Building a predictive model that performs reasonably well scoring new data in production is a multi-step and iterative process that requires the right mix of training data, feature engineering, machine learning, evaluations, and black art. Once a model is running “in the wild”, its performance can degrade significantly when the distribution generating the new data varies from the distribution that generated the data used to train the model. Unfortunately, this is often the norm and not the exception in many real-world domains. We briefly described this issue recently. This problem is formally known as Covariate Shift, when the distribution of the inputs used as predictors (covariates) changes between training and production stages, or as Dataset Shift, when the joint distribution of inputs and the output (the target being predicted) also changes. Both Covariate Shift and Dataset Shift are receiving more attention from the research community. But, in practical settings, how can you automatically detect that there’s a significant difference between training and production data to properly take action and retrain or adjust your model accordingly?
In this post, I’m going to show you how to use Machine Learning (as it couldn’t be otherwise) to quickly check whether there’s a covariate shift between training data and production data. You read it right: Machine Learning to learn whether machine-learned models will perform well or not. I’ll describe a quick and dirty method and leave rigorous explanations and formal comparisons with other techniques (e.g., KL-divergence, Wald-Wolfowitz test, etc) for other forums. The method will also be helpful as a sneak peek of a couple of new exciting capabilities that we just brought to BigML: dataset transformations and multi-dataset models.

Let me start giving you the basic intuition behind the method.
The Basic Idea
Most supervised machine learning techniques are built on the assumption that data at the training and production stages follow the same distribution. So, to test whether that is the case in a particular scenario, we can just create a new dataset mixing training and production data, where each instance in the new dataset has been labeled either “train” or “production”, according to its provenance. In the absence of covariate shift, the distributions of the train and production data instances will be nearly identical, and we would have no easy way of distinguising between them. On the other hand, when the distributions of the two labels difer (i.e., when we do have a covariate shift in our data), it must be possible to predict whether an instance will have either the “train” or the “production” label. So our strategy to detect covariate shift will consist on building a predictive model with the provenance label as its target, and evaluating how well it scores when used to sift training from production data. More specifically, these are the steps we will follow:
- Create a random sample of your training data adding a new feature (Origin) with the value “train” to each instance in the sample.
- Create a random sample of your production data adding a new feature (Origin) with the value “production” to each instance in the sample.
- Create a model to predict the Origin of an instance using a sample (e.g., 80%) of the previous samples as training data.
- Evaluate the new model using the rest (e.g., 20%) of the previous samples as test data.
- If the phi coefficient of the evaluation is smaller than 0.2 then you can say that your training and production data are indistinguishable and they come from the same or at least very similar distribution. However, if the phi coefficient is greater than 0.2 then you can say that there’s a covariate shift and your training data is not really representative of your production data.
- To avoid the result to be just a matter of chance, you should run a number of trials and average the result.
I leave a formal explanation about the right number of trials and the right size of the samples for other forums but if you run at least 10 trials and use 80% of your data you’ll be on the safe zone. Another topic for a formal discussion would be threshold setting, that is, how to estimate the degradation of our model as phi increases; e.g., if phi is, say, 0.21, how bad is our model?… It will be disastrous in some domains and unnoticeable in others.
Next, I will show you how to quickly test the idea using as an example the training and test data (using the latter as “production” data) of the Titanic dataset as they were provided at the Kaggle competition, but removing the label and the ids of each instance.
Testing for Covariate Shift in a few API calls
I’m going to use BigML’s raw REST API within a simple bash script. A simpler function providing covariate shift checking will be available in BigML’s bindings, command-line and web interfaces very soon.
