In our previous blog post, we’ve introduced Deep Neural Networks. In today’s blog post, the second of our series of six, we’ll use BigML’s deep networks, called Deepnets, to walk through a supervised learning problem.
The Data
The dataset we are investigating is the Higgs dataset found at the UCI Machine Learning Repository. The problem, as explained in the original Nature Communications paper, is that particle accelerators create a huge amount of data. The Large Hadron Collider, for example, can produce 100 billion collisions in an hour and only a tiny fraction may produce detectable exotic particles like the Higgs boson. So a well-trained model is immensely useful for finding the needle in the haystack.

This dataset contains 28 different numeric fields and 11 million rows generated through simulation, but imitating actual collisions. As explained in the paper, these 28 fields come in two kinds. The first 21 of the fields capture low-level kinematic properties measured directly by the detectors in the accelerator. The last seven fields are combinations of the kinematic fields hand-designed by physicists to help differentiate between collisions that result in a Higgs boson and those that do not. So some of these fields are “real” data as measured, and some are constructed from domain-specific knowledge.
This kind of feature engineering is very common when solving Machine Learning problems, and can greatly increase the accuracy of your predictions. But what if we don’t have a physicist around to assist in this sort of feature engineering? Compared to other Machine Learning techniques (such as Boosted Trees), Deepnets can perform quite well with just the low-level fields by learning their own higher-level combinations (especially if the low-level fields are numeric and continuous).
To try this out, we created a dataset of just the first 1.5 million data points (for speed), and removed the last seven high-level features. We then split the data into a 80% training dataset and 20% testing dataset. Next up we create a Deepnet by using BigML’s automatic structure search.
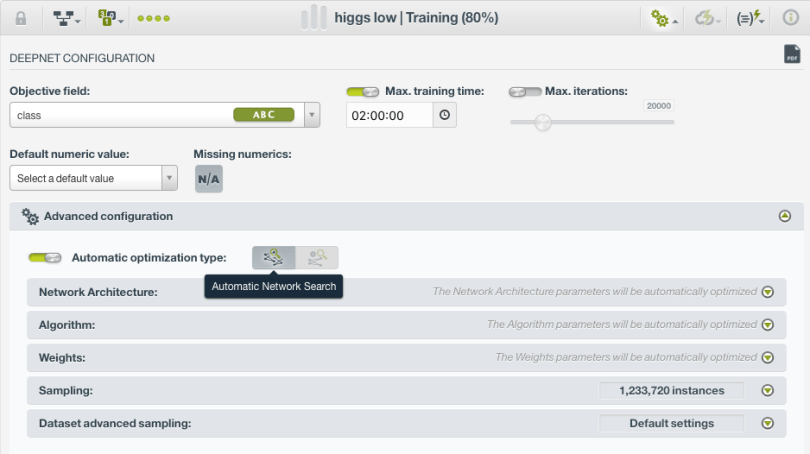
Deep neural networks can be built in a multitude of ways, but we’ve simplified this by intelligently searching through many possible network structures (number of layers, activation functions, nodes, etc.) and algorithm parameters (the gradient descent optimizer, the learning rate, etc.) and then making an ensemble classifier from the best individual networks. You can manually choose a network structure, tweak the search parameters, or simply leave all those details to BigML (as we are doing here).
The Deepnet
Once the Deepnet is created, it would be nice to know how well it is performing. To find out, we create an Evaluation using this Deepnet and the 20% testing dataset we split off earlier.
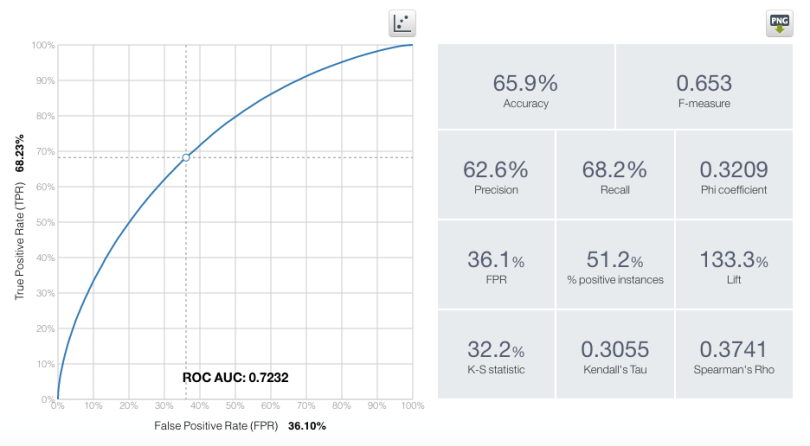
We get an accuracy of 65.9% and a ROC AUC of 0.7232. Perhaps we could even improve these numbers by lengthening the maximum training time. This is significantly better than our results using a Boosted Tree run with default settings. Here they are compared:
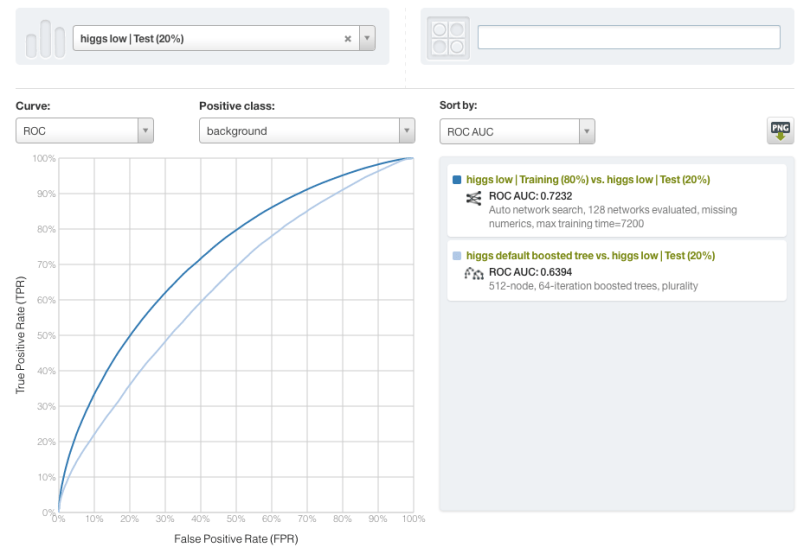
The Boosted Tree has an accuracy of 59.4% and a ROC AUC of 0.6394. The Boosted Tree is just not able to pull as much information out of these low-level features as the Deepnet. This is a clear example of when we should choose Deepnets over other supervised learning techniques to solve your classification or regression problems.
Want to know more about Deepnets?
Stay tuned for the more publications! In the next post we will explain how to use Deepnets through the BigML Dashboard. Additionally, if you have any questions or you’d like to learn more about how Deepnets work, please visit the dedicated release page. It includes a series of six blog posts about Deepnets, the BigML Dashboard and API documentation, the webinar slideshow as well as the full webinar recording.

3 comments