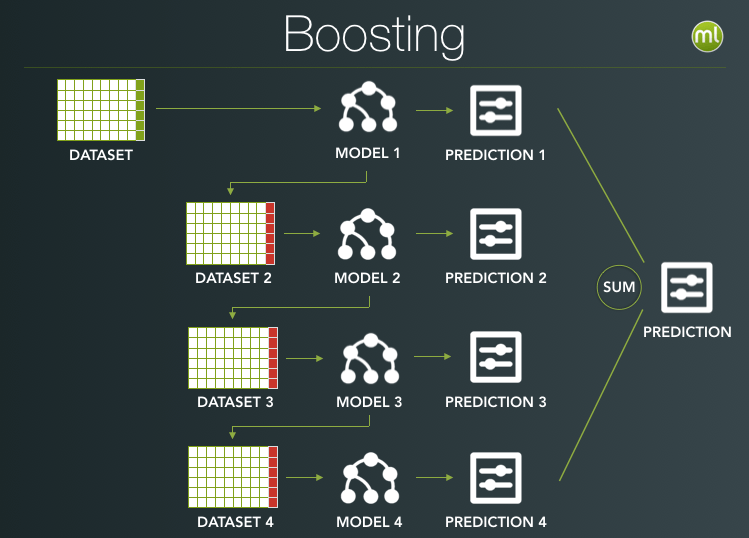
Each iteration makes our boosted meta-model more complex. That additional complexity can really pay off for datasets with nuanced interactions between the input fields and the objective. It’s more powerful, but with that power comes the danger of overfitting, as boosting can be quite sensitive to noise in the data.
Many of the parameters for boosting are tools for balancing the power versus the risk of overfitting. Sampling at each iteration (BigML’s ‘Ensemble Sample’), the learning rate, and the early holdout parameters are all tools to help find that balance. That’s why boosting has a lot of parameters and the need to tune them is one of the downsides of the technique. Luckily, we have a solution on the way. We’ll be connecting Boosted Trees to our Bayesian parameter optimization library (a variant of SMAC), and then we’ll describe how to automatically pick boosting parameters in a future blog post.
Another downside to Boosted Trees are that they’re black box. It’s pretty easy to inspect a decision tree in one of our classic ensembles and understand how it splits up the training data. With boosting, each tree fits a residual of the previous trees, making them near impossible to interpret individually in a meaningful way. However, just like our other tree methods, you can get a feel for what the Boosted Trees are doing by inspecting the field importances measurements. As part of BigML’s prediction service, not only do we build global field importance measures, we also report which fields were most important on a per-prediction basis.
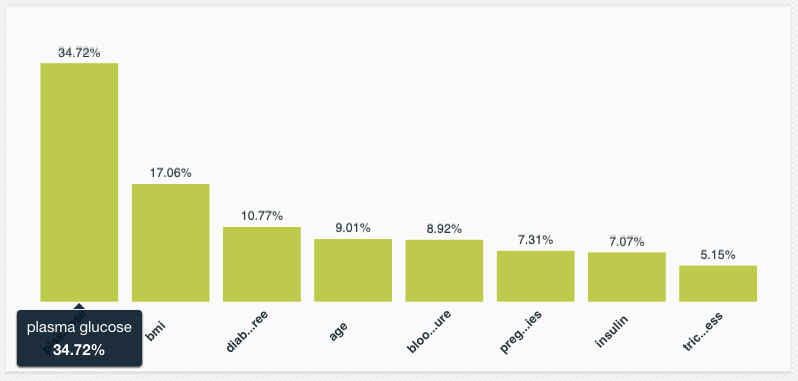
On the advantageous side, BigML’s Boosted Trees support the missing data strategies available with our other tree techniques. If you have data that contains missing values and if those have inherent meaning (e.g. someone decided to leave ‘age’ unanswered in a personals ad), then you may explicitly model the missing values regardless of the field’s type (numeric, categorical, etc.). But if missing values don’t have any meaning, and just mean ‘unknown’, you can use our proportional prediction technique to ignore the impact of the missing fields. This technique is what we use when building our Partial Dependence Plots (or PDPs), which evaluate the Boosted Trees right in your browser to help visualize the impact of the various input fields on your predictions.
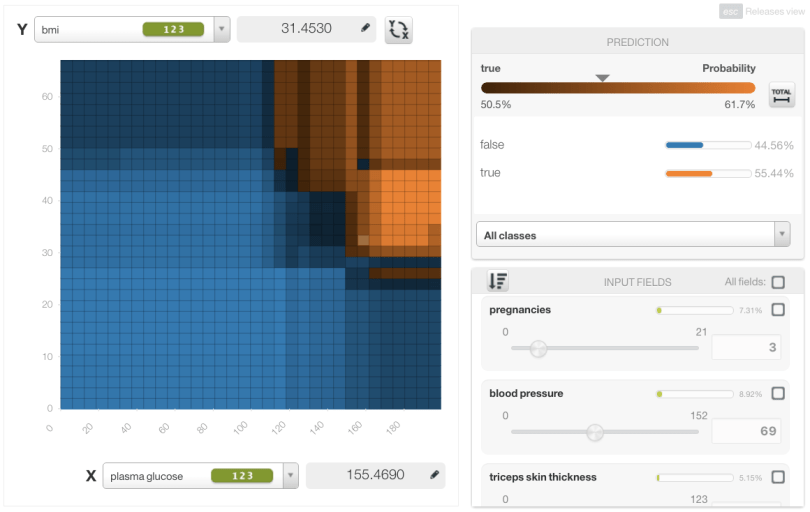
We think our Boosted Trees are already a strong addition to the BigML toolkit, but we’ll continue expanding the service to make it even more interpretable via fancier PDPs, easy to use with parameter optimization, and more powerful thanks to customized objective functions.
Want to know more about Boosted Trees?
We recommend that you visit the dedicated release page for more documentation on how to create Boosted Trees, interpret them, and predict with them through the BigML Dashboard and the API; as well as the six blog posts of this series, the slides of the webinar, and the webinar video.

One comment