One of the great things about sports these days are the number of bright minds taking fresh looks at sports statistics and analytics. This has been particularly true in baseball, where there’s healthy debate between baseball Traditionalists (who favor subjective-based scouting reports and place value on traditional statistics like Home Runs, Wins, etc) and “Sabermetricians” (who favor advanced statistics—many of which were created by Nate Silver), with more and more credence being lent to analytic-driven decisions for roster composition, player salaries and the like. The Sabermetrics approach to baseball is well-documented in “Moneyball” and throughout the baseball blogosphere.
Football (the American variety) also has a burgeoning statistical community, and Football Outsiders is one of the leaders in this arena. At the core of their approach is their proprietary Defense-adjusted Value Over Average (DVOA) system that breaks down every single NFL play and compares a team’s performance to a league baseline based on situation in order to determine value over average—which they explain in detail here. Another example of cool football analytics in action is this report by Lock Analytics on how to use Random Forests to estimate a game’s win probability on a play by play basis.
What was the objective of the model?
With the Super Bowl being right around the corner, we thought it would be interesting to work with some of Football Outsiders’ historical data plus key football gambling metrics to see if we could come up with predictions for the big game.
What is the data source?
We used a few sources to create a dataset for this project. First and foremost, we pulled statistical data from Football Outsiders. Then, to get some added context on the Super Bowl for some of the betting metrics, we pulled historical scores, point spreads and over/under totals from Vegas Insider.
What was the modeling strategy?
As stated, we combined Football Outsiders’ DVOA-driven analysis with historical betting statistics, with the objectives being to predict the NFC (Seattle Seahawks) and AFC (Denver Broncos) total points. However, since there were only relevant statistics from the past 25 seasons we had a pretty small dataset. As such, we decided to build a 100-model ensemble in order to gain a stronger predictive value.
What fields were selected for the ensembles?
We used AFC & NFC Efficiency—both weighted (factoring in late-season performance) and non-weighted; AFC & NFC Offensive & Defensive ranks (weighted & non-weighted), AFC & NFC Special Teams ranks, the point spread, and the over/under total. We also included historical points scored for both the AFC & NFC team from past Super Bowls. You can view and clone the full dataset that we built here, although you’ll have to deselect some of the fields if you want to replicate this specific ensemble.
What did we find?
Using the Prediction function within the BigML interface, we entered the key values for this season to predict both AFC and NFC points (pictured below)
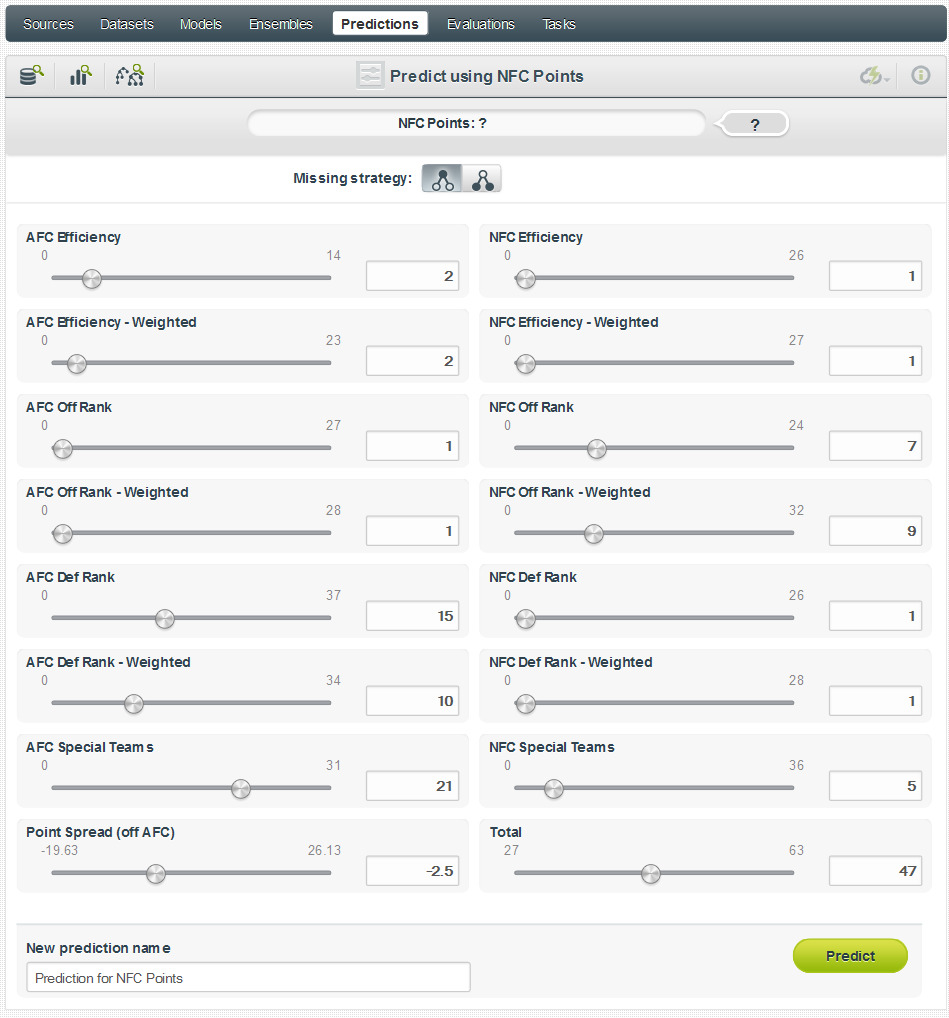
And the winner is..:
As you can see below, the result of our prediction is NFC 26.38 (with error ±4.95), AFC 22.16 (with error ±2.20). This reflects a prediction using confidence weighting for the ensemble. If we use a plurality-based prediction the result is NFC 29.93 (±13.74), AFC 23.97 (±6.0).


Incidentally, we also ran a categorical ensemble to simply predict the winner (NFC/AFC), and that ensemble also pointed to a Seahawks’ victory, with ~76% confidence. Another ensemble predicting the winner against the spread showed Seattle with a ~72% confidence.
Important Caveats:
But before you Seattle denizens start planning a victory parade through the Emerald City, please bear in mind a few things:
- These ensembles were built from small datasets so treat the results with a grain of salt. In other words, don’t wager your mortgage on 24 rows of data.
- Factoring in the expected error (which reflects our 95% confidence threshold), Denver could still win.
- This blog was authored by a lifelong Seahawks fan.
Last but not least, do not forget the greatest football variable of all, which a wise data analyst recently described to me as the “Any Given Sunday” coefficient…

2 comments