| #!/bin/bash | |
| # Simple test to detect covariate shift. | |
| # Requires: | |
| # BIGML_AUTH set up with your BIGML_USERNAME and API_KEY | |
| # curl: http://curl.haxx.se/ | |
| # jq: http://stedolan.github.io/jq/ | |
| BIGML_DOMAIN=bigml.io # Set it up to your own BigML VPC domain | |
| FINISHED=5 | |
| ERROR=-1 | |
| WAIT=5 | |
| TOTAL_WAIT=600 | |
| SEED=SEED | |
| TRAINING_SAMPLE_RATE=0.8 | |
| PRODUCTION_SAMPLE_RATE=0.8 | |
| EVALUATION_SAMPLE_RATE=0.8 | |
| OBJECTIVE_FIELD_NAME=Origin | |
| TRAINING_DATA=https://gist.github.com/aficionado/7743748/raw/3f1f1d5bd09c296e099344a80539103e4fa90756/titanic_train.csv | |
| PRODUCTION_DATA=https://gist.github.com/aficionado/7743752/raw/db2f5b38bc290b4defc68fe0865f23c16e1e6b7f/titanic_test.csv | |
| NAME=Titanic | |
| MAX_TRIALS=10 | |
| TRAINING_FILTER=true | |
| PRODUCTION_FILTER=true | |
| EXCLUDED_FIELDS=[] | |
| # Uncomment to induce a covariate shift | |
| TRAINING_FILTER='(= (f Sex) male)' | |
| PRODUCTION_FILTER='(!= (f Sex) male)' | |
| # Uncomment to exclude discriminative fields | |
| #EXCLUDED_FIELDS=[\"000001\"] | |
| function wait_resource { | |
| # Waits for resources to finish as their creation is asynchronous | |
| ID=$1 | |
| COUNTER=0 | |
| STATUS=$(curl -s "https://$BIGML_DOMAIN/$ID?$BIGML_AUTH" \ | |
| | jq ".status.code") | |
| while [ "$STATUS" -ne "$FINISHED" ] && [ "$STATUS" -ne "$ERROR" ] && | |
| [ "$COUNTER" -lt "$TOTAL_WAIT" ]; do | |
| sleep $WAIT | |
| let COUNTER++ | |
| STATUS=$(curl -s https://$BIGML_DOMAIN/$ID?$BIGML_AUTH \ | |
| | jq ".status.code") | |
| done | |
| if [ "$STATUS" -eq "$ERROR" ]; then | |
| echo "Detected a failure waiting for $ID" | |
| exit 1 | |
| fi | |
| } | |
| # Create training and production sources | |
| TRAINING_SOURCE=$(curl -s "https://$BIGML_DOMAIN/source?$BIGML_AUTH" \ | |
| -X POST -H "content-type: application/json" \ | |
| -d '{"remote": "'"$TRAINING_DATA"'", "name": "'"$NAME"' Training"}' \ | |
| | jq -r ".resource") | |
| PRODUCTION_SOURCE=$(curl -s "https://$BIGML_DOMAIN/source?$BIGML_AUTH" \ | |
| -X POST -H "content-type: application/json" \ | |
| -d '{"remote": "'"$PRODUCTION_DATA"'", "name": "'"$NAME"' Production"}' \ | |
| | jq -r ".resource") | |
| # Create training and production datasets | |
| wait_resource $TRAINING_SOURCE | |
| TRAINING_DATASET=$(curl -s "https://$BIGML_DOMAIN/dataset?$BIGML_AUTH" \ | |
| -X POST -H "content-type: application/json" \ | |
| -d '{"source": "'"$TRAINING_SOURCE"'"}' \ | |
| | jq -r ".resource") | |
| wait_resource $PRODUCTION_SOURCE | |
| PRODUCTION_DATASET=$(curl -s "https://$BIGML_DOMAIN/dataset?$BIGML_AUTH" \ | |
| -X POST -H "content-type: application/json" \ | |
| -d '{"source": "'"$PRODUCTION_SOURCE"'"}' \ | |
| | jq -r ".resource") | |
| wait_resource $TRAINING_DATASET | |
| wait_resource $PRODUCTION_DATASET | |
| TRIALS=0 | |
| AVG_PHI=0 | |
| while [ "$TRIALS" -lt "$MAX_TRIALS" ]; do | |
| let TRIALS++ | |
| # Filter training and production datasets and label them with a new field | |
| LABELED_TRANING_DATASET=$(curl -s \ | |
| "https://$BIGML_DOMAIN/dataset?$BIGML_AUTH" \ | |
| -X POST -H "content-type: application/json" \ | |
| -d '{"origin_dataset": "'"$TRAINING_DATASET"'", | |
