There are so many Machine Learning algorithms and so many parameters for each one. Why can’t we just use a meta-algorithm (maybe even one that uses Machine Learning) to select the best algorithm and parameters for our dataset?
— Every first year grad student who has taken a Machine Learning class
It seems obvious, right? Many Machine Learning problems are formalized as an optimization wherein you’re given some data, there are some free parameters, and you have some sort of function to measure the performance of those parameters on that data. Your goal is to choose the parameters to minimize (or maximize) the given function.
But this sounds exactly like what we do when we select a Machine Learning algorithm! We try different algorithms and parameters for those algorithms on our data, evaluate their performance and finally select the best ones according to our evaluation. So why can’t we use the former to do the latter? Instead of stabbing around blindly by hand, why can’t we use our own algorithms to do this for us?
In just the last five years or so, there’s been a lot of work in the academic community around this very topic (usually it’s called hyperparameter optimization, and the particular type which is getting the attention lately is the Bayesian variety) which in turn has led to a number of open source libraries like hyperopt, spearmint, and Auto-WEKA. They all have loosely the same flavor:
- Try a bunch of random parameter configurations to learn models on the data
- Evaluate those models
- Create a Machine Learning dataset from these evaluations where the features are the parameter values and the objective is the result of the evaluation
- Model this dataset
- Use the model to select the “most promising” set of next parameter sets to evaluate
- Learn models with those parameter sets
- Repeat steps 2-6, adding new evaluations to the dataset described in set 3 at each iteration
Most of the subtlety here is in steps four and five. What is the best way to model this dataset and how do we use the model to select the next sets of parameters to evaluate?
My favorite specialization of the above is SMAC. The original version of SMAC is a bit fancier than is necessary for our purposes, so I’ll dumb it down a little here in the name of simplicity (let’s call the simpler algorithm SMACdown):
In step four, we’re going to grow a random regression forest as our model for the parameter space. Say we grow 32 trees: This means that for each parameter set we evaluate using our model, we’ll get 32 separate estimates of the performance of our algorithm. Importantly, the mean and variance of these 32 estimates can be used to define a Gaussian distribution of probable performances given that parameter set.
In step five, we generate a whole bunch of parameter sets (say, thousands) and pass them through the model from step four to generate a Gaussian for each one. We then measure, for each gaussian, how much of the lower tail is below our current best evaluation. The ones with the most area below this lower tail are our most promising candidates.
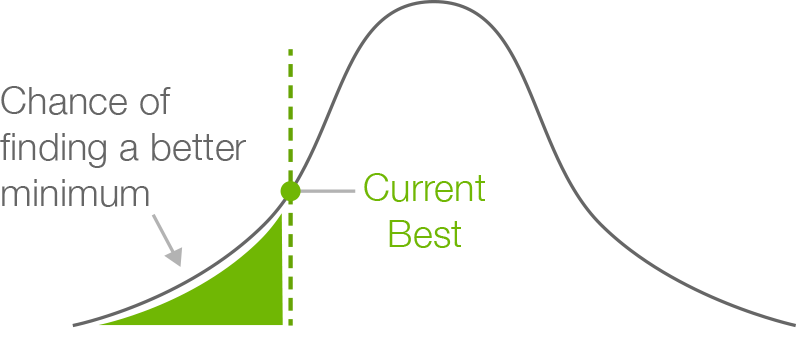
With most of the details settled, all that’s left is to choose a language in which to implement the algorithm.
How about WhizzML?
Why would we choose WhizzML? For starters, it allows us to kiss our worries about scalability goodbye. We can prototype our script on some small datasets, then run exactly the same script on datasets that are gigabytes in size. No extra libraries or hardware; it will just work out of the box.
Second, because the script itself is a BigML resource, it can be run from any language from which you can POST an HTTP request to BigML, and you can consume the results of that call as a JSON structure. With WhizzML, there’s no longer the necessity of working in a particular language; you can implement once in WhizzML and run from anywhere.
We aren’t going to go through all of the code in detail, but we’ll hit on some of the major points here.
Our goal here is going to be to optimize the parameters for an ensemble of trees. We’ll start by creating a function that generates a random set of parameters for an ensemble. That looks like this:

We use WhizzML’s lambda to define a function with no arguments that will generate a random set of parameters for our ensemble. Note that we need to know if this is going to be a classification or a regression in advance, as setting balance_objective to true for regression problems is invalid. This function returns a function that can be invoked over and over again to generate different sets of parameters each time.
The process of evaluating these generated parameter sets is fairly simple; for each parameter set you want to evaluate, you create an ensemble, perform an evaluation on your holdout set (you did hold out some data, didn’t you?), then pull out or create the metric on which you want to evaluate your candidates.
Once you have these evaluations in hand, you need to model them (step four). That’s done here:

Here, we make the random forest described above. The helper smackdown—data->dataset creates a dataset from our list of parameter evaluations. We then create a series of random seeds and create a model for each one, returning the list of IDs.
The next thing is to create a bunch of new parameter sets and use our constructed model to evaluate them:

The data argument here is our new list of parameter sets (created elsewhere by multiple invocations of the model-params-generator defined above), and mod-ids is the list of model IDs created by the smacdown--create-ensemble. The logic here is again fairly simple: We create a batch prediction for each model, then create a sample from each batch predicted dataset so we can pull all of the rows for each prediction into memory. We’re left with a row of predictions for each datapoint in data.
Another function is applied to these lists to pull out the mean and variance from each one, then to compute, given the current best evaluation, which of these has the greatest chance to improve on our current best solution (that is, which has the highest percentage of the area under its Gaussian below the current best solution).
There’s a number of details here we’re glossing over, but thankfully you don’t have to know them all to run the script. In fact, you can clone it right out of BigML’s script gallery:
What’s the takeaway from all of this? Mainly, we want you to see that WhizzML is expressive enough to let you compose even complex meta-algorithms on top of BigML’s API. When you choose to use it, WhizzML offers you scalability and language-agnosticity for your Machine Learning workflows, so that you can run them on any data, any time.
No excuses left now! Go give it a shot and let us know what you think at info@bigml.com or in the comments below.

One comment