This series of posts started by introducing Topic Models as BigML’s implementation of Latent Dirichlet Allocation (LDA) to help discover thematically related terms in unstructured text data. We later explained how to use it through the BigML Dashboard, showed how to apply Topic Models in a real-life use case, and how to program Topic Models using the BigML API. This post will focus on automating LDA workflows by using WhizzML, a DSL for Machine Learning that helps automate workflows, program high-level algorithms, and share workflows and algorithm with others.
Let’s dive in by creating a Topic Model and making a prediction with it. In BigML, you can perform single instance predictions (referred to as a Topic Distribution) or in batch mode, which is called Batch Topic Distribution.
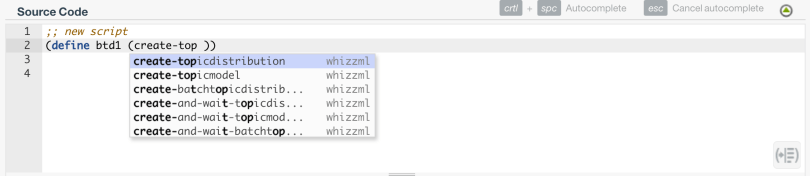
Firstly, we will create a Topic Model without specifying any particular configuration option, that is, relying on default settings. For that, you just need to create a script with the source code below:

BigML’s API is mostly asynchronous, so the above creation function will return a response before the Topic Model creation is completed. This implies that the Topic Model information is not ready to make predictions right after the above code snippet is executed, so it is convenient to wait for its completion before you can predict with it. You can do just that by using the directive “create-and-wait-topicmodel”. See the example below:

Now let’s try configuring a Topic Model via WhizzML. The properties to configure can be easily added in the mapping by using property pairs like <property_name> and <property_value>. For instance, in order to calculate a Topic Model with a dataset that contains one or more text fields, BigML automatically determines the number of topics, but if you prefer the maximum number of topics that BigML allows, you should add the property “number_of_topics” and set it to 64. Additionally, if you want your Topic Model to be case sensitive, then you need to set the “case_sensitive” property as true. Property names always need to be between quotes and the value should be expressed in the appropriate type. The code for our example can be seen below:

For more details about all available properties please check the API documentation.
You now know how to create a Topic Model, let’s see how to create predictions from it. The code is similar to the one used to create any resource. You just need the ID of the Topic Model you want to predict with and provide the input data as a map with the new text (or texts) that you want to predict for. The input_data property is a map that uses the field ID as key. Here’s an example:

This is one of the exceptions to the asynchronous behavior of BigML’s API, therefore the Topic Distribution gets ready without stopping the source code progress in this case.
In many working scenarios, a batch prediction that allows predictions from a set of new data is more useful than a single prediction. In other words, a Batch Topic Distribution is usually preferred to a Topic Distribution.
It is pretty straightforward to create a Batch Topic Distribution from an existing Topic Model, where the dataset with name ds1 represents a set of rows with the text data to analyze:

It’s likely that before creating a Batch Topic Distribution you will need to configure properties including fields mapping between Topic Model and the Dataset with the input data, or you may need to set another property to include the importance of each field as columns in your results. The way you should configure these properties is the same as for creating a Topic Model. The full list of all available properties is listed under API documentation. It’s also important to know that contrary to single predictions, batch predictions are asynchronous in nature. Below is such an example:

Up to this point we were covering source code of scripts. In order to write the code in the BigML Dashboard, you can also use a pretty editor that supports colored syntax highlighting, auto-complete functions, and code format utility. Take it for a spin and build your scripts quickly.
Nevertheless, if you are at home with APIs and you can find more script creation answers here. To obtain results from WhizzML scripts we need to first run them, so let’s see how to execute a Script in the Dashboard and how to carry out the same process by calling the right endpoint directly in the API.
First, the BigML Dashboard option: Look for your new script in the scripts list and click on it.
You will see a page like the one below, that is, the inputs you need to fill before you run. For instance, in the Topic Model script creation that we described at the beginning of this post, you just need to select the dataset you want to use to build your Topic Model from the dropdown.
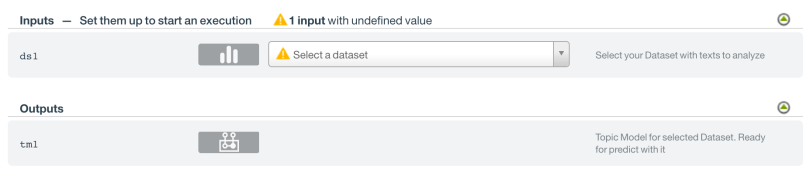
It’s mandatory to fill all the input fields with a grey icon so they are validated with a green icon (empty values are not accepted except for text inputs).

Finally, we will focus on how to execute a script through the API. To do this you need to compose a POST request with JSON content to /execute endpoint with two parameters: one will be the ID of the script you previously created, and the other one will be the “inputs”, which is a list of pairs that follow the schema <input_name> <input_value>. These include all the inputs without a defined default value in your script. Let’s see an example to showcase this idea: for the first script we used above, the input you need to fill is “ds1” with the dataset identifier you want to use to create a Topic Model. The complete request to the BigML API should be similar to this curl example:
curl "https://bigml.io/execution?$BIGML_AUTH" -X POST -H 'content-type: application/json' -d '{"script": "script/55f007d21f386f5199000003", "inputs": [["ds1", "dataset/55f007d21f386f5199000000"]]}'
We hope you enjoyed reading this quick tour on executing a script using the BigML API. For a more extensive list of execution parameters and how to access to the execution results, please visit the corresponding section in the API documentation. Notice that we didn’t dive into the authentication description, but it is described here. Finally, for an extensive description of WhizzML you can visit the WhizzML page.
In the next blog post we will discover the internal mathematics that underlies Topic Models and what these mathematics might imply for you, the modeler.
Would you like to know more about Topic Models? Visit the Topic Models release page and check our documentation to create Topic Models, interpret them, and predict with them through the BigML Dashboard and API, as well as the six blog posts of this series.

3 comments