As faithful BigML blog readers will recall, last year we used the BigML platform to build a variety of analyses to predict the outcome of Super Bowl XLVIII. You can read full details here, but a short summary is this:
- The Denver Broncos were favored to beat the Seattle Seahawks by 2.5 points
- BigML predicted the Seahawks not just to cover the point spread, but also to win the game outright
- BigML also predicted that Seattle would win by the exact score of 43-8
Well, the last point isn’t true but the first two are. We weren’t the only machine learning or analytics vendor aiming to pick the Super Bowl. SAP took at crack at it (perhaps they should stick to futbol), as did a Microsoft researcher, as did Facebook. The difference between these predictions and our own is that our prediction was not only bolder (by picking not only against the spread but also an outright Seattle victory), but it was accurate.
But rather than gloating at being 1-0, let’s advance to 2015 and take another crack at the Big Game.
Our data source and approach:
We used team rankings data again from Football Outsiders, which features their DVOA (Defensive-adjusted Value Over Average) system. I like DVOA as it’s a more advanced way of judging a team’s performance. Football Outsider’s very short summary of DVOA is “DVOA measures a team’s efficiency by comparing success on every single play to a league average based on situation and opponent” — so rather than just looking at raw statistics, we have a much more nuanced basis. This is especially critical since we’re working with a narrow range of features in addition to a ridiculously small number of data points.
If you’re interested in learning more about the DVOA approach (and to get a snapshot in the type thinking behind advanced sports analytics in general), this summary from Football Outsiders is a great read.
What fields were selected for the ensembles?
We used Football Outsider’s NFL-wide rankings for Team Efficiency–both weighted (factoring in late-season performance) and non-weighted; Team Offense & Defense ranks (weighted & non-weighted), Special Teams ranks, the point spread, and the over/under total. We also included historical points scored for both the AFC & NFC team from past Super Bowls. You can view and clone the full dataset that we built here, although you’ll have to deselect some of the fields if you want to replicate this specific ensemble.
The same caveats as last year pertain — namely that these predictions are based on a mere 25 rows of data and are only using aggregate season rankings for team performance, whereas professional handicapping systems will incorporate much more nuanced data. If you want to get a professional’s point of view, you can check out the Prediction Machine or many other pundits who leverage machine learning to try and beat the odds and/or help out your average wagering enthusiast.
Evaluating our models:
As the data is so limited it’s not surprising that single models for any outcome evaluated poorly — we had to build 100-model ensembles to achieve evaluations that performed better than mode or random guessing. Even then, it’s important to note that the hold-out set (using a standard 80/20 train/test split) only has a handful of instances. I was curious to see how my evaluations stacked up, so I used BigML’s handy new tweak to the interface that allows you to sort evaluations by their performance (I also leveraged the search feature to filter for “superbowl ensemble”):
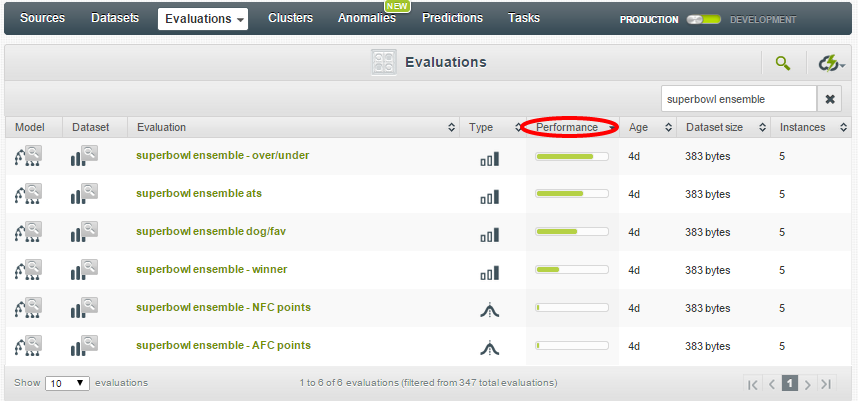
Cut to the chase: who’s going to win?
Noting our prior caveats regarding sample size and mixed evaluations, here are our predictions against the 100-tree ensembles for each bet (all using plurality weighting):
- NFC (Seattle Seahawks) points: 39.37 ±14.6
- AFC (New England Patriots) points: 19.41 ±6.83
- Outright Winner: Seattle Seahawks (73.13% confidence)
- ATS (Against the Spread) Winner: Seattle Seahawks (66.30% confidence)
- Underdog/Favorite prediction: Underdog (Seahawks) (61.33% confidence)
- Over/under 49 prediction: Over (69.51% confidence)
There you have it: Seattle will beat the odds again and in taking home the championship will become the first repeat Super Bowl champions in a decade. It also looks to be a high-scoring affair, although the NFC total is undoubtedly skewed by the 43 points Seattle put up last year.
What to do now?
So should you run to your local betting hall or online sportsbook and bet your life savings on the Seahawks? Of course not — at least not based on this blog post. As stated above, these Super Bowl models have been built with very limited data, and perhaps have been subconsciously biased by the author’s Seahawks fanship. Last but not least, there’s the Beli-cheat / Deflate-gate factor — who knows what’s going to come from the team that has pushed all limits in the name of securing victories?
What we’d love to see you do is leverage BigML to build your own predictive model for the Super Bowl. For example, you could access data on all past games (not just super bowls) and use BigML’s clustering algorithm to find most similar matchups and then make a prediction based on those results. Or, you can simply access more data — factoring in games beyond the super bowl, but also more advanced statistics from outcomes on team trends, match-up trends (e.g., what happens in *any* game when the top-ranked defense faces the 5th ranked offense), individual player match-ups, etc. Are you into the “wisdom of crowds”? Pull social media data and leverage BigML’s text analysis to see what the general public is thinking.
Interested? We’re happy to help you out with your efforts. For starters, we’ll give you a free one-month Pro subscription – simply enter coupon code “XLIX” in the payment form. Stumped? You can always send us email at info@bigml.com, or join our weekly “Meet the Team” hangout next Wednesday at 9:30 AM Pacific.
No matter if you’re wagering or simply cheering for one team or the other, we hope you enjoy the Super Bowl.