| "lisp_filter": "'"$TRAINING_FILTER"'", | |
| "new_fields": [{"field": "Training", | |
| "name": "'"$OBJECTIVE_FIELD_NAME"'"}], | |
| "sample_rate": '"$TRAINING_SAMPLE_RATE"'}' \ | |
| | jq -r ".resource") | |
| LABELED_PRODUCTION_DATASET=$(curl -s \ | |
| "https://$BIGML_DOMAIN/dataset?$BIGML_AUTH" \ | |
| -X POST -H "content-type: application/json" \ | |
| -d '{"origin_dataset": "'"$PRODUCTION_DATASET"'", | |
| "lisp_filter": "'"$PRODUCTION_FILTER"'", | |
| "new_fields": [{"field": "Production", | |
| "name": "'"$OBJECTIVE_FIELD_NAME"'"}], | |
| "sample_rate": '"$PRODUCTION_SAMPLE_RATE"'}' \ | |
| | jq -r ".resource") | |
| wait_resource $LABELED_TRANING_DATASET | |
| wait_resource $LABELED_PRODUCTION_DATASET | |
| # Compute sample rate sizes to make sure that the input dataset for the | |
| # model is balanced | |
| TRAINING_INSTANCES=$(curl -s \ | |
| "https://$BIGML_DOMAIN/$LABELED_TRANING_DATASET?$BIGML_AUTH" \ | |
| | jq -r ".rows") | |
| PRODUCTION_INSTANCES=$(curl -s \ | |
| "https://$BIGML_DOMAIN/$LABELED_PRODUCTION_DATASET?$BIGML_AUTH" \ | |
| | jq -r ".rows") | |
| if [ $TRAINING_INSTANCES -gt $PRODUCTION_INSTANCES ]; then | |
| SAMPLE_RATE=$(echo "$PRODUCTION_INSTANCES/$TRAINING_INSTANCES" | bc -l) | |
| TRAINING_SAMPLE_RATE=$(printf '%.4f\n' $SAMPLE_RATE) | |
| PRODUCTION_SAMPLE_RATE=1 | |
| else | |
| SAMPLE_RATE=$(echo "$TRAINING_INSTANCES/$PRODUCTION_INSTANCES" | bc -l) | |
| TRAINING_SAMPLE_RATE=1 | |
| PRODUCTION_SAMPLE_RATE=$(printf '%.4f\n' $SAMPLE_RATE) | |
| fi | |
| # The target of the new model will be the label (Training / Production) | |
| OBJECTIVE_FIELD=$(curl -s \ | |
| "https://$BIGML_DOMAIN/$LABELED_TRANING_DATASET?$BIGML_AUTH;prefix=$OBJECTIVE_FIELD_NAME" \ | |
| | jq -r ".fields | keys[0]") | |
| # Create a model using just a sample of the data | |
| MODEL=$(curl -s "https://$BIGML_DOMAIN/model?$BIGML_AUTH" \ | |
| -X POST -H "content-type: application/json" \ | |
| -d '{"datasets": ["'"$LABELED_TRANING_DATASET"'", | |
| "'"$LABELED_PRODUCTION_DATASET"'"], | |
| "sample_rates": {"'"$LABELED_TRANING_DATASET"'": | |
| '"$TRAINING_SAMPLE_RATE"', | |
| "'"$LABELED_PRODUCTION_DATASET"'": | |
| '"$PRODUCTION_SAMPLE_RATE"'}, | |
| "objective_field": "'"$OBJECTIVE_FIELD"'", | |
| "sample_rate": '"$EVALUATION_SAMPLE_RATE"', | |
| "seed": "'"$SEED"'", | |
| "name": "'"$NAME"' - Covariate Shift?", | |
| "excluded_fields": '"$EXCLUDED_FIELDS"'}' \ | |
| | jq -r ".resource") | |
| wait_resource $MODEL | |
| # Create an evaluation using the other part of the data (out_of_bag=true) | |
| EVALUATION=$(curl -s "https://$BIGML_DOMAIN/evaluation?$BIGML_AUTH" \ | |
| -X POST -H "content-type: application/json" \ | |
| -d '{"datasets": ["'"$LABELED_TRANING_DATASET"'", | |
| "'"$LABELED_PRODUCTION_DATASET"'"], | |
| "sample_rates": {"'"$LABELED_TRANING_DATASET"'": | |
| '"$TRAINING_SAMPLE_RATE"', | |
| "'"$LABELED_PRODUCTION_DATASET"'": | |
| '"$PRODUCTION_SAMPLE_RATE"'}, | |
| "sample_rate": '"$EVALUATION_SAMPLE_RATE"', | |
| "seed": "'"$SEED"'", | |
| "out_of_bag": true, | |
| "model": "'"$MODEL"'", | |
| "name": "'"$NAME"' - Covariate Shift?"}' \ | |
| | jq -r ".resource") | |
| wait_resource $EVALUATION | |
| PHI=$(curl -s "https://$BIGML_DOMAIN/$EVALUATION?$BIGML_AUTH" \ | |
