We are proud to present Deepnets as the new resource brought to the BigML platform. On October 5, 2017, it will be available via the BigML Dashboard, API and WhizzML. Deepnets (an optimized version of Deep Neural Networks) are part of a broader family of classification and regression methods based on learning data representations from a wide variety of data types (e.g., numeric, categorical, text, image). Deepnets have been successfully used to solve many types of classification and regression problems in addition to social network filtering, machine translation, bioinformatics and similar problems in data-rich domains.

In the spirit of making Machine Learning easy for everyone, we will provide new learning material for you to start with Deepnets from scratch and progressively become a power user. We start by publishing a series of six blog posts that will gradually dive deeper into the technical and practical aspects of Deepnets. Today’s post sets off by explaining the basic Deepnet concepts. We will follow with an example use case. Then, there will be several posts focused on how to use and interpret Deepnets through the BigML Dashboard, API, and WhizzML and Python Bindings. Finally, we will complete this series with a technical view of how Deepnet models work behind the scenes.
Let’s dive right in!
Why Bring Deepnets to BigML?
Unfortunately, there’s a fair amount of confusion about Deepnets in the popular media as part of the ongoing “AI misinformation epidemic”. This has caused the uninitiated to regard Deepnets as some sort of a robot messiah destined to either save or destroy our planet. Contrary to the recent “immaculate conception” like narrative fueled by Deepnets’ achievements in the computer vision domain after 2012, the theoretical background of Deepnets dates back 25+ years.
- The first reason has to do with sheer scale. There are problems that involve massive parameter spaces that can be sufficiently represented only by massive data. In those instances, Deepnets can come to the rescue, thanks to the abundance of modern computational power. Speech recognition is a good example of such a challenging use case, where the difference between 97% accuracy and 98.5% accuracy can mean the difference between a consumer product that is very frustrating to interact with or one that is capable of near-human performance.
- In addition, the availability of the number of open source frameworks for computational graph composition has helped popularize the technique among more scientists. Such frameworks “compile” the required Deepnets architectures into a highly optimized set of commands that run quickly and with maximum parallelism. They essentially work by symbolically differentiating the objective for gradient descent thus freeing the practitioner from having to work out the underlying math himself.
Comparing Deepnets to Other Classifiers
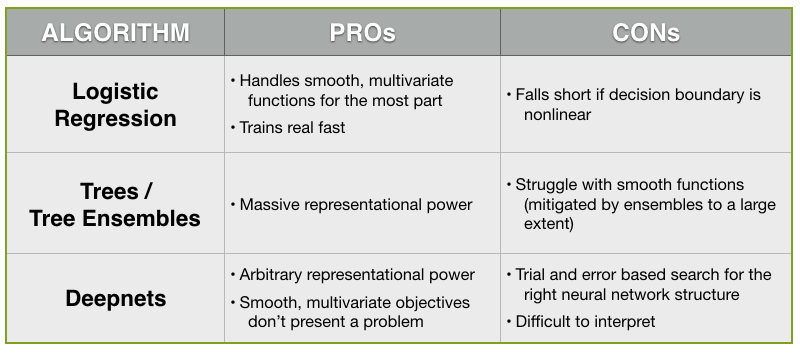
All good, but if we look beyond the hype, what are some of the major advantages and disadvantages of Deepnets before giving it serious consideration as part of our Machine Learning toolbox? For this, it’s best to contrast them with the pros and cons of alternative classifiers.
- As you’ll remember, decision trees have the advantage of massive representational power that expands as your data gets larger due to efficient and fast search capabilities. On the negative side, decision trees struggle with the representation of smooth functions as their axis-parallel thresholds require many variables to be able to account for them. Tree ensembles, however, mitigate some of these difficulties by learning a bunch of trees from sub-samples to counter the smoothness issue.
- As far as Logistic Regression is concerned, it can handle some smooth, multivariate functions as long as they lie in its hypothesis space. Furthermore, it trains real fast. However, because it is a parametric method, it tends to fall short for use cases where the decision boundary is nonlinear.
So, the question is: Can Deepnets mitigate the shortcomings of trees or Logistic Regression? Just like trees (or tree ensembles), with Deepnets, we get arbitrary representational power by modifying their underlying structure. On the other hand, similar to Logistic Regression, smooth, multivariate objectives don’t present a problem to Deepnets provided that we have the right network architecture underneath.
You may already be suspecting what the catch is, since there is no free lunch in Machine Learning. The first tradeoff comes in the form of ‘Efficiency‘, because there is no guarantee that the right neural network structure for a given data will be easily found. As a matter of fact, most structures are not useful. So you’re really left with no choice but to try different structures by trial and error. As a result, nailing the Deepnets structure remains a time-consuming task compared with the decision trees’ greedy optimization routine.
‘Interpretability‘ also is negatively impacted as the Deepnets practitioner ends up getting quite far away from the type of intuitive interpretability of tree-based algorithms. One possible solution is to use sampling and tree induction to create decision tree-like explanations for your Deepnet predictions (more on this later).
- If you have smaller datasets (e.g., thousands instead of millions of instances) you may be better off looking into other techniques like Logistic Regression or tree ensembles.
- Since better features almost always beat better models, problems that benefit from quick iterations may best be handled by other approaches. That is, if you need to iterate quickly and there are many creative features you can generate from your dataset to do so, it’s usually best to skip Deepnets and their trial and error based iterations in favor of algorithms that fit faster e.g., tree ensembles.
- If your problem’s cost-benefit equation doesn’t require every ounce of accuracy you can grab, you may also be better off with other more efficient algorithms that consume less resources.
Finally, remember that Deepnets are just another sort of classifier. As Stuart J. Russell, Professor of Computer Science at the University of California, Berkeley, has put:
- “…deep learning has existed in the neural network community for over 20 years. Recent advances are driven by some relatively minor improvements in algorithms and models and by the availability of large data sets and much more powerful collections of computers.”
From Zero to Deepnet Predictions

