You may have noticed, especially if you are an API user of BigML, that we now report an “importance” value for each of the fields in your model. The general idea here is that we are telling you how important some fields are relative to all others. The numbers you see always sum to one, so these numbers won’t generally be smaller for trees with less predictive power; it is only a measure of relative importance.
Naturally, you may be wondering how these numbers are computed. Have we made some sort of deal with the devil to fulfill our hedonistic desire for ever more elaborate statistics about your data? Not quite; these values are a product of fairly simple mathematics.
A Field of No Importance
Suppose you have the synthetic dataset below. Each instance is a person, and we know their age, gender, and whether or not theirs is the primary income in their household (labeled “Head of Household” for lack of a better term):
| Age | Gender | Head of Household |
|---|---|---|
| 25 | Female | Yes |
| 25 | Male | No |
| 26 | Male | No |
| 28 | Male | No |
| 27 | Female | Yes |
| 35 | Female | Yes |
| 35 | Male | No |
| 40 | Female | No |
| 40 | Male | No |
| 50 | Female | No |
| 50 | Male | No |
| 60 | Female | No |
| 60 | Male | Yes |
| 65 | Female | No |
| 65 | Male | Yes |
You’ll notice that neither of the first two fields are very predictive of the third. Many men are heads of household, as are many women. Many older folks are heads of their household, as are many younger folks. As you’d expect, the first split in the tree we learn over this dataset is not very informative.
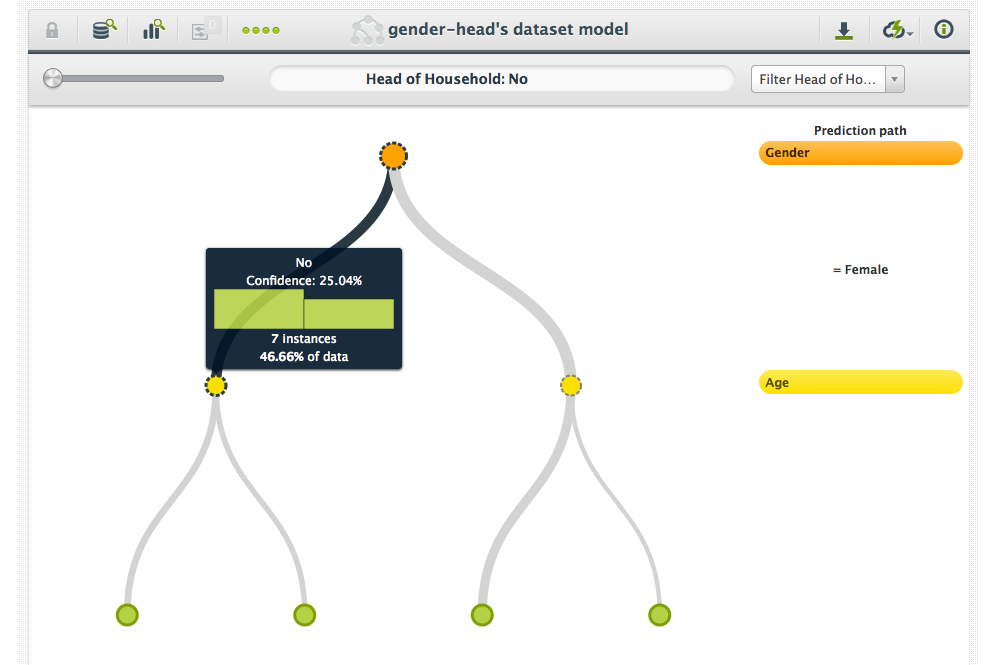
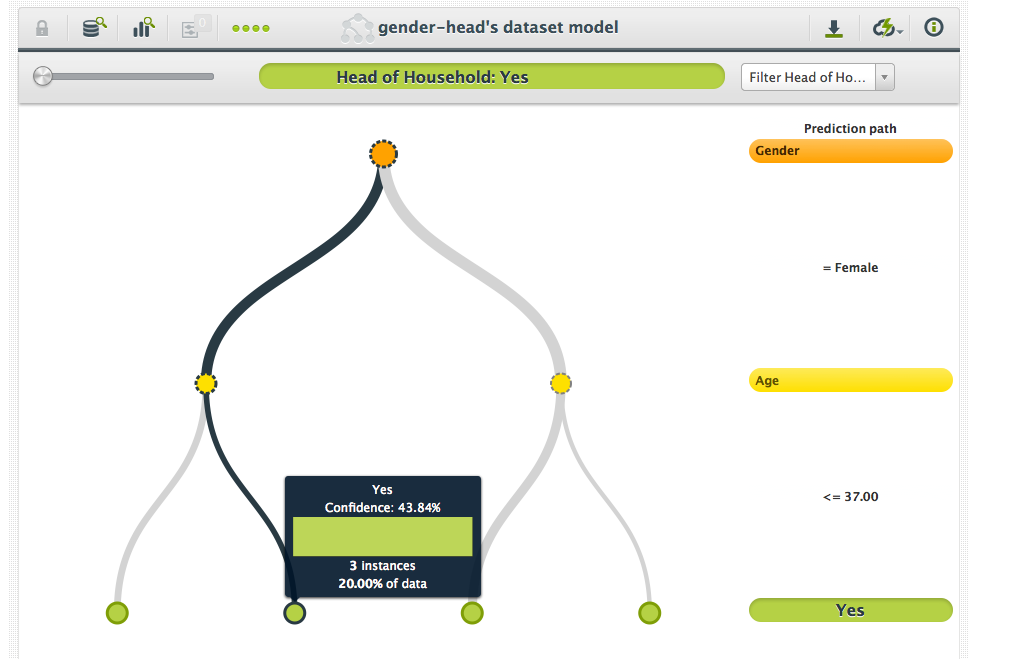
The second split, however, is a different story. Having separated the data into males and females, it becomes obvious that age is the important factor. The younger women are more likely to be heads of their household and the older men are also likely to be heads of their household. In fact, if we take into account age after gender, we can classify all of the data perfectly.
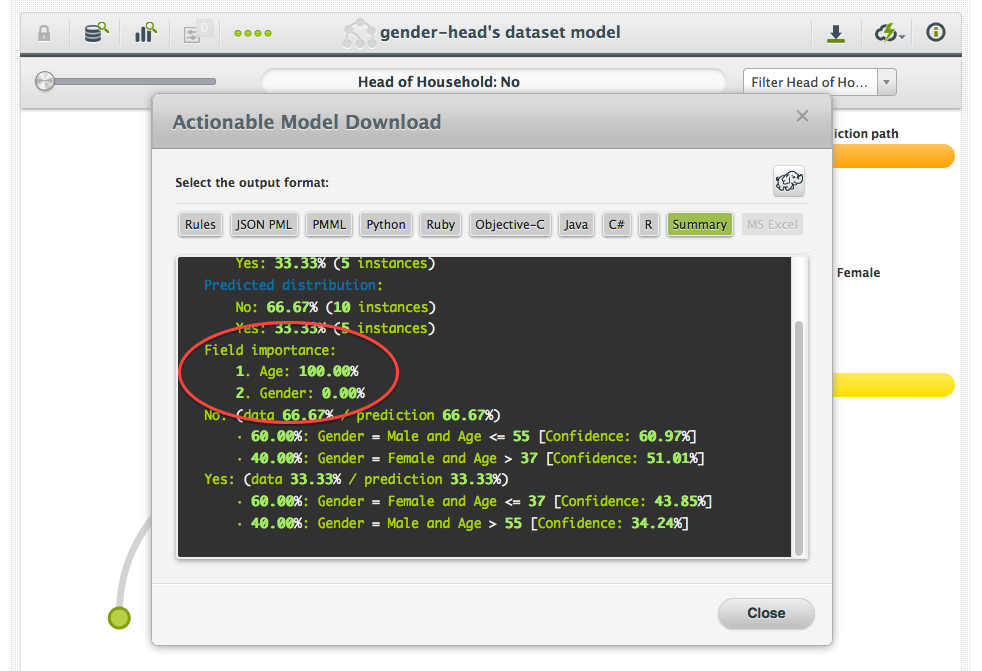
When we calculate importance values for each field in the dataset, we do it based on the amount that classification improved from parent to child. So if we could not classify very accurately in the parent node, but could in the child node, the field on which we split must be very important. If both child and parent accuracy is either good or poor, the split didn’t do us any good, and so we say that the field on which we split wasn’t very important.
