Can you make smarter decisions by ignoring data? It certainly runs counter to our mission, and sounds a little like an Orwellean dystopia. But as we’re going to see, ignoring some of your data some of the time can be a very useful thing to do.
Suppose you’ve got a dataset with a single attribute, let’s say the diameter of a piece of fruit (in centimeters, say) along with its name:
| Diameter (cm) | Fruit |
|---|---|
| 3 | Plum |
| 4 | Plum |
| 4 | Plum |
| 5 | Apple |
| 5 | Apple |
| 5 | Apple |
| 6 | Plum |
| 7 | Apple |
| 8 | Apple |
| 9 | Apple |
In this dataset, it’s pretty clear that apples are in general five centimeters or larger in diameter and plums are four centimeters or less in diameter. If you built a BigML model with this data, it would reflect this knowledge, creating the first split at “diameter <= 4”.
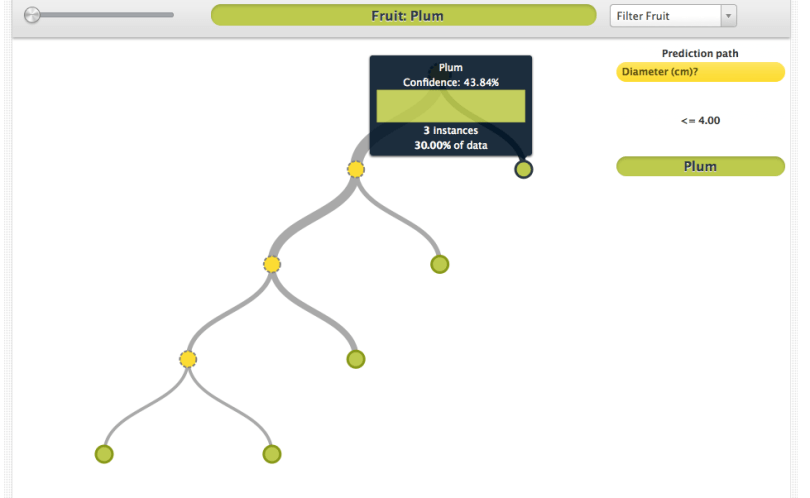
But what about that huge plum? It’s pretty obvious from the dataset that the plum is an outlier among plums. Furthermore, it’s unlikely that there are apples that are five centimeters in diameter, and apples that are seven or more centimeters in diameter, but all fruits that are six centimeters in diameter are plums. Yet, your dataset reflects exactly this fantasy. So, of course, your BigML model will reflect it, too. You’ll see a series of nodes that together label all of the fruits between 5 and 6 centimeters as plums.
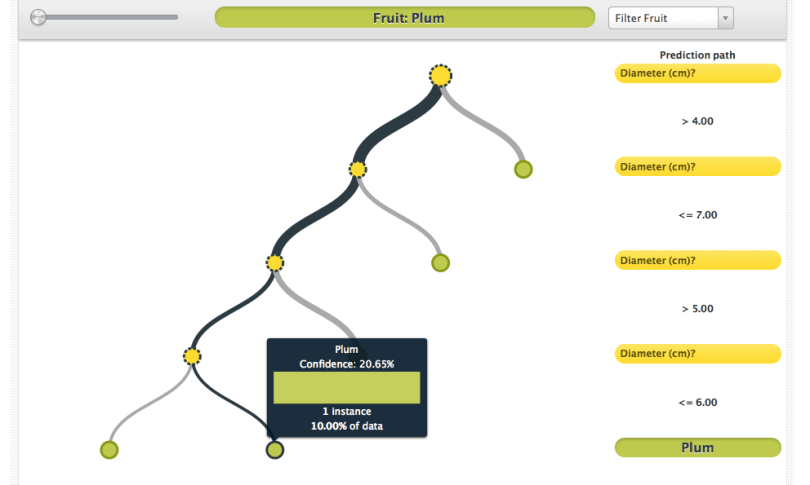
In this case, you can get rid of the errant plum nodes by… pruning (cue boos from the audience). But in some cases, with more data, you can have aberrations that look for all the world like legitimate inferences. These can be awfully difficult to know when to prune away. So is there nothing to be done?
Ignorance is Intelligence
Fortunately, there is a way out of this hot mess, and it comes in the form of bootstrap aggregation or bagging as it is known in the biz. The basic idea is this: We’re going to create not just one, but many models on this dataset. Then, when we want to make a prediction, the models will all vote on the correct outcome.
“But why”, asks the astute reader, “would a group of models all trained on the same dataset ever give different votes?” And therein is the catch: Because you’re only going to train each one on a random subset of the data. Because each model only knows about part of the data, their votes may be slightly different.
How will this effect the problem above? Depending on the size of the subset, that huge plum may not appear in the data. Thus, a majority of the models may not have the splits associated with the plums, and six centimeter fruits will be classified as apples. In practice, we typically use the majority of the data in each subset, so the majority prediction for a four centimeter fruit will still be plum on average, but if you look at the votes of the individual models, the majority will be quite weak.
What we’ve done in theory is reduced the variance of the classifier. This means that we can change the training dataset in small ways (adding the occasional giant plum or tiny apple) without changing much the performance of the trained classifier. Normally, tree models are fairly high variance classifiers, but by bagging them we can make them much more robust to noise and outliers.
There are also several variations on this theme. Random forests ignore some of the *fields* as well as some of the instances. Boosting attempts to learn from the mistakes of previously learned models. Bayesian model combination attempts to weight the models’ votes in a way that accounts for things like totally unreliable or redundant models. Rotation forests consider splits on combinations of features.
Lack of Knowledge is Power
This is just one example of how ensembles of classifiers can reduce error in your learning problem. We’ve focused on the example of a single anomalous training instances, but there are myriad other problems that can be solved by simply learning many models and ignoring some of the data to some degree.
There are fairly deep mathematical reasons for this, and ML scientist par excellence Robert Shapire lays out one of the most important arguments in the landmark paper “The Strength of Weak Learnability” in which he proves that a machine learning algorithm that performs only slightly better than randomly can be “boosted” into a classifier that is able to learn to an arbitrary degree of accuracy. For this incredible contribution (and for the later paper that gave us the Adaboost algorithm), he and his colleague Yoav Freund earned the Gödel Prize for computer science theory, the only time the award has been given for a machine learning paper.
In fact, the general idea turns out to be one of the most powerful in machine learning in practice as well as in theory. Studies show that ensembles of trees are, performance-wise, one of the best if not the best general purpose supervised classification algorithm. The folks at Kaggle have also noticed recently that random forests do an excellent job in most of their competitions.
I Want To Do It!
You can, with BigMLer, the command line interface to BigML. With just one simple command, you can build a random decision forest, where each model will be trained on a subset of the data.
bigmler --train data/customer.csv \
--test data/new_customer.csv \
--number_of_models 10 \
--sample_rate 0.75 \
--replacement \
--randomize \
--tag customers2011
It’s also easy to make voted predictions on a file of test data, if you’ve tagged the models:
bigmler --model_tag customers2011 \
--test data/new_customers.csv
What is there to lose? Well, for one thing, you’ve lost some interpretability. Your beautiful decision has been replaced by a collection of decisions, which is a little harder to visualize, specially if you’ve made a lot of models. However, if you have a very performance sensitive application, it’s probably worth it.
So go ahead and register for BigML and get your Johnny Appleseed on. Grow some forests and make some great predictions!

8 comments