BigML is bringing a new resource called Topic Models to help you discover the topics underlying a collection of documents. The main goal of Topic Modeling is finding significant thematically related terms (“topics”) in your unstructured text data. You can find an English example in the image below, which shows the topics found in a newspaper article about unemployment. BigML Topic Models can analyze any type of text in seven different languages: English, Spanish, Catalan, French, Portuguese, German and Dutch.

The resulting topics list can be used as a final output for information retrieval tasks, collaborative filtering, or for assessing document similarity among others. Topics can also be very useful as additional input features in your dataset towards other modeling tasks (e.g., classification, regression, clustering, anomaly detection).
In the first blog post of our series of six posts about Topic Models, we made a high-level introduction of Topic Modeling and the BigML implementation. In this post we will cover more in detail the fundamental steps required to find the topics hidden in your text fields by using the BigML Dashboard:

1. Upload your Data
Upload your data to your BigML account. You can drag and drop a local file, connect BigML to your cloud repository (e.g., S3 buckets) or copy and paste a URL containing your data. Once you have uploaded your data to BigML, the type for each field in your dataset will be automatically recognized by BigML.
Topic Models will only use the text fields in your dataset to find the relevant topics, so you need at least one text field. If you have a dataset with several types of fields, only the text fields will be considered as inputs to build the Topic Model. If multiple text fields are given as inputs they will be automatically concatenated so the content for each instance can be considered as a “bag of words” by the Topic Model.

BigML provides several configuration parameters for Text Analysis at the source level so you can decide the tokenization strategy e.g., whether you want to keep stop words. This configuration is used to create the vocabulary that will be used to build your models (see image below). However, Topic Models don’t take into account this configuration, you can configure most of these options at the time of the model creation from the Topic Model configuration panel explained in the 3rd step below. Tokenization and stemming are the only two options not configurable for Topic Models. Regarding tokenization, Topic Models will always tokenize your text fields by terms. On the other hand, stemming will be always active by default (e.g., the words “play”, “played”, “playing” will always be considered one unique term “play”).

2. Create the Dataset
From your Source view, use the 1-click Dataset option to create a dataset. This is a structured version of your data ready to be used by a Machine Learning algorithm.
For each of your text fields you will get a distribution histogram of your terms ordered by their frequency in the dataset. Next to the histogram, you will find an option to open the tag cloud of your text field as shown in the image below.

3. Create a Model
If you want to use the default parameter values, you can create a Topic Model from the dataset by using the 1-click Topic Model option. Alternatively you can tune the parameters by using the Configure Topic Model option.

BigML allows you to configure the following parameters:
- Number of topics: the total number of topics to be discovered in your dataset. You can set this number manually or you can let the algorithm find the optimal number of topics according to the number of instances in your dataset. The maximum number of topics allowed is 64.
- Number of top terms: the total number of top terms within each topic to be displayed in your Topic Model. By default it is set to 10, the maximum is 128 terms.
- Term limit: the total number of unique terms to be considered for the Topic Model vocabulary. By default it is set to 4,096, the maximum is 16,384 unique terms.
- Text analysis options:
- Case sensitivity: whether the Topic Model should differentiate terms with lower and upper cases. If you activate this option, “Grace” and “grace” will be considered considered two different terms. By default Topic Models are case insensitive.
- Bigrams: whether the Topic Model, apart from single terms, should include pairs of terms that typically go together (e.g.: “United States” or “mobile phone”). By default this option is not active.
- Stop words: whether the Topic Model should remove stop words (i.e., words such as articles, prepositions, conjunctions, etc.). By default stop words are removed.
- Excluded Terms: you can select specific terms to be excluded from the model vocabulary.
- Sampling options: if you have a very large dataset, you may not need all the instances to create the model. BigML allows you to easily sample your dataset at the model creation time.