| | jq -r ".result.model.average_phi") | |
| AVG_PHI=$(echo "$AVG_PHI + $PHI" | bc -l) | |
| printf '%.4f\n' $PHI | |
| done | |
| AVG_PHI=$(echo "$AVG_PHI / $TRIALS" | bc -l) | |
| printf 'AVG_PHI: %.4f\n' $AVG_PHI |
First of all, I create a source for the training data (lines 58-61) and another for the production data (lines 63-66) using their respective remote locations defined at the beginning of the script (lines 22 and 23). Then I create a full dataset for the training source (lines 70-73) and another for the production source (lines 76-79). Then I sample the training data and add a new field named “Origin”, with the value “train” to each instance (lines 90-98) and do the same for the production data but adding the value “production” to each instance (lines 100-108).
The next step is to create a multi-dataset model using both datasets above. Notice that I also subsample the dataset with a bigger number of instances to make sure that the class distribution (train and production) is balanced. I also specify a seed to make sure that I can later evaluate against a complete disjoint subset of the data. Once the model is created, I’m ready to create an evaluation of the new model with the portion of the dataset that I didn’t use to create the model (“out_of_bag”: true). I iterate 10 times and in each iteration display and save the phi coefficient to finally compute and show the average phi at the end of the 10 iterations.
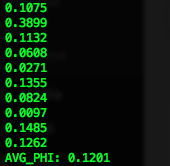 As the average phi coefficient is a poor 0.1201, We conclude that there’s not a covariate shift.
As the average phi coefficient is a poor 0.1201, We conclude that there’s not a covariate shift.
Next I’m going to run the same test but I’ll induce a covariate shift first. To do that, I filter the training data to just contain instances of “male” passengers and filter the production data to just contain instances of female passengers (just uncommenting lines 31 and 32 makes the trick).
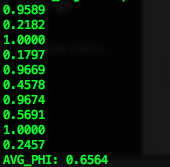 In this case, the average phi turns to be 0.6564 so I can say that there is a covariate shift between the training data and production. I shared one of the models of the last test here. You can see that Name is a great predictor for Sex or, in other words, it gets almost perfect discrimination between the training and production data. So just to eliminate any suspicions about the method, I will repeat the test again in this case excluding the field Name from the model (uncommenting line 35). As you can see below, the method still detects the covariate shift in this case with an average phi of 0.3635.
In this case, the average phi turns to be 0.6564 so I can say that there is a covariate shift between the training data and production. I shared one of the models of the last test here. You can see that Name is a great predictor for Sex or, in other words, it gets almost perfect discrimination between the training and production data. So just to eliminate any suspicions about the method, I will repeat the test again in this case excluding the field Name from the model (uncommenting line 35). As you can see below, the method still detects the covariate shift in this case with an average phi of 0.3635.

