In the beginning…
In BigML, most of your Machine Learning adventures start by telling the platform where and how to read the data that will eventually become a well-formatted dataset to be used for training, evaluating, or making predictions, possibly after a collection of intermediate transformations. The specification of that “where and how” is encapsulated in the BigML resource called source.
In short, a source resource is a description of how to extract one or more rows from raw data to create a new dataset resource.
A source describes the type of the input (e.g., an uploaded or a remote file), and its format (e.g., a table provided as CSV data), including any relevant details on how to parse and extract fields and rows from that raw data (e.g., what strings represent missing values, what locale is used for numbers, what format for date-time values, and so on). Most of the time, those details are guessed by the platform by peeking at a sample of the data, but you have a chance to refine or correct wrong guesses before starting the actual extraction of the full dataset.
Up until now, sources in the platform had only one format: they always referred to tabular data. That is, they always had the table format. For these table sources, there is a direct way of creating a dataset, with each row in the table giving rise to a row or instance in the dataset.
But with the inclusion of image support in BigML, we’ve introduced a new source format: besides a table, a source can also be an image. That means that we have added the ability to extract fields from images, from simple things like their dimensions or filename, to sophisticated numeric parameters describing them, like wavelet coefficients or color histograms. However, unlike tables, each image will allow extracting just a single row when constructing a dataset.

Now, if you have, say, a thousand images and create a thousand image sources with them, and want to extract a single dataset from those sources, a brute-force approach would be creating a thousand one-row datasets and merging them into one. But that is both inefficient and inconvenient, not to mention inelegant; we clearly need a better way. Enter composite sources.
Turtles all the way down
