In this third post about feature selection scripts in WhizzML, we will introduce the third and final algorithm, Best-First Feature Selection (Best-First). In the first post, we discussed Recursive Feature Selection, and in the second post, we covered Boruta.
Introduction to Best-First Feature Selection
You can find this script in the BigML Script Gallery If you want to know more about it, visit its info page.
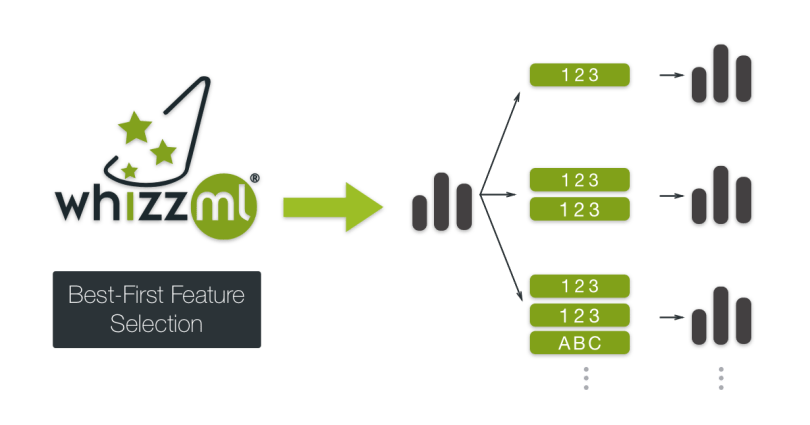
Best-First selects the n best features for modeling a given dataset, using a greedy algorithm. It starts by creating N models, each of them using only one of the N features of our dataset as input. The feature that yields the model with the best performance is selected. In the next iteration, it creates another set of N-1 models with two input features: the one selected in the previous iteration and another of the N-1 remaining features. Again, the combination of features that gives the best performance is selected. The script stops when it reaches the number of desired features which is specified in advance by the user.
One improvement we made to this script includes k-fold cross-validation for the model evaluation process at each iteration. This ensures that the good or bad performance of one model is not produced by chance because of a single favorable train/test split.
Since this is the most time-consuming script of the dimensionality reduction scripts described in this series of posts, another useful feature has been added to this script: early-stop. We can configure the script to stop the execution if there are a certain number of iterations where the additional features do not improve the model performance. We created two new inputs for that:
- early-stop-performance: An early-stop-performance improvement value (in %) used as a threshold to consider if a new feature has a better performance compared to previous iterations.
- max-low-perf-iterations: The maximum number of consecutive iterations allowed that may have a lower performance than the early-stop performance set. It needs to be set as a percentage of the initial number of features in the dataset.
Finally, there are two more inputs that can be very useful:
- options: It allows you to configure the kind of model that will be created at each iteration and its parameters.
- pre-selected-fields: List of field IDs to be pre-selected as best features. The script won’t consider them but they will be included in the output.
Feature selection with Best-First Feature Selection
As this is a time-consuming script, we won’t apply it to the full Trucks APS dataset used in the first post in case you wanted to quickly replicate the results. We will use a subset of the original dataset that uses the 29 fields selected by the Boruta script in our second post. Then we will apply these parameters:
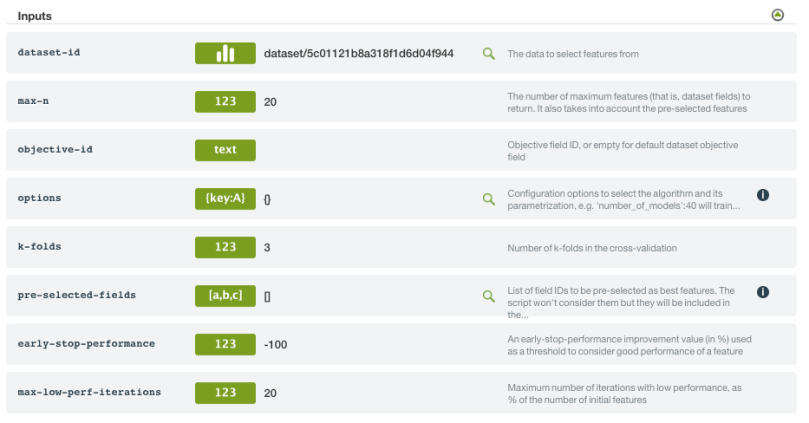
We have used a max-n of 20 because that’s the number of features that we want to select. As we want the script to return exactly 20 features, we are using an early-stop-performance value of -100 to bypass the early stop feature. After 1 hour, Best-First selects these 20 fields as important:
"bj_000", "ag_002", "ba_005", "cc_000", "ay_005", "am_0", "ag_001", "cn_000", "cn_001", "cn_004","cs_002","ag_003", "az_000", "bt_000", "bu_000", "ee_005", "al_000", "bb_000","cj_000", "ee_007"
In the fourth and final post, we will compare RFE, Boruta, and Best-First to see which one is better suited for different use cases. We will also explore the results of the evaluations performed to the reduced datasets and compare them with the original ones. Stay tuned!
