Before your sunburns subside and the leaves begin to turn from green to brown, the BigML team is excited to share our Late Summer Release which includes a bunch of new functionality to empower many new predictive applications.
Headlining this release is Anomaly Detection, which can help automate a number of predictive tasks for fraud detection, security, quality control, diagnoses and more. Also included in the release are support for model clusters, missing splits, client-side predictions and more!

For starters, we’re excited to announce that BigML now allows you to automatically create top performer Anomaly Detectors in just one click, or programmatically via BigML’s REST API.
An anomaly detector is a predictive model that can help identify the instances within a dataset that do not conform to a regular pattern. This can be useful for tasks like data cleansing, identifying unusual instances, or, given a new data point, deciding whether a model is competent to make a prediction or not. Thus anomaly detectors are not only critical tools to work on fraud detection, medical diagnosis, or preventing defects but also they do a great job removing outliers, which in turn helps increase performance of other modeling tasks.
When you create a new anomaly detector, it automatically returns an anomaly score for the top n most anomalous instances. The newly created anomaly detector can later be used to create anomaly scores for new data points or batch anomaly scores for all the instances of a dataset.
BigML anomaly detectors are built using an unsupervised anomaly detection technique that helps isolate those instances that are unusual, and you do not need to explicitly label each instance in your dataset as “normal” or “abnormal.” We’ll be explaining the technique further in blog posts soon and also will be layering in added functionality (e.g., the ability to work with text fields). You can get started today with just about any dataset—and as always, you can work for free in BigML’s Development Mode!

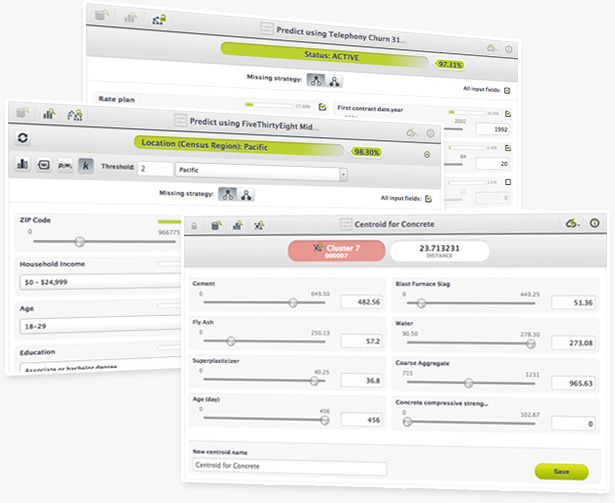
Model Clusters
Now you can automatically create a dataset and model for each cluster. This will not only help you better understand the cluster, but you can also use model clusters to classify new instances.
To use this functionality, be sure to click the “create model clusters” option when configuring your cluster. Then, if you want to build a model from one of your clusters, simply hit ‘shift’ on any cluster and then choose ‘create a model of this cluster” from beneath the right-hand summary box.

And, voila—you’ll have a new model comprised of your cluster’s data, which you can then interpret to find key patterns associated with whether or not data is likely to be within that cluster. Check this section out to learn how to use this feature via BigML’s API.
Missing Splits
As we know that cleaning up data can be hard and having all the input data handy at prediction time is important, we have built a new option to create models that will generate predicates that explicitly deal with missing values.
To leverage this capability, go into the “Configure” subpanel when configuring your model, and click on the “missing splits” icon as follows:

The model that is created will look the same as before, but now you can see new predicates that directly check for missing values. See the example in the picture below.

Online Predictions
New client-side predictions make it easier than ever to explore the influence of each field in your models, ensembles or clusters. Whereas you previously had to rebuild predictions for each set of variables, you can now simply change your fields’ inputs and see the predicted output change in realtime! In addition, the prediction form also includes the relative importance of each field so you can quickly select / de-select them for your predictions:
Some added benefits of online predictions are that they’re free to use–both for pay-as-you-go customers, and also for anyone predicting against a model that’s been shared in BigML’s gallery and/or through a private link.
Also, we are open sourcing the related Javascript libraries so that you can easily leverage this functionality to build very powerful and dynamic apps and web services.
Faster Ensembles
As you already know, ensembles provide greater generalization than single decision trees, and BigML makes it easy for you to tap into this functionality with just a few mouse clicks.
With our latest release, BigML’s ensembles now run much faster than before–meaning that you can more quickly build fully actionable ensembles to underpin predictive analyses and applications. Basically, we have reengineered the way ensembles deal with all the data processing that BigML needs before creating a model.
And More..
You’ll also notice a bunch of UI and workflow improvements, which we’re constantly bringing into production. These typically have a “new” image next to them. One of the features that we like most is the new option to automatically generate a dataset using the output of of batch process. That is, when you request a batch prediction, a batch centroid, or batch anomaly score you can optionally request to build a new dataset with the results. This is particularly useful to implement iterative flows where you use the output (prediction, centroid, or score) as an additional input for building another model. We’ll elaborate more on this in a future blog post.
The Late Summer Release features are available immediately–simply log into your account and get started today! And be sure to let us know your feedback both on these features, and on what you’d like to see next!
Interested in seeing these new features in action? Check out the archived video and slides from our Late Summer Release launch webinar.

Loving this anomaly detection release BigML, keep up the good work. Thanks.