In this series about feature selection, the first three posts covered three different WhizzML scripts that can help you with this task: Recursive Feature Elimination, Boruta and Best-First Feature Selection. We explained how they work and the needed parameters for each one of them, applying the scripts to the system failures in trucks dataset described in the first post.
As we previously explained, this kind of script can help us deal with wide datasets by selecting the most useful features. They are an interesting alternative to dimensionality reduction algorithms such as Principal Component Analysis (PCA). Furthermore, they provide the advantage that you don’t lose any model interpretability because you are not transforming your features.
Feature Selection algorithms can work in two different ways:
- They can start using all the fields from the dataset and, iteratively, remove the least important fields. This is how Recursive Feature Elimination and Boruta work.
- They can start with 0 fields, and, iteratively, add the most important features. This is how Best-First Feature Selection works.
Let’s compare the results from these three scripts. To that end, we have used them with a reduced version of the dataset mentioned previously. This reduced version, the same that we used in the Best-First post, has 29 fields and 15,000 rows.
In the table below, we can see a comparison between the scripts. We have annotated the execution times, the number of output fields, and the number of output fields in common between each pair of scripts. For each script output dataset, we have created and evaluated an ensemble.
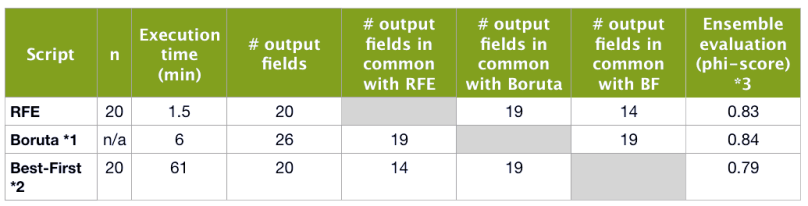
- * Using max-runs of 10 and min-gain of 0.01 (default parameters)
- * Using the same input parameters as in the previous post.
- * phi-score with the 29 fields dataset is 0.84.
From these tests, we extract some interesting conclusions:
- Recursive Feature Selection is a simple script that runs extremely fast with only a few parameters, all without sacrificing accuracy. Its results are clearly consistent with the ones from the other scripts.
- Boruta is a useful script that has an interesting feature: it is free from user bias because the n parameter, that represents the number of features to select, is not required.
- Best-First Feature Selection is the most time-consuming of the scripts so we should use it with smaller datasets or on a previously reduced one. However, it is the only one that starts with 0 fields, and the information from the very first iterations is useful to see which are the most important features of our dataset.
The system failures in trucks dataset seemed to be a difficult dataset to work with. The large number of fields and their useless names made it hard to apply domain knowledge to it. These scripts helped us to automatically obtain the most important features without loosing modeling performance.
Now it’s your turn! Try out these new scripts and let us know if you have any feedback at support@bigml.com. What’s more, give WhizzML a try and create your own scripts that help automate your frequent tasks.
