One of the pitfalls of machine learning is that creating a single predictive model has the potential to overfit your data. That is, the performance on your training data might be very good, but the model does not generalize well to new data. Ensemble learning of decision trees, also referred to as forests or simply ensembles, is a tried-and-true technique for reducing the error of single machine-learned models. By learning multiple models over different subsamples of your data and taking a majority vote at prediction time, the risk of overfitting a single model to all of the data is mitigated. You can read more about this in our previous post.
Early this year, we showed how BigML ensembles outperform their solo counterparts and even beat other machine learning services. However, up until now creating ensembles with BigML has only been available via our API. We are excited to announce that ensembles are now available via our web interface and that they have also become first-class citizens in our API.
Creating Ensembles
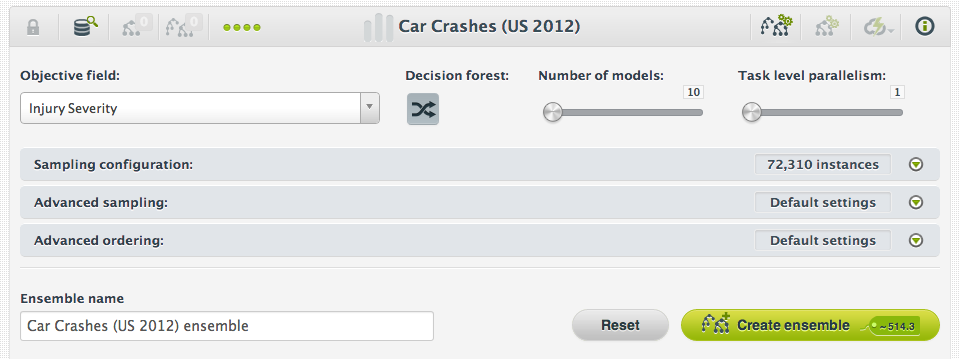
You can create an ensemble just as you would create a model, with the addition of three optional parameters:
- Whether your want fields to be selected randomly at each split (i.e., decision forest) or only bagging to be used.
- The number of models.
- The task level parallelism.
Decision Forest
A Decision forest or random decision forest is created by selecting a random set of the input fields at each split node while an individual model in the ensemble is being built instead of considering all the input fields. This is the strategy that BigML uses by default. If you just want to use bagging you should deselect this option.
Bagging
Bagging, also known as bootstrap aggregating, is one of the simplest ensemble-based strategies but often outperforms strategies that are more complex. This is the strategy that BigML uses by default. This method uses a different random subset of the original dataset for each model in the ensemble. By default, BigML uses a sampling rate of 100% with replacement for each model, meaning that individual instances can be selected more than once from the dataset. You can select different sampling rates using the sampling configuration panels.
Number of Models
The default is ten, but depending on your data and other modeling parameters you might want to use a bigger number. Generally, increasing the number of models in an ensemble lowers the effect of noise and model variability, and has no downside except the additional cost to you, the user. The cases where more models are likely to be beneficial are when the data is not terribly large (in the thousands of instances or less), when the data is very noisy, and for random decision forests, when there are many correlated features that are all at least somewhat useful.
Keep in mind that each additional model tends to deliver decreasing marginal improvement, so if the difference between nine and ten models is very small, it is very unlikely that an eleventh model will make a big difference.
Task Level Parallelism
The task level parallelism is the level of parallelism that BigML will use to perform a task that is decomposable into embarrassingly parallel tasks like building the models of a random decision forest. We offer five different levels. In the lowest, sub-tasks will be performed sequentially and in the highest level up to 16 sub-tasks will be performed in parallel. The higher the level, the faster your ensemble will be finished. However, the more credits it will cost you.
