In this blog post, the third one of our Topic Models series, we are showcasing how you can use BigML Topic Models to improve your model performance. We are using movie reviews extracted from the IMBD database to predict if a given review has a positive or a negative sentiment. Notice that in this post we will not dive into all the configuration options that BigML offers for Topic Models, for that we recommend that you read our previous post.
The Data
The dataset contains 50,000 highly polarized movie reviews labeled with their sentiment class: positive or negative. This dataset was built by Stanford researchers for their paper from 2011, which achieves an accuracy of 88.89%. The reviews belong to many different movies (a movie can only have up to 30 reviews) to avoid situations where the algorithm may learn non-generalizable patterns for specific plots, directors, actors or characters. The dataset is first split in two: 50% for training and the other 50% for testing.
As in any other dataset, the IMBD dataset, needs a bit of pre-processing so it can be used to properly train a Machine Learning model. Fortunately, BigML handles the major tasks of text pre-processing at the time of the Topic Model creation so you don’t need to care about text tokenization, stemming, lower and upper cases or stop words. When you create the Topic Model, the text is automatically tokenized so each single word is considered a token by the model vocabulary. Non-word tokens such as symbols and punctuation marks are automatically removed. One interesting task for further study would be to replace symbols that may indicate sentiment to test how it improves the model e.g., “:-)” becomes “SMILE”. BigML also removes stop words by default, however, in this case negative stop words may indicate sentiment so we can opt to leave them. Finally, stemming is applied over all the words so terms with the same lexeme are considered the same unique term (e.g., “loving” and “love”).
The only data cleansing task that we need to perform beforehand for this dataset is removing the HTML tag “<br>” which is seen frequently in the review content as seen below. You can do it at the time of the model creation using the configuration option “Excluded terms” explained below.

Single Decision Tree
To get a first sense of whether the text in the reviews have any power to predict the sentiment, we are going to build a single decision tree by selecting the “sentiment” as the objective field and using the reviews as input.
We assume in this post that you already know the typical process to build any model in BigML, i.e., how to upload the data to BigML and how to create a dataset. If you are not familiar then take a peak here.
When you are done creating your dataset, you can see that the movie reviews dataset is composed of two fields: sentiment (positive or negative) and reviews (the review text). Not surprisingly, the words “movie” and “film” are the most frequent ones in the collection (see image below).

If we perform a 1-click model, we obtain the decision tree in a few seconds. As you mouse over the root node and go down the tree until you reach the leaf nodes, you can see the different prediction paths. For example, in the image below you can see that if the review contains the terms “bad” and “worst” then it is a “negative” review with 92.99% of confidence. As expected, we can find words in the nodes such as “awful”, “boring”, “wonderful”, “amazing”, which are the terms that best split the data to best predict sentiment.
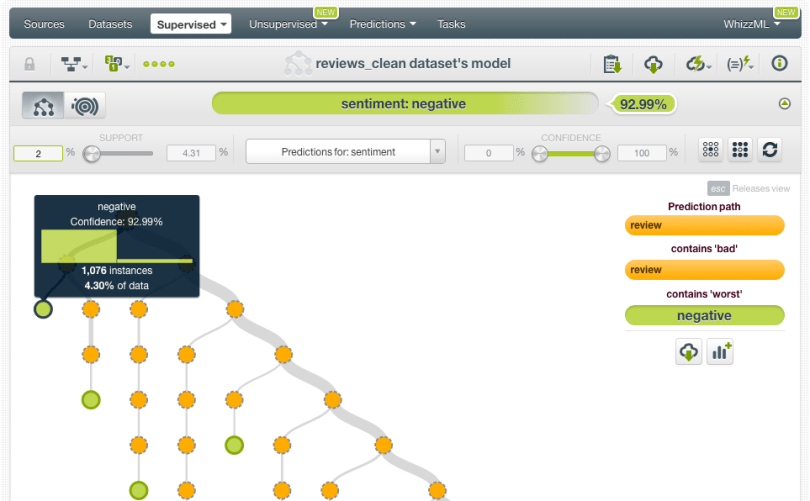
Confidence values seem pretty high for most prediction paths in this tree, but to measure its predictive power we need to evaluate it by using data it has not seen before. We use the previously set aside 50% of the dataset, which contains the remaining 25,000 movie reviews that have not been used to train our model.
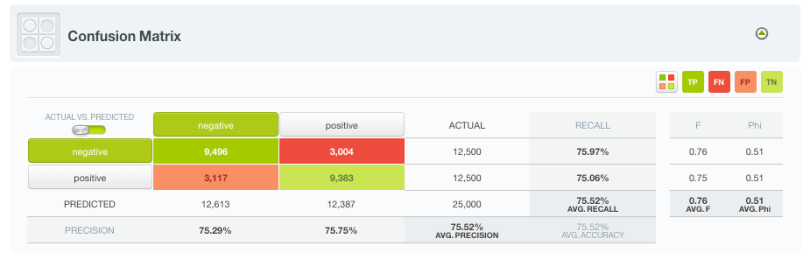
The evaluation yields an overall accuracy of 75.52%, which is not that bad for a 1-click model. However, we can definitely improve on this!
Discovering the Topics in the Reviews
We already saw that single terms are not very bad predictors of movie review sentiment. But having a particular term in a given review may not always be applicable, so the model gets quite complex as it uses lots of possible term combinations in order to get to the best prediction. This is because each person has his/her own way of expressing ideas with different vocabulary although the reviews may transmit very similar concepts. What if we could group those terms thematically related so that the model wouldn’t have to always look for single terms but instead groups of terms? You can now implement that approach in BigML by using Topic Models!
In the interest of time, we will neither go over the step by step process to create a Topic Model in BigML Dashboard nor cover all Topic Model configuration options here. We will just explain the relevant options that suffice in solving our problem of predicting the sentiment.
As we mentioned at the beginning of this post, the only data cleansing needed is the removal of the HTML tag “<br>”, so instead of using the 1-click Topic Model option we need to configure the model first. From the dataset, we select the “Configure Topic Model” option.

