Sure, you can use WhizzML to fill in missing values or to do some basic data cleaning, but what if you want to go crazy? WhizzML is a fully-fledged programming language, after all. We can go as far down the rabbit hole as we want.
As we’ve mentioned before, one of the great things about writing programs in WhizzML is access to highly-scalable, library-free machine learning. To put in another way, cloud-based machine learning operations (learn an ensemble, create a dataset, etc.) are primitives built into the language.
 Put these two facts together, and you have a language that does more than just automate machine learning workflows. We have the tools here to actually compose new machine learning algorithms that run on BigML’s infrastructure without any need for you, the intrepid WhizzML programmer, to worry about hardware requirements, memory management, or even the details of the API calls.
Put these two facts together, and you have a language that does more than just automate machine learning workflows. We have the tools here to actually compose new machine learning algorithms that run on BigML’s infrastructure without any need for you, the intrepid WhizzML programmer, to worry about hardware requirements, memory management, or even the details of the API calls.
What sort of algorithms are we talking about, here? Truth be told, many of your favorite machine learning algorithms could be implemented in WhizzML. One important reason for this is because many machine learning algorithms feature machine learning operations as primitives. That is, the algorithm itself is composed of steps like model, predict, evaluate, etc.
As a demonstration, we’ll take a look gradient tree boosting. This is an algorithm that has gotten a lot of praise and press lately due to it’s performance in general, and the popularity of the xgboost library in particular. Let’s see if we can cook up a basic version of this algorithm in WhizzML.
The steps to gradient boosting (for classification) are as follows:
- Compute the gradient of the objective with respect to the currently predicted class probabilities (which start out as, e.g., uniform over all classes) for each training point (optionally, on only a sample of the data)
- Learn a tree for each class as a functional approximation of this gradient step
- Use the tree to predict the approximate gradient at all training points
- Sum the gradient predictions with the running gradient sums for each point (these all start out as zero, of course).
- Use something like the softmax transformation to generate class probabilities from these scores
- Iterate steps 1 through 5 until a stopping condition is met (such as a small gradient magnitude).
You can see here that machine learning primitives feature prominently in the algorithm. Step two involves learning one or more trees. Step three uses those trees to make predictions. Obviously, those steps are easily accomplished with the WhizzML builtins create-model and create-batchprediciton, respectively.But there are a few other steps where the WhizzML implementation isn’t as clear. The gradient computation, summing of the predictions, and application of the softmax transformation don’t have (very) obvious WhizzML implementation, because they are operations that iterate over the whole dataset. In general, the way we work with the data in WhizzML is via calls to BigML rather than explicit iteration.
So are there calls to the BigML API that we can make that will do the computations above? There are, if we use Flatline. Flatline is BigML’s DSL for dataset transformation, and fortunately all of the above steps that aren’t learning or prediction can be encoded as Flatline transformations. Since Flatline is a first class citizen of WhizzML, we can easily specify those transformations in our WhizzML implementation.
Take step four, for example. Suppose we have our current sum of gradient steps for each training point stored in a column of the dataset, and our predictions for the current gradient step in another. If those columns are named current_sum and current_prediction, respectively, then the Flatline expression for the sum of those two columns is:
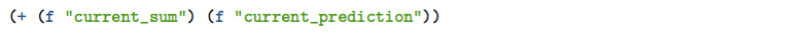
Where the f Flatline operator gets the value for a field given the name. Knowing that we have a running sum and a set of predictions for each class, we need to construct a set of Flatline expressions to perform these sums. We can use WhizzML (and especially the flatline builtin) to construct these programmatically:

Here, we get the names for all of the running sum, current prediction, and new sum columns into the the last-sums, this-preds, and this-sums variables, respectively. We then construct the flatline expression that creates the sum, and call make-fields (a helper defined elsewhere) to create the list of flatline expressions mapped to the new field names. The helper add-fields then creates a new dataset containing the created fields.
We can do roughly the same thing to compute the gradient and apply the softmax transformation; We use WhizzML to compose Flatline expressions, then allow BigML to do the dataset operation on it’s servers.
This is just a peek into what a gradient boosting implementation might look like in WhizzML. For a full implementation of this and some other common machine learning workflows, check out the WhizzML tutorials. We’ve even got a Sublime Text Package to get you started writing WhizzML as quickly as possible. What are you waiting for?
