In our recent series of blog posts on Topic Models, we’ve tried to explore this powerful new resource in the BigML Dashboard, in the API, using WhizzML, and we have also suggested some uses for it. But we’ve left a nuts and bolts description of how Latent Dirichlet Allocation (LDA) works until the end. Within this post, the last of a series of six posts, we’ll try here to give you exactly that: A high-level overview of the internal mathematics that underlies Topic Models, and what that mathematics might imply for you, the modeler.
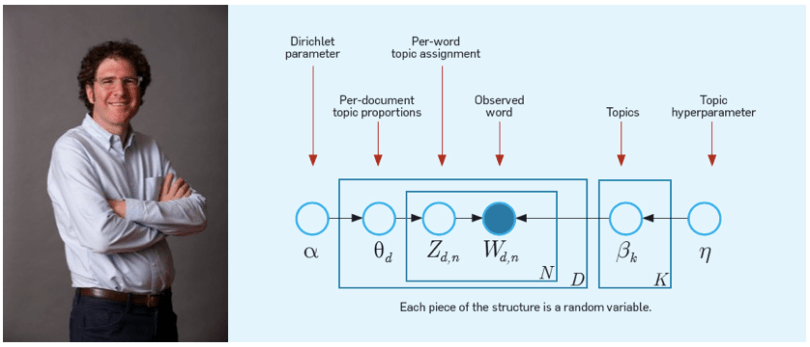
While I’ll explain a few things here, a more precise and technical explanation given by the inventor of the technique, David Blei, is available. Where there seems to be conflict between his explanation and mine, rest assured, his is correct!
My Generation
A crucially important aspect of the topic models learned by Latent Dirichlet Allocation is that they are generative models. This is different from many of our models at BigML. Decision trees and logistic regressions are discriminative models. This means essentially that they spend their effort using the data to model the boundary between classes, directly approximating the function of interest without much concern about exactly why the data is the way it is.
Generative models are a bit different. Typically, generative models posit a statistical structure that is said to have generated the data. The modeling process is then a process of using the data to fit the parameters of that structure so that the structure is likely to have generated the data that we see.
More concretely, Latent Dirichlet Allocation imagines that each document is a distribution over topics in your dataset, like {Topic 1: 0.8, Topic 2: 0.0, Topic 3: 0.1, Topic 4: 0.1}. Each of those topics, as we know, is a distribution over words, like {President: 0.5, united: 0.25, states: 0.25}. Now, to generate a document from that topic distribution, we first choose a random topic according to those probabilities (so we’d be very likely to choose topic 1, unlikely to choose topics 3 or 4, and would never choose topic 2). Once we’ve chosen our topic, we choose a word from that topic (so we’d choose “President” with high probability, and “united” or “states” with lower probability). That gives us a single word in our document. Then we repeat the process over and over again until we have however long of a document we’d like. Et Voilà, we’ve generated a document from a topic distribution!
The astute reader will notice we’ve glossed over where the topic distribution for our document came from. There’s actually another meta-distribution from which we choose these topic distributions. So each document in our collection is a random choice of a topic distribution from the overlying distribution over topic distributions. With that, we’ve got a structure that could possibly generate our entire document collection, if all of those distributions are just right.
Another Tricky Day
As we mentioned earlier, learning proceeds in a somewhat backwards way from how we think about the generative structure: That is, the model gives a a procedure to generate documents given the distributions, but we already have the documents and need to infer the parameters of the model that probably generated them.
This is a tricky proposition so I won’t bore you with the details, but there are techniques like collapsed Gibbs sampling and variational methods that allow you to do this sort of “reverse inference” in generative models, and that’s exactly what we use in practice for our Topic Models.
The Seeker
So how can this knowledge affect the way you use BigML topic models? One of the key things to remember when using Topic Models is that the learning process is trying to use the generative structure above to explain how your document collection came to be. This means that if there’s a certain bunch of terms that occur all the time in your documents, the model will spend a lot of effort trying to explain how they got there, and might end up ignoring terms that are less frequent.
Why might this be bad? Mostly because text data often tends to be “dirty”, with a lot of cruft that you don’t care about modeling. A great example is web pages. There’s a lot of nice information on web pages, but you’ll find if you pass raw web page source to Topic Models, the terms it finds most important will be things like “html”, “span”, “div” and “href”: Because these formatting directives appear all the time in web pages and in different quantities, the model will spend lots of effort trying to explain the differences in the occurrence rates of these tokens. Maybe that’s what you’re looking for; if you’ve got a dataset that is half web pages and half e-mail messages, the tokens that denote web pages might be useful indeed. It might also be nice to know which pages have more links. Then again, maybe you don’t care about HTML tags at all.
BigML attempts to remove tokens that occur “too frequently to be useful” when doing topic modeling, but it’s often specific to the use case whether or not something that’s frequently occurring is very important or just noise. But this is a problem that’s easy enough for you to fix: You can just exclude those useless terms from your dataset, either by pre-processing before you upload it, using Flatline, or using the excluded_terms parameter during the modeling process. You’ll often find that eliminating the half-dozen or so most common terms will yield a very different model; you’ll have changed the composition of your collection so much that other terms will have become far more relevant on a relative basis than they were the first time around.
Eyesight to the Blind
With a little understanding of how topic models work, you can create them with open eyes and maybe even improve your results by tweaking the data just a bit. Give them a try and, as usual, please drop us a line at support@bigml.com if you’re having trouble, or even if you just have some interesting data and want to show off the results. Good luck!
If you want to know more about this new resource, please visit the Topic Models release page and check our documentation to create Topic Models, interpret them, and predict with them through the BigML Dashboard and API, as well as the six blog posts of this series.
P.S. – Extra credit trivia question: What is notable about the names of all the subsections in this post?