When the configuration panel has been displayed, use the “Excluded terms” option to type in the term “<br>” and click in the “Create Topic Model” green button below.

When our Topic Model is created, we can filter and inspect it by using the two visualizations provided by BigML.
In the first view, you will be able to see at-a-glance all the topics represented by circles sized in proportion to the topic importances. Furthermore, the topics are displayed in a map layout, which depicts the relationship between them such that closer topics are more thematically related.
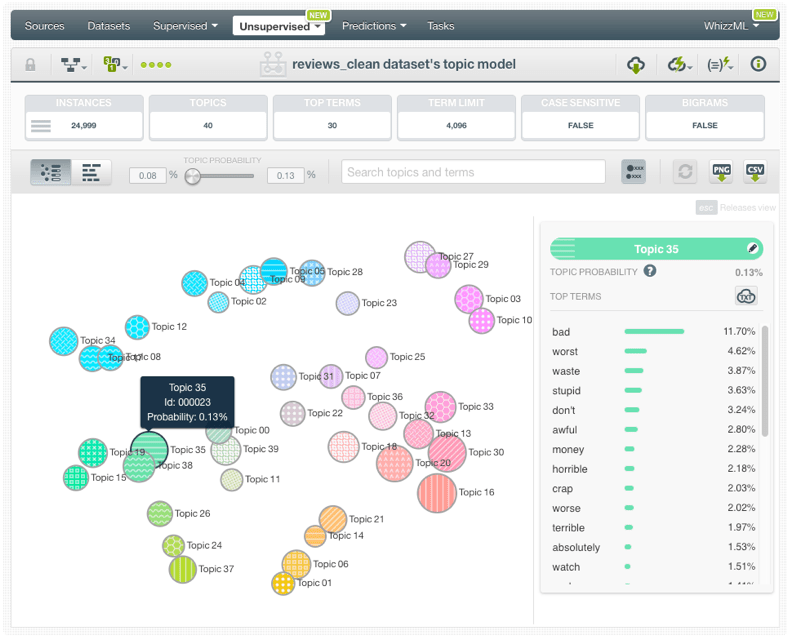
However, probably the best way to get an overview of your topics is to take a look at the second visualization: the bar chart. In this chart, you can view the top terms (up to 15) by topic. Each term is represented by a bar whose length signifies the importance of the term within that topic (i.e., the term probability). As you can see in the image below, you can use the top menu filters to better visualize the most important terms by topic.