4. Analyze your Topic Model
BigML provides two different views so you can analyze the topics discovered in your text.
Topic Map
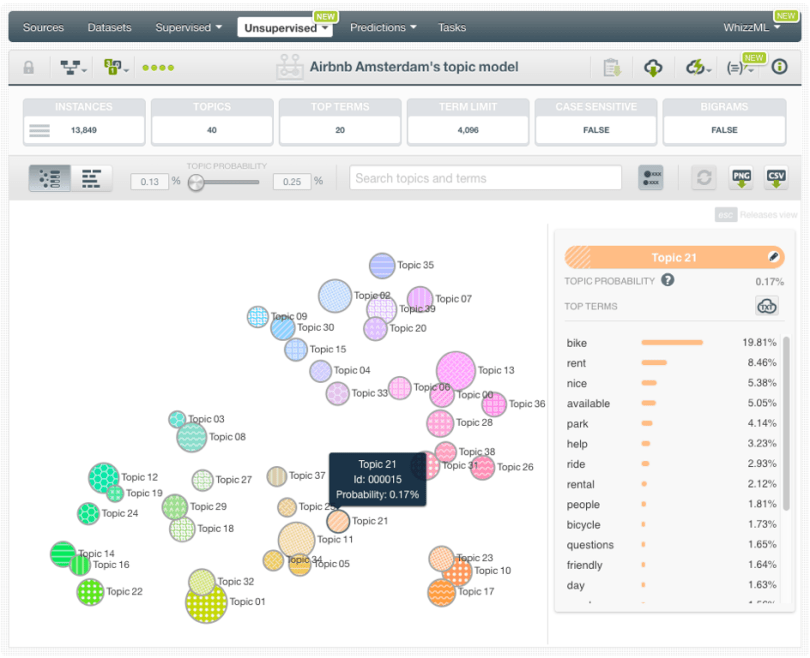
The topic map shows the topics in a map view, where you can get a sense of both the topic importances and the relationship between them. Each circle represents a different topic, and its size depicts the “Topic probability” — this is the average probability of the topic to appear in a given instance of the original dataset. The distance between the circles represents how close or far topics are thematically speaking.
By mousing over each topic you can see the top most important terms for that topic (see “Number of top terms” in the third step above). The terms are ordered by their importance within each topic as measured by the “Term probability”. All term probabilities for a given topic should sum up to 100%. A given term can be attributed to more than one topic, e.g., the word “bank” may be found in a topic related to finances, but also in a topic related to geology (river bank).
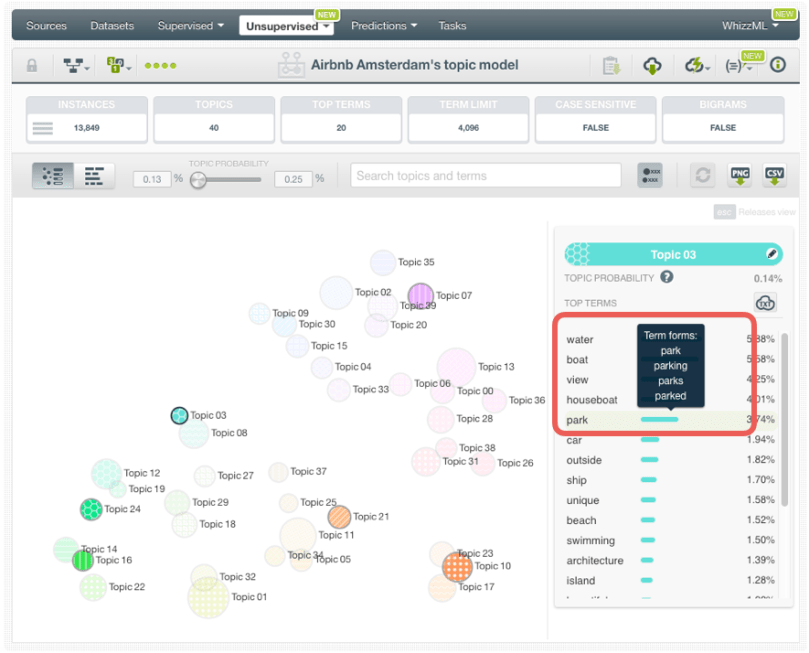
If you mouse over each term within a topic, you will find all the stemmed forms for that term. Stemming is the process of taking just the lexeme for the terms so e.g. the terms “great”, “greatness” and “greater”, are considered the same term, since they all have the same lexeme: “great”.
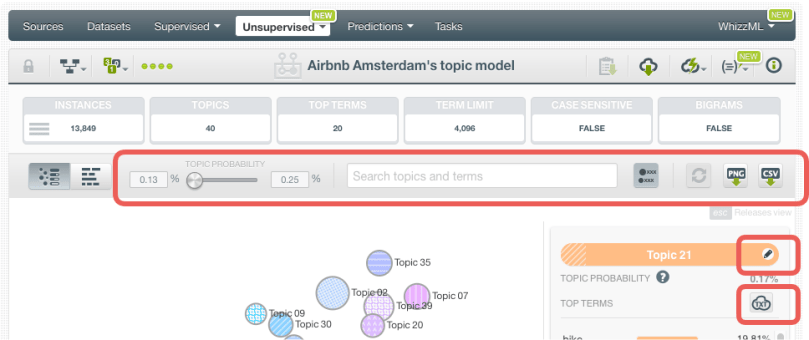
The map has the following options found in the top menu:
- Filtering options:
- Topic probability slider to filter the topic circles by size (importance) i.e., the average probability of a topic in a given instance in the original dataset used to create the model.
- Search box to filter topics and terms.
- Include/exclude labels for topics.
- Reset filters option.
- Export options:
- Export map in PNG format.
- Export model in CSV format.
- Edit topic names by clicking in a Topic circle, and you can change its name by using the edit icon. This is very useful to interpret the main theme of each topic, when you make predictions afterwards.
- Tag cloud to see the terms composing a topic in a tag cloud.
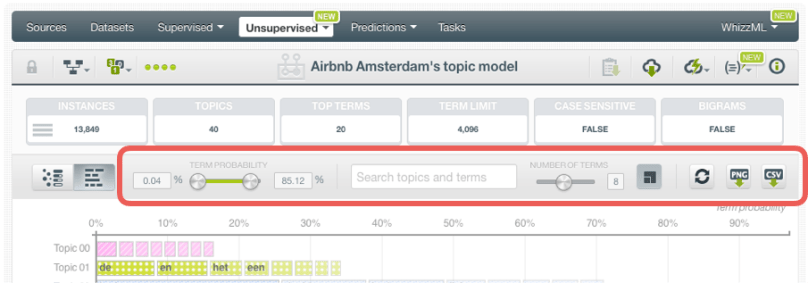
Term Chart
This view shows the topics and their terms in a bar chart to give you a quick overview of the terms composing the topics as well as their importances. In the horizontal axis, you can see each term probability for each of the top terms of a given topic (you can select up to 15 terms).