A possible way of solving our thousand images problem above would be to allow creating a dataset from a collection of sources. But we have an even better abstraction at our disposal, namely, allowing the creation of a new source from a list of existing ones. If a collection of sources is also a source, we can immediately create a dataset from it, maintaining the one source-one dataset correspondence.
We call this new type of source, created as a collection of other sources, a composite. Each of the sources inside a composite is called a component. Composites are fully general: they can contain any other source type, not just image sources (even other composites!).
If all the components of a composite have compatible fields, the composite source will inherit those fields, as well as the format of the components. Thus, if we put together any number of image sources, the composite will have the format image and have the fields we extract from each individual image.
When you create a dataset from a composite with fields, rows will be extracted from each of its components and concatenated together in the new dataset. Thus, if you put together those one thousand image sources in a composite and create a dataset from the latter, it will have a thousand rows, one per image. Or, as another example, if you put in a composite a table source of 10,000 rows and a second one with the same columns and 5,000 more rows, the resulting composite will also have the same columns, and it will yield a dataset of 15,000 rows.
Here’s a sneak preview of our forthcoming release, where we select three table sources with the same columns to create a composite:
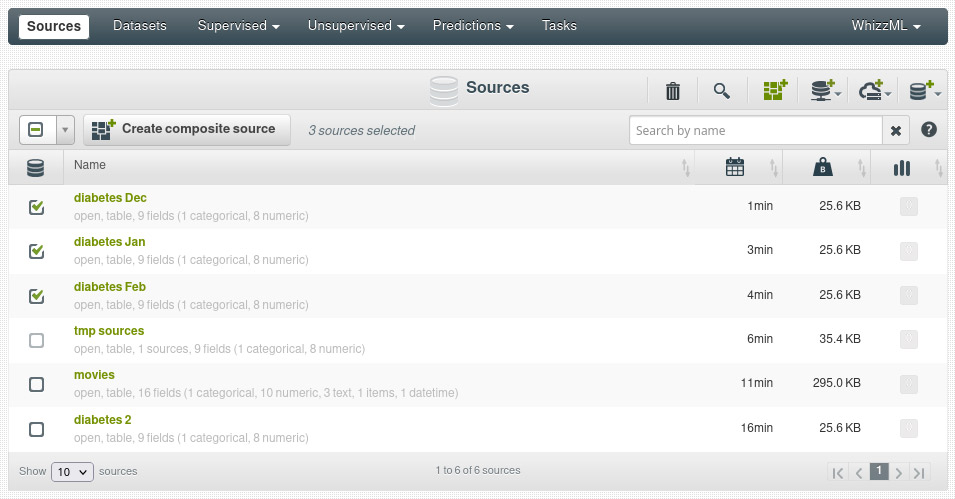
and as result we get a new source that contains the other three:
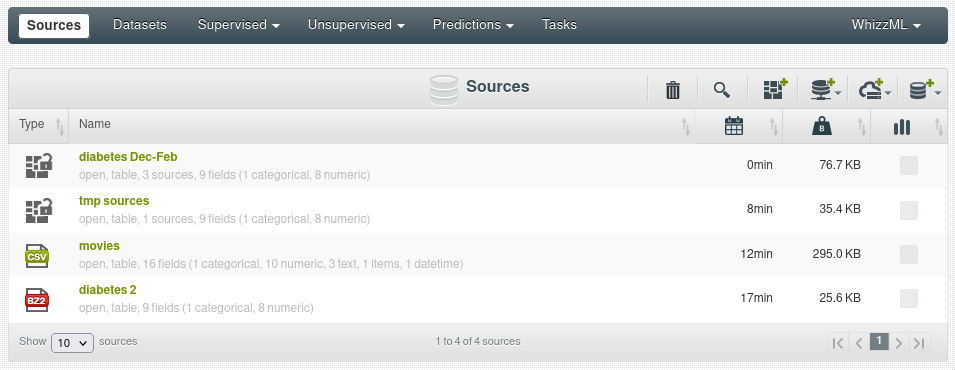
We can see that the new source has inherited the format (table) and fields from its components:
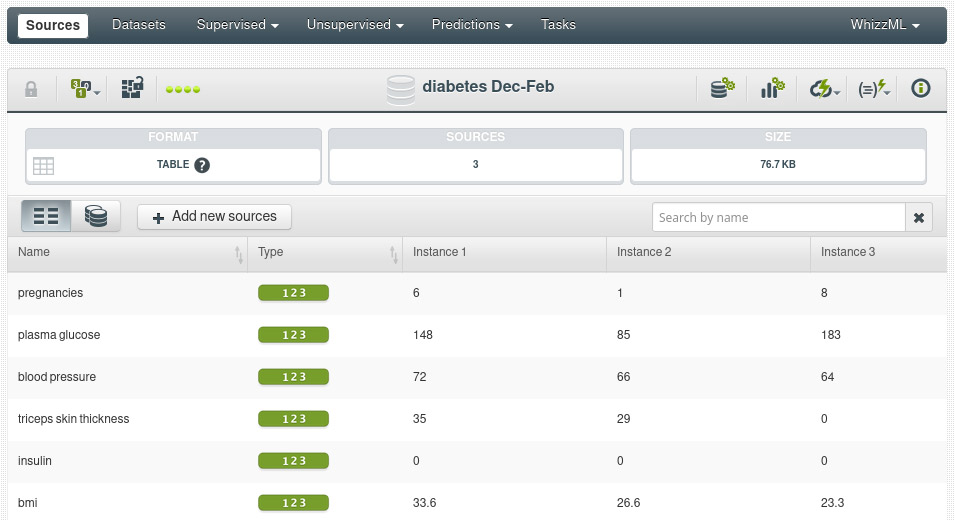
We can also inspect the list of components in the next tab of the composite view:
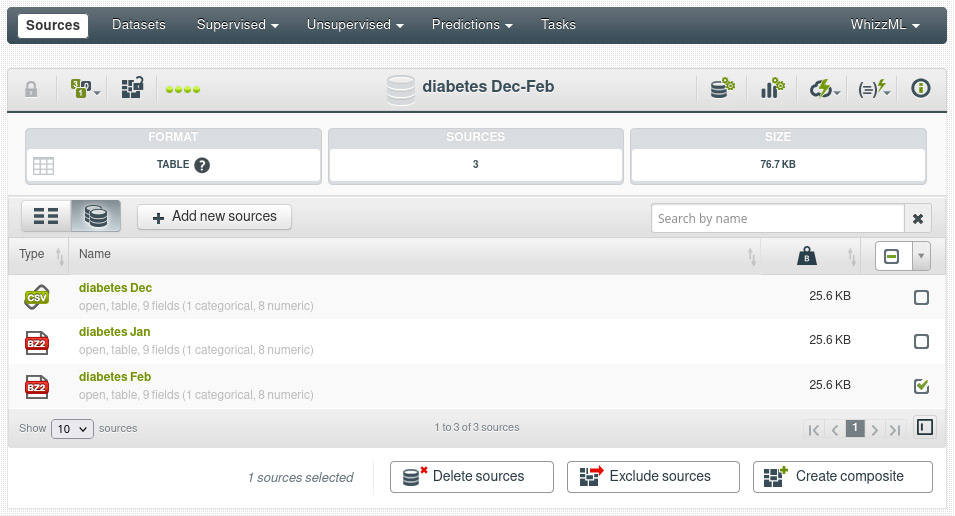
You can see in the last screenshot a collection of new controls to manipulate the composite. More on that in the next section. As with any other resource in BigML, all the operations shown here for creating and manipulating composites using the UI are also available in our API and WhizzML, with even more flexible operations. You will see some extended explanations in future blog posts.