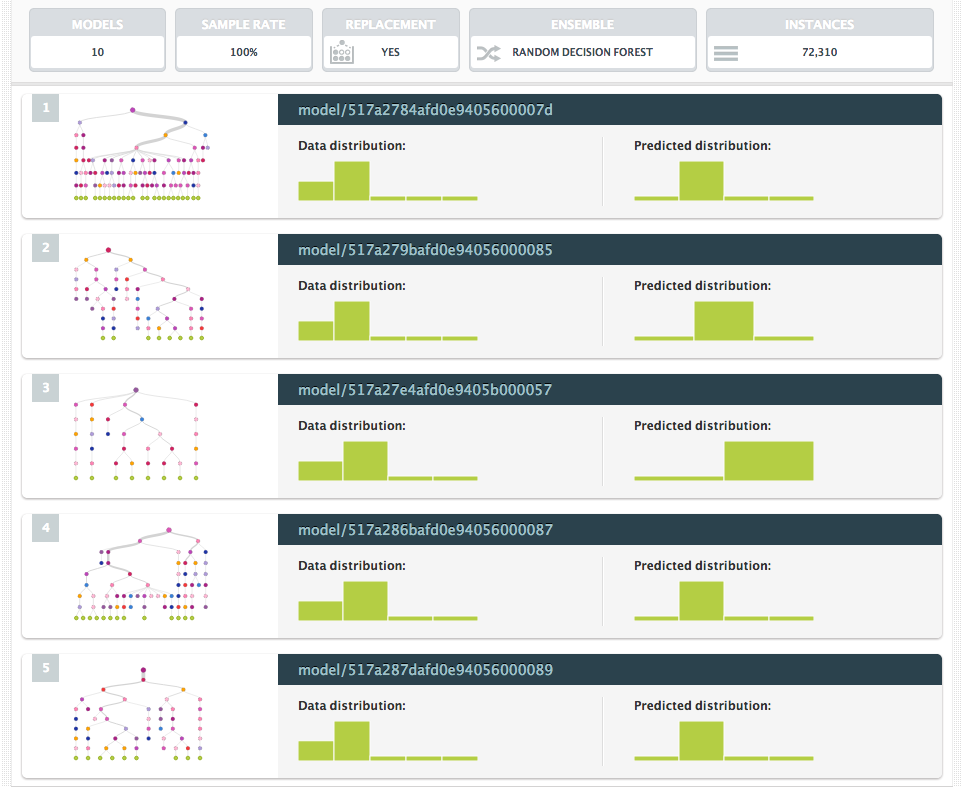
1-click Ensemble
You can also create an ensemble in just one click. By default, a 1-click ensemble will create a random decision forest of 10 models using 100% of the original dataset but sampling it with replacement.

Predicting with Ensembles
Once your ensemble is finished, creating a prediction is the same as creating a prediction with a single model, with one additional step; the predictions from the individual models of the ensemble must be combined into a final prediction. The default method for combining the predictions is pluarity vote for a classification ensemble and a simple average for a regression ensemble.
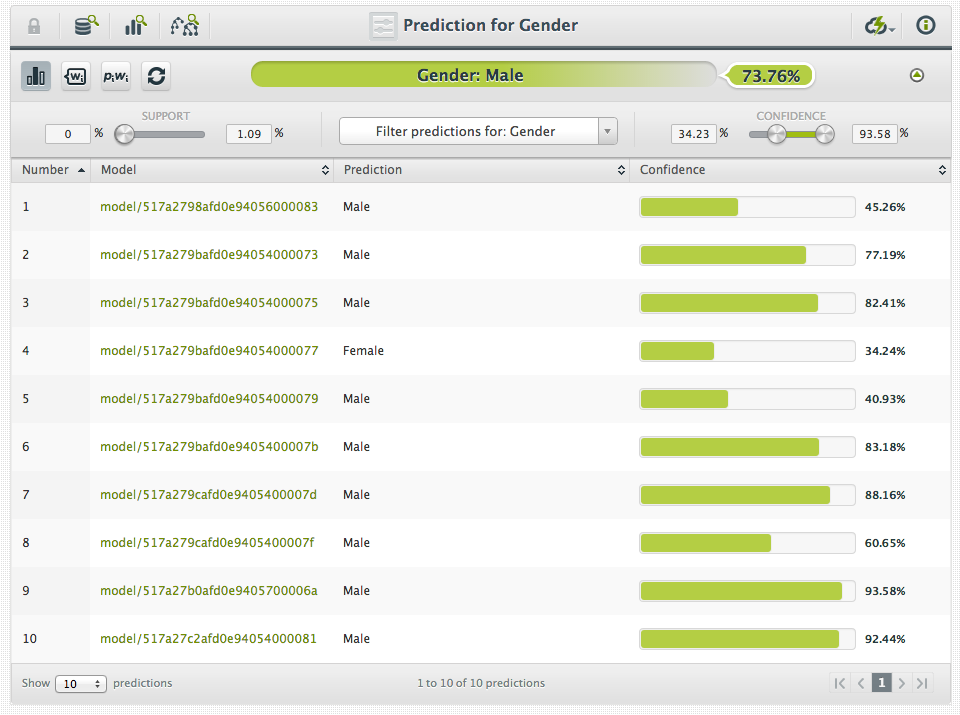
BigML offers three different methods for combining the predictions of an ensemble :
- Plurality – weighs each model’s prediction as one vote for classification ensembles. For regression ensembles, the predictions are averaged.