In BigML, a regular Deepnet workflow is composed of training your data, evaluating it and predicting what will happen in the future. In that way, it is very much like other supervised modeling methods available in BigML. But what makes Deepnets different, if at all?
1. The training data structure: The instances in the training data can be arranged in any manner. Furthermore, all types of fields (numeric, categoric, text and items) and missing values are supported in the same vein as other classification and regression models and ensembles.
2. Deepnet models: A Deepnet model can accept either a numeric field (for regression) or a categorical field (for classification) in the input dataset as objective field. In a nutshell, BigML’s Deepnets implementation is differentiated from similar algorithms due to its automatic optimization option to help you discover the best Deepnet parametrization during your network search. We will get into the details of our approach in a future post that will focus on what goes on under the hood.
3. Evaluation: Evaluations for Deepnet models are similar to other supervised learning evaluations, where random training-test splits are usually preferred. The same classification and regression performance metrics are applicable to Deepnets (e.g., AUC for classification or R-squared for regression). These metrics are fully covered in the Dashboard documentation.
4. Prediction: As in other classification and regression resources, BigML Deepnets can be used to make single or batch predictions depending on your need.
Understanding Deepnet Models
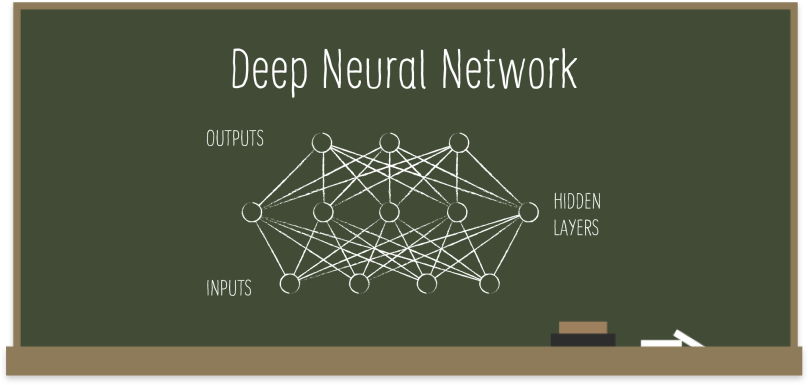
Not a lot of people talk about Deepnets as a generalization of Logistic Regression, but we can very well think about it in that way. (If you need a refresher on Logistic Regression, we recommend a quick read of our related post.) Take the following representation of Logistic Regression with nodes and arrows. The circles at the bottom are the input features and the ones on top are the corresponding output probabilities. Each arrow represents one of the coefficients (betas) to learn, which means the output becomes a function of those betas you’re trying to learn.

What if we add a bunch more circles as a hidden layer in the middle as seen below? In this case, the intermediate nodes would be computed the same way as before. Following the same approach, we can add as many nodes and layers to our structure as we choose to. Not only that, we can also mess with the function that computes the weights. In the case of Logistic Regression, it is the well-known logistic function, which is easily differentiable and optimized. By the same token, any other easily differentiable function can replace the logistic function, when it comes to Deepnet structures. Given all these structural choices, you can intuit how representationally powerful Deepnets can be, yet how difficult searching for the optimal structure can get in such a vast hypothesis space.
In Summary
- Help solve use cases such as computer vision, speech recognition, natural language processing, audio recognition, social network filtering, machine translation, and bioinformatics, among others.
- Can be used in classification and regression problems among other algorithms BigML provides.
- Implement a generalized form of Deep Neural Networks, instead of a specialized architecture optimized for a specific use case e.g., RNN, CNN, LSTM.
- BigML’s Deepnets implementation also comes with an automatic optimization option that lets you discover the best Deepnet parametrization during your network search.
You can create Deepnet models, interpret and evaluate them, as well as make predictions with them via the BigML Dashboard, our API and Bindings, plus WhizzML and Bindings (to automate your Deepnet workflows). All of these options will be showcased in future blog posts.
Want to know more about Deepnets?
At this point, you may be wondering how to apply Deepnets to solve real-world problems. For starters, in our next post, we will show a use case, where we will be examining an example dataset to see if we can make accurate predictions based on our Deepnet model. Stay tuned!
If you have any questions or you’d like to learn more about how Deepnets work, please visit the dedicated release page. It includes a series of six blog posts about Deepnets, the BigML Dashboard and API documentation, the webinar slideshow as well as the full webinar recording.