The chart has the following options found in the top menu:
- Filtering options:
- Term probability slider to filter terms by their probability in a given topic.
- Search box to filter topics and terms.
- Number of terms to select the maximum terms shown per topic in the chart.
- Dynamic axis option to adjust the axis scale to the current filters.
- Reset filters option.
- Export options:
- Export chart in PNG format (with or without legends).
- Export model in CSV format.
5. Make Predictions
The main objective of creating a Topic Model is to find the relevant topics for your dataset instances. Topic Model predictions are called Topic Distributions in BigML. For each instance you will get a set of probabilities (one per topic) indicating their relevance for that instance. For any given instance, topic probabilities should sum up to 100%.
BigML also allows you to make predictions for a single instance, Topic Distribution, or for several instances simultaneously, Batch Topic Distribution.
Topic Distribution
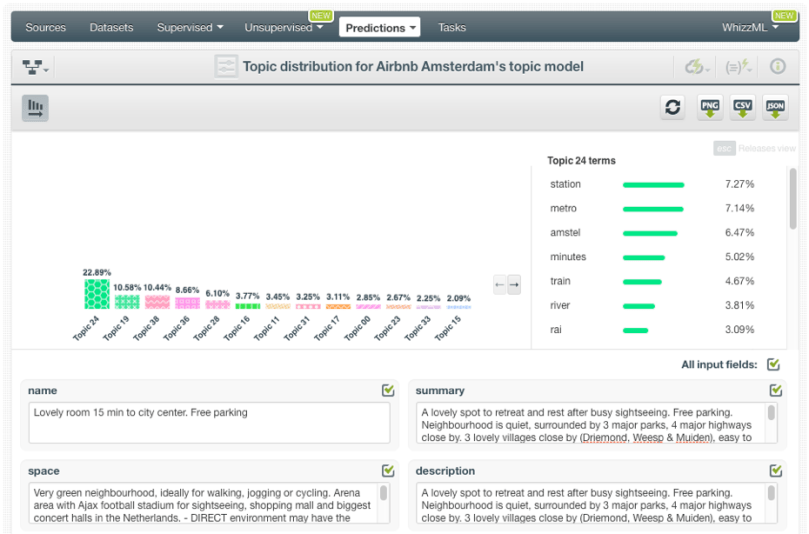
To get one single prediction for an input text, click the Topic Distribution option as shown in the image below.