Take the dataset above, for example: The first split did not give us much benefit. If we had to classify on the first split alone, the potential of making a mistake would be quite high. Thus, the first split tells us that gender is not very important. However, after the second split we are able to classify all of the data perfectly. Because the error after the first split was fairly high, and the error after the second was very low, the age field must have been very important.
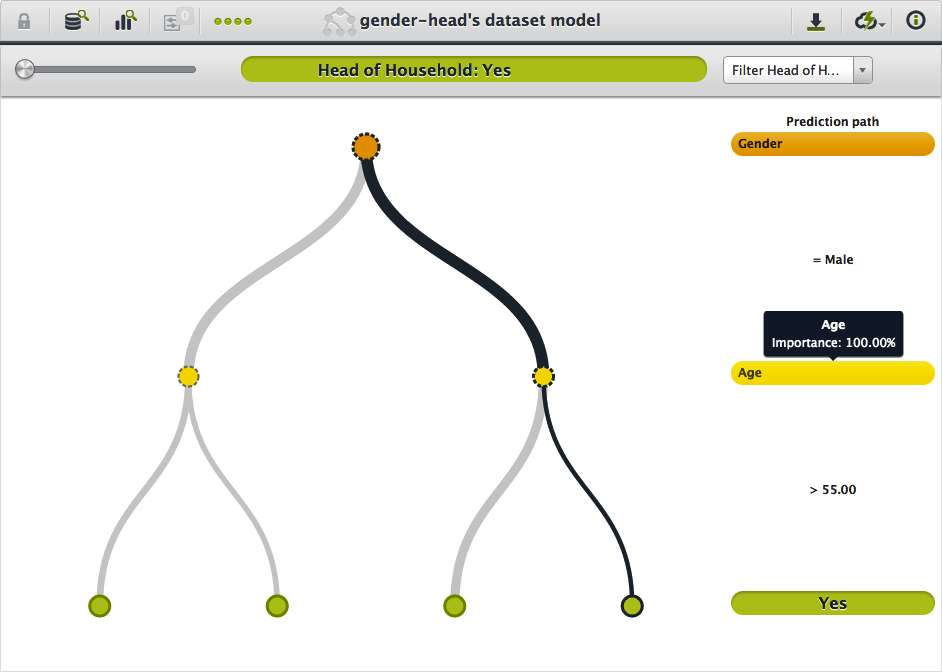
You can also find this field importance when you hover over a field in the prediction path. For instance, we can see the same high importance for the age field in determining the head of household (although not necessarily for determining An Ideal Husband).
Problemas, Postulates, y Preguntas
Conceptually, our measure of importance is based on the Gini Importance used for random forests. Because we only have one tree, the measure can occasionally be a bit misleading. For example, some skeptical readers may point out that in our example above, gender is still important. This is absolutely true. The trees that BigML grows represent only one possible explanation of the data. The values that we give for importance assume that the structure of the tree is correct. So, assuming that we look first at gender and then at age, age is the more important of the two attributes.
Another question might be regarding the case where we split more than once on a given field. This is taken into account in our importance calculation; the field importance is an aggregate of all of the accuracy improvements from all of the splits that use that field.
We’re always working hard to make our models more useful and understandable. If you have an idea of how we can improve them further, drop us a line and let us know!