The Topic Model finds the terms that are more likely to appear together and groups them into different topics. This probabilistic method yields quite accurate groupings of terms that are highly thematically related. If we inspect the model topic by topic, we can easily see that Topics 35 and 38 reveal terms like “bad”, “poor”, “boring”, “stupid”, “waste”, etc., all of which are clearly related to negative reviews. On the other hand, we can see positive sentiment topics like Topic 20 that includes words like “love”, “beautiful”, “perfect”, “excellent”, “recommend”, etc. Then there are other more neutral topics that indicate the genre of the film or its target audience e.g., Topic 21 containing “kids”, “animation”, “cartoons”, etc. We expect such topics that are not apparently correlated with any kind of sentiment to be identified as less important in our predictive model.
Including Topics in our Model
Now that we have seen that the topics discovered in our dataset seem to follow a general logic that may be useful to predict sentiment, we can include them as predictors. You can easily achieve this by performing a Batch Topic Distribution. Simply click in the corresponding option found within the 1-click menu and select the dataset used to train the Topic Model.

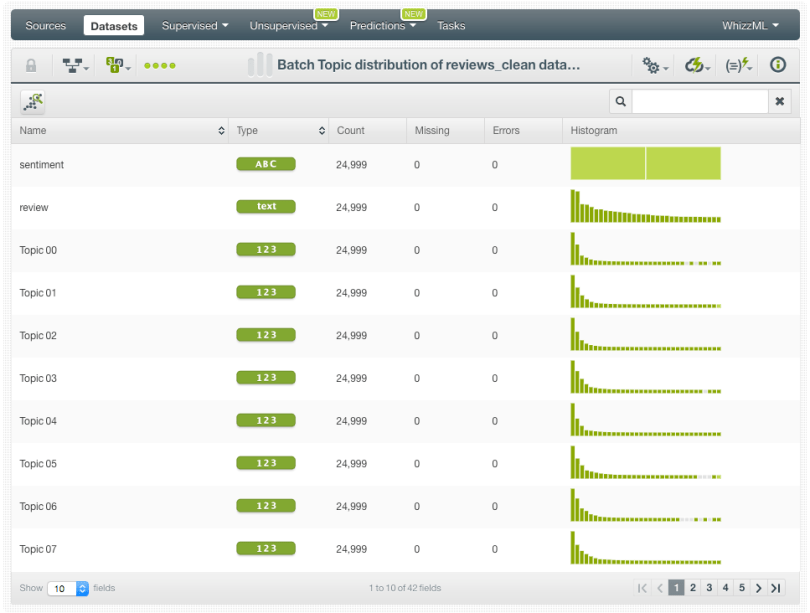
The Batch Topic Distribution calculates the probability of each topic for a given instance, so we will obtain a distribution of probabilities, one per topic, for all our dataset instances.
When the Batch Topic Distribution is created, we can access the dataset that contains the topic distributions. As seen below, a new field per topic is created whereby its values represent the probabilities for each of the instances.
Now we can recreate a model by using the topics as input fields. Amazingly, the resulting tree is very different from the one created before. Now the most important values to predict sentiment are not the single terms anymore, but the topics!

If we click in the Summary Report to see the field importances for our model, we can see that topics are much more important than full review texts. Not only that, we can also see that topics containing terms that may transmit sentiment are more important than neutral ones related to film genres or plots.

Time to evaluate our model!
We first need to perform a Batch Topic Distribution over the test dataset so it contains the same topic fields that the model uses to calculate predictions. We need to follow the same steps explained before, but this time we will select our test dataset instead of the training dataset. Once the Batch Topic Distribution has been performed, we can use the output dataset to evaluate our model.

As you can see, by including the topics in our model, we are able to bump up model accuracy to 80.04%, an improvement of 5% compared to the previous model without topics. This may sound small, but in real terms it means an increase of 1,250 reviews that are now correctly classified. Add to that the fact that the increase in performance has been realized without any fancy model configuration or complex feature engineering.
Using Random Decision Forests
So far we used a single tree to be able to easily visualize the differences between the modeling approaches we took (i.e., with or without topics). But it is well known that ensembles of trees usually perform significantly better in great majority of cases. Thus, using the same dataset, we build a Random Decision Forest and evaluate how it does. As expected, a Random Decision Forest with 100 trees swiftly reaches 84.05% accuracy.

Conclusions
We have seen how anyone working with text data can achieve significant performance enhancements by using topics as additional input fields in their models. With more time, one can still improve on our Random Decision Forests, but maybe that is best left for another day.
In the next post, we will cover how to programming Topic Models.
Would you like to know more about Topic Models? Visit the Topic Models release page and check our documentation to create Topic Models, interpret them, and predict with them through the BigML Dashboard and API, as well as the six blog posts of this series.