- Confidence Weighted – uses each prediction’s confidence as a voting weight for classification ensembles. For regression ensembles, computes a weighted average using the associated error as the weight.
- Probability Weighted – uses the probability of the class in the distribution of classes in the leaf node of each prediction as a voting weight for classification ensembles. For regression ensembles, this method is equivalent to the plurality method above.
Predictions take longer in ensembles than in single models, but you can also download ensembles using our download actionable ensemble button to perform low latency predictions directly in your applications. So far they are only available in Python but we’ll bring them to more programming languages soon. We also plan to bring high-performance predictions in an upcoming release, so stay tuned.
Evaluating Ensembles
You can also evaluate an ensemble in the same way as a single model.
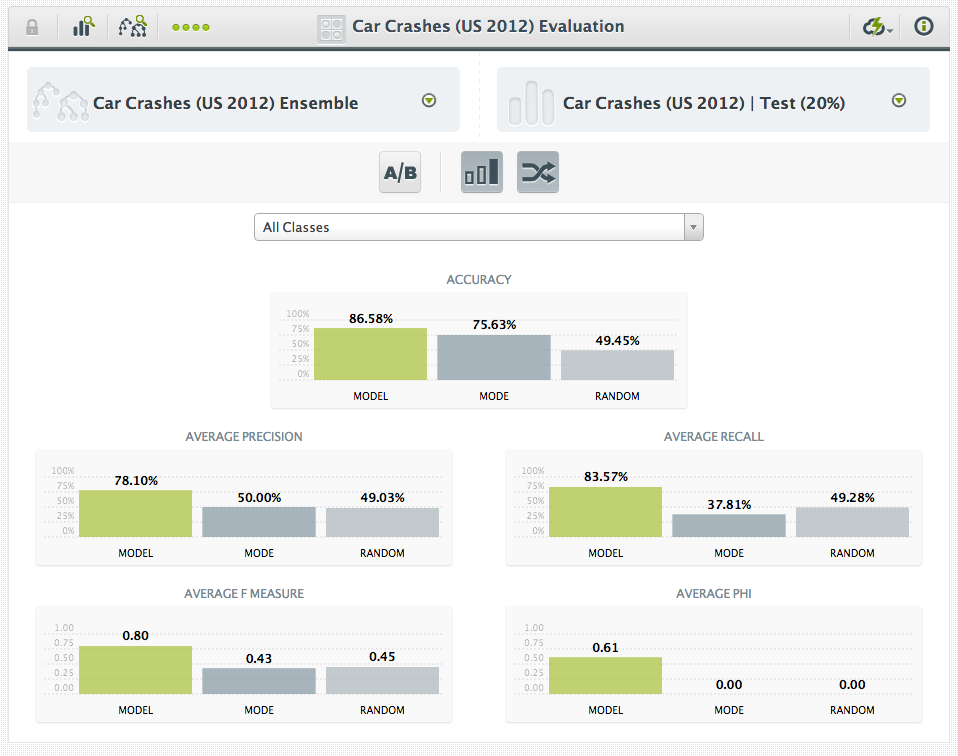
The level of accuracy achieved by ensembles of decision trees on previously unseen data very often outperforms most other techniques even if they are more sophisticated or complex. Not surprisingly, then, it is common to find random decision forests as one of the top performers in Kaggle’s competitions. Finally, ensembles of decision trees can be applied to perform a multitude of tasks such as classification, regression, manifold learning, density estimation, and semi-supervised classification in thousands of real-world domains. If you’re interested in a great monograph about random decision forests, we recommend this book.
We hope that you give BigML ensembles a try and let us know about your experience and results. Moreover, in this new release there are a number of small goodies like 1-click training|test split, alternative API keys to access to your BigML resources with different privileges, comparing evaluations, and many other things under the hood to make everything come together. We’ll explain it all in future blog posts!

Reblogged this on DECISION STATS.
Reblogged this on josephdung.