Once you detect a covariate shift you’ll need to retrain your model using new production data. If that is not feasible and depending on the nature of your data there is a number of techniques that can help you adjust your training data.
Notice that In the API calls above, I used two new BigML features:
- Dataset transformations: I was able to filter and sample a dataset based on the value of a field, and also adding new values to existing datasets.You’ll see in an upcoming post many other ways to add fields to an existing dataset, as well as how to remove outliers, discretize continuous variables or creating windows, among many other tricks.
- Multi-dataset models: I could create a model using two datasets as input, sampling each one differently/at differing rates. We’ll also see in a future post that you can create models with up to 32 different datasets individually sampled. This can be very useful to deal with imbalanced datasets or to weight your datasets differently.
Both new capabilities are available via our API and soon via our web interface as well. As you are probably beginning to see, BigML is opening a new venue in automating predictive modeling in the cloud, in ways that had never been available before.
Recap
To quickly check whether there’s a covariate shift between your training and production data you can create a predictive model using a mix of instances from the training and production data. If the model is capable of telling apart training instances from production instances then you can say that there’s a covariate shift. The idea behind this method is not new, I first heard of it from Prof. Tom Dietterich, but it’s probably part of the “folk knowledge” needed to develop robust machine learning applications, and it is hard to track it to a specific or original first reference. Anyway, being able to implement it in a few API calls is kind of cool, isn’t it? It will be even cooler once BigML provides it just one call or click away. Stay tuned!

I like the way you explain.
It’s a nice method, however I have the following remarks:
For every batch of production data you need to build a separate model, and you need to keep you training data available for doing so. That is/can be burdensome. Also, it doesn’t work on streaming data.
So, I’m more concerned with new cases that lie outside the (multivariate) domain of the training set than inside. So, scoring a dataset with only men while the model is trained on both men and women shouldn’t be a problem. The reverse is an issue: if I build a model on people between 20-30 and I start scoring it on people of all ages, I’m likely in trouble. So, this is what I want to detect, and I’d do so with a one-class SVM or the anomaly detection mode of a RF. In those cases you can store the model for multiple production batches and in the streaming case you can take a running mean on the outlier-ness of cases.
Olav,
Thanks for your comment.
That’s right. You need to build a new model/ensemble “each time”. It’s not that complex if you do everything on the cloud 🙂 Check this gist out: https://gist.github.com/aficionado/8304590.
Keeping all the data around is something that you need to do anyways. To implement the method you don’t need to use all the data but just build representative samples of your historical and new data. With streaming data, it becomes again a matter of choosing a right sample size and the right window size. In the example above, a day.
Anyway, I think that method can be applied in general to multitude of domains as a quick indication. What you propose makes a lot of sense to implement a specific anomaly detector. Actually, we’re working on a version of Isolation Forests http://cs.nju.edu.cn/zhouzh/zhouzh.files/publication/icdm08b.pdf that will help implement anomaly detectors as you suggest.
Thanks again for your comment.
Hello,
I really enjoyed your tutorial, so much so that I’m using your method for some experiments.
I verified at the end of the article that the author indicated that this method is not recent, already being used previously. I looked for some published sources that used this method but I did not find it.
Is it possible to indicate any source that uses the method?
Hi Daniel, thanks for your comment. There’re books like this https://mitpress.mit.edu/books/dataset-shift-machine-learning that deal with this problem from a more theoretical point of view. Never found a formal reference to the specific method and as I mentioned at the time of writing it, the first thing that came to my memory was a conversation with Tom Dietterich. We published another post explaining how do it the check using WhizzML https://blog.bigml.com/2016/06/06/whizzml-tutorial-ii-covariate-shift/ and another one using anomaly detectors https://blog.bigml.com/2016/06/21/using-anomaly-detectors-to-assess-covariate-shift/.