With the Summer 2018 Release Data Transformations were added to BigML. SQL-style queries, feature engineering with the Flatline editor and options to merge and join datasets are great, but sometimes these are not enough. If we have hundreds of different columns in our dataset it can be hard to handle them.
We are able to apply transformations but to which columns? Which features are useful for our target prediction and which ones are only increasing resource usage and model complexity?
Later, with the Fall 2018 Release, Principal Component Analysis (PCA) was added to the platform in order to help with dimensionality reduction. PCA helps with the challenge of extracting the discriminative information in the data while removing those fields that only add noise and make it difficult for the algorithm to achieve the expected performance. However, PCA transformation yields new variables which are linear combinations of the original fields, and this can be a problem if we want to obtain interpretable models.

Feature Selection Algorithms will help you to deal with wide datasets. There are 4 main reasons to obtain the most useful fields in a dataset and discard the others:
- Memory and CPU: Useless features consume unnecessary memory and CPU.
- Model performance: Although a good model will be able to detect which are the important features in a dataset, sometimes, this noise generated by useless fields confuses our model, and we obtain better performance when we remove them.
- Cost: Obtaining data is not free. If some columns are not useful, don’t waste your time and money trying to collect them.
- Interpretability: Reducing the number of features will make our model simpler and easier to understand.
In this series of four blog posts, we will describe three different techniques that can help us in this task: Recursive Feature Elimination (RFE), Boruta algorithm, and Best-First Feature Selection. These three scripts have been created using WhizzML, BigML’s domain-specific language. In the fourth and final post, we will summarize the techniques and provide guidelines for which are better suited depending on your use case.
Some of you may already know about the Best-First and Boruta scripts since we have offered them in the WhizzML Scripts Gallery. We will provide some details about the improvements we made to those and the new script, RFE.
Introduction to Recursive Feature Elimination (RFE)
In this post, we are focusing on Recursive Feature Elimination. You can find it in BigML Script Gallery If you want to know more about this script, visit its info page.
This is a completely new script in WhizzML. RFE starts using all the fields and, iteratively, creates ensembles removing the least important field at each iteration. The process is repeated until the number of fields (set by the user in advance) is reached. One interesting feature of this script is that it can return the evaluation for each possible number of features. This is very helpful to find the ideal number of features we should use.
The script input parameters are:
- dataset-id: input dataset
- n: final number of features expected
- objective-id: objective field (target)
- test-ds-id: test dataset to be used in the evaluations (no evaluations take place if empty)
- evaluation-metric: metric to be maximized in evaluations (default if empty). Possible classification metrics: accuracy, average_f_measure, average_phi (default), average_precision, and average_recall. Possible regression metrics: mean_absolute_error, mean_squared_error, r_squared (default).
Our dataset: System failures in trucks dataset
This dataset, originally from the UCI Machine Learning Repository, contains information for multiple sensors inside trucks. The dataset consists of trucks with failures and the objective field determines whether or not the failure comes from the Air Pressure System (APS). This dataset will be useful for us for two reasons:
- It contains 171 different fields, which is a sufficiently large number for feature selection.
- Field names have been anonymized for proprietary reasons so we can’t apply domain knowledge to remove useless features.
As it is a very big dataset, we will use a sample of it with 15,000 rows.
Feature Selection with Recursive Feature Elimination
We will start applying Recursive Feature Elimination with the following inputs. We are using an n=1 because we want to obtain the performance of all possible subset of features, from 171 until 1. If we set a higher n, e.g. 50, the script would stop when it reached that number so we wouldn’t know how smaller subsets of features perform.

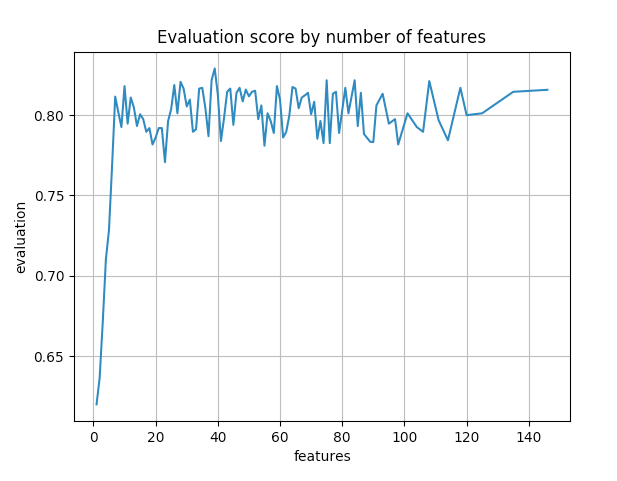
After 30 minutes, we obtain an output-features object that contains all the possible subsets of features and their performance. We can use it to create the graph below. From this, we can deduce the optimal number of features is around 25. From 25 features on, the performance is stable.
Now that we know that we should obtain around 25 features, let’s run the script again to find out which are the optimal 25. This time, as we don’t need to perform evaluations, we won’t pass the test dataset to the script execution.
The script needs 20 minutes to finish the execution. The 25 most important fields that RFE returns are:
"bs_000", "cn_004", "cs_002","cn_000", "dn_000", "ay_008", "ba_005", "ee_005", "bj_000", "az_000", "al_000", "am_0", "ay_003", "ci_000", "ba_007", "aq_000", "ag_002", "ee_007", "ck_000", "bc_000", "ay_005", "ba_002", "ee_000", "cm_000", "ai_000"
From the script execution, we can obtain a filtered dataset with these 25 fields. The ensemble associated with this filtered dataset has a phi coefficient of 0.815. The phi coefficient of the ensemble that uses the original dataset was only a bit higher, 0.824. That sounds good!
As we have seen, Recursive Feature Elimination is a simple but powerful feature selection script with only a few parameters, serving as a very useful way to get an idea of which features are actually contributing to our model. In the next post, we will see how we can achieve similar results using Boruta. Stay tuned!