You will get a form containing the input fields used to create the Topic Model. Include any text in the corresponding input field boxes. BigML automatically computes each topic probability for that input text. You can see topic probabilities in a histogram like the one shown in the image below. You can also see the terms within each topic by mousing over each topic.
Batch Topic Distribution
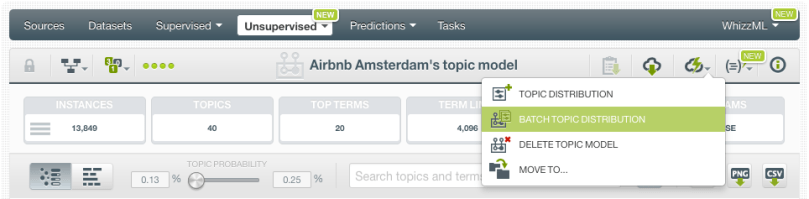
If you want to make predictions for several instances simultaneously, click the Batch Topic Distribution option as shown in the image below.
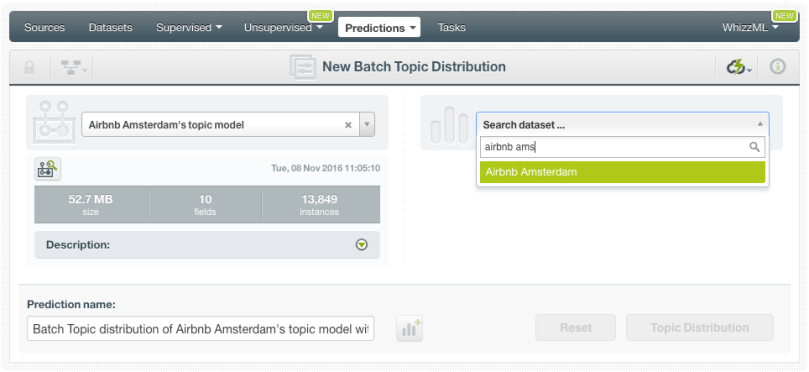
Then you need to select a dataset containing the instances for which you want to make the predictions. It can be the same dataset used to create the Topic Model or a different dataset.
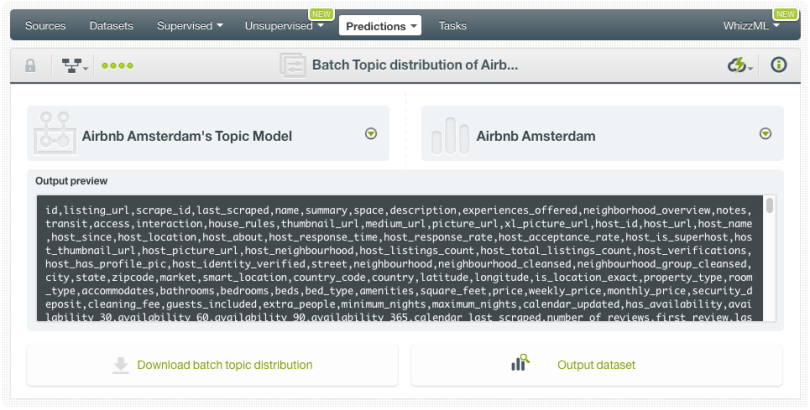
When your batch prediction finishes, you will be able to download the CSV file and see the output dataset.
In the next post, we will cover a real Topic Modeling use case to uncover the hidden topics of movie reviews from the IMBD database to predict the sentiment behind the reviews.
Would you like to know more about Topic Models? Visit the Topic Models release page and check our documentation to create Topic Models, interpret them, and predict with them through the BigML Dashboard and API, as well as the six blog posts of this series.
