I hope you’re as excited as I am to start using WhizzML to automate BigML workflows! (If you don’t know what WhizzML is yet, I suggest you check out this article first. In this post, we’ll write a simple WhizzML script that automates a dataset transformation process.

As those of you who have dealt with datasets in a production environment know, sometimes there are fields which are missing a lot of data. So much so, that we want to ignore the field altogether. Luckily, BigML will automatically detect useless fields like this and ignore them automatically if we create a predictive model. But what if we want to specify the required “completeness” of the data field? Like if we only want to include fields that have values for more than 95% of the rows.
We can use WhizzML!
Let’s do it! Look to the WhizzML Reference Guide if you need it along the way. Also, the source code can be found in this GitHub Gist.
We want to write a function that: given a dataset and a specified threshold (e.g., 0.95), returns a new dataset with only the fields that are more than 95% populated. Our top-level function is defined below.
filtered-dataset

Hey, slow down!
Ok. Let’s take it step-by-step. We define a new function called filtered-dataset that takes two arguments: our starting dataset, dataset-id and a threshold (e.g., 0.95).

What do we want this function to do? We want it to return a new dataset, hence:

But we don’t just want any old dataset, we want one based off our old dataset:

And we also want to exclude some fields from our old dataset!

Ah, but which fields do we want to exclude? We can let a new function called excluded-fields figure that out for us. But for now, all we need to know is that this new function (excluded-fields) takes two arguments: our original dataset and our specified threshold.
The line above becomes: (indentation removed for clarity)
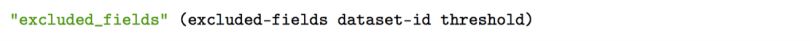
As we progress, keep in mind that we want this new function (excluded-fields) to return a list of field names (e.g., ["field_1" "field_2" "field_3"]).
Great! We have defined our base function. Now we have to tell our new function, excluded-fields, how to give us the list that we want.
excluded-fields

Wow what?
You can use that code for reference, but don’t be intimidated. We’ll go over each piece. First we define the function, declaring its two arguments: our original dataset, and the threshold we want to use.

Before we write any more code, let’s talk about the meat of this function. We want to look at all the fields (columns) of this dataset, and find the ones that are missing too much data. We’ll keep the names of these “bad” fields so that we can exclude them from our new dataset. To do this, we can use the function filter. It takes two arguments: a list and a predicate (a predicate is like a test) and will return a new list based on the predicate. In our case, the predicate is that the field has less than 95% of the rows populated.

The predicate should be a function that either evaluates to true or false based on each element of the list we pass to it. If the predicate returns true, then that element of the list is kept. Otherwise, it is thrown out.
We can define the predicate function using lambda.lambda is like any other function definition. We have to tell it the name of the thing we are passing into it

and also tell it what we are going to do with that thing.

In our case, we are checking to see if the threshold is greater than the amount of data present. We will keep the field-name(s) that do not have enough data. (Because remember, these are the fields that will be excluded from our new dataset.) Two things still missing from our filter.
all-field-names<percent-of-data-that-the-field-has>
How do we get these? The first isn’t too difficult because BigML Datasets have this information readily available. We just have to “fetch” it from BigML first.

and then specify which value we want to get.

Nice. To figure out what percent of the rows are populated for a specific field, we get to… Define a new function! But before we do that, let’s talk about some things we skipped over in our excluded-fields function. Here it is again, for convenience.

What is let?
let is the method for declaring local variables in WhizzML.
- We set the value of
datato the result of(fetch dataset-id). - We set the value of
all-field-namesto the result of(get data "input_fields") - We set the value of
total-rowsto the result of(get data "rows"). (We didn’t talk about this yet. It’s one of the values we need to pass to thepresent-percentfunction)
let is useful for a couple of reasons in this function. First, we use data twice. So we can avoid the repetition of writing (fetch dataset-id) twice. Second, naming these variables at the top of the function makes the rest much easier to read and comprehend!
So to wrap up this excluded-fields function, lets talk through what it does again.
First, it declares local variables that we’ll need. Then, we take the list of all-field-names and filter it based on a function that checks its “present percent” of data points. We keep the names of the fields that do not pass our predicate. Cool! Now we’ll go over that present-percent function.
present-percent

Ah. Not so bad. To calculate the percentage of data points that are present in a given field, we need a few things:
- The big collection of data from our dataset (
data). - The name of the field we are inspecting (
field-name). - The total number of rows in our dataset (
total-rows).
We’ll set another local variable using let and call it fields. This is another object containing data about each of the fields. We’ll be using it below.

Then, we divide the missing-count from the field by the total-rows. This gives us a “missing percent”.

We subtract the “missing percent” from 1 and that gives us the “present percent”!

But “missing-count” is another function!
Yes it is!
missing-count
missing-count takes two arguments. First, the name of the field we are inspecting (field-name) Second, the fields object we mentioned earlier. It holds a bunch of information about each of the Dataset fields. To get the count of missing rows of data in the field, we do this:

It lets us access an inner value (e.g., 10) from a data object structured like so:

And… That’s it! We have now written all the pieces to make our filtered-dataset function work! All together, the code should look like this:
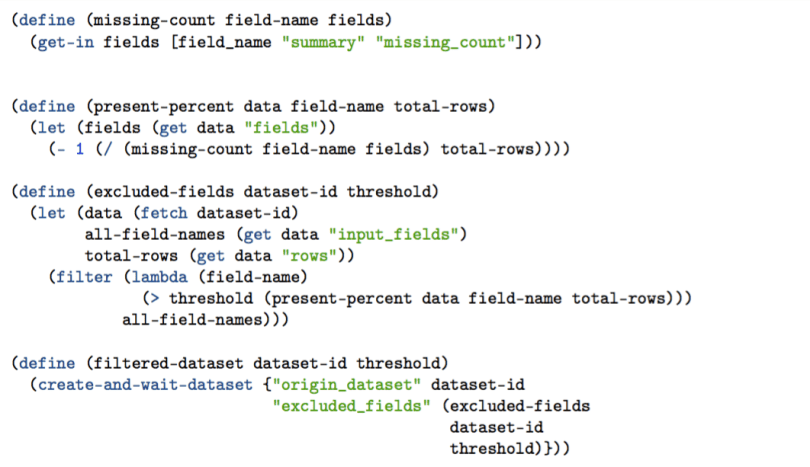
And we can run it like this:

And get a result like this "dataset/574317c346522fcd53000102"– a new dataset without those empty fields. I can add this script to my BigML Source dashboard and use it with one click. Or I can put it in a library, and incorporate it into a more advanced workflow. Awesome!
Stay tuned for more blog posts like this that will help you get started automating your own Machine Learning workflows and algorithms.