When you have dozens or hundreds of little components to put together in a composite, as is typical for instance in the image analysis domain, having to add them one by one as sources might still be a chore if you are not using any of our bindings. To facilitate that use case, we have extended how the platform ingests ZIP files containing more than one file: we open the ZIP (or tar) file, and for each file found inside we create a source and, finally, put all those new sources together in a composite. That way you can create your composites with a single upload.
Mutant power
As you have surely noted in our previews above, composites are editable: one can add new components and remove existing ones, and it is also possible to share sources between composites. In practical terms, that allows maintaining an evolving amount of data in a tidy, centralized fashion.
However, if you are already a BigML user, you should start worrying at this point: how about our much touted traceability? If today I create a dataset and a model from a composite and tomorrow I add to the latter a new source, haven’t I lost the traceability of that dataset back to its source? That would be a serious problem indeed, and we don’t really allow that workflow. To add new data to the composite tomorrow, we will need to clone the old one, so that the existing dataset and model don’t lose the tie to their original parent. Let’s see how that works in a bit more detail.
A newly created composite is open: that means that it can be edited and its contents modified with ease. In other words, an open composite is fully mutable. At any moment, we can decide to manually close an open composite. From that point on, it becomes an immutable resource and cannot be modified anymore. Also, if you create a dataset from an open composite, it’s automatically closed for you, and you won’t be able to modify it anymore.
With this release, we extend the open/close functionality to all types of sources, not only composites. That way, full immutability, traceability and reproducibility are therefore ensured for all resources end-to-end.
But how about the nice use case of a new source arriving tomorrow? How do we add it to our now closed, immutable composite?
Doppelgangers
To solve the conundrum and support our evolving source use case, we have added a new feature to our image resources: (almost) instant cloning. You can clone any source, including composites, at any moment (regardless of whether it’s open or closed) and new clones are always open. So in our use case above, when a new source arrives tomorrow, we just add it to a fresh clone of our composite, which becomes our new version of the resource until we decide to close it, perhaps by creating a dataset from it.
Again, this behavior is not exclusive to composites: all source formats are easily clonable and will be closed upon the creation of a dataset. You can also close them explicitly. But, to preserve backward compatibility, all your existing table sources are open by default (and therefore still mutable), until you create a new dataset with them.
Wrapping up
As you see, our image support release has brought significant improvements to general source handling in BigML:
- A new source format beyond tabular data: (single) image sources (with new formats, like video, PDF or sounds already planned).
- A new type of source, the composite, consisting of an arbitrary collection of other sources and behaving like a regular source for dataset creation purposes.
- The ability to mutate composites and other sources while maintaining full reproducible workflows and immutability thanks to the new open/close source property.
You will see all those features working together in earnest with image composites first, but we are sure you’ll also find many other ways of putting them to work in other Machine Learning workflows too!
Do you want to know more about Image Processing?
Be sure to register for our upcoming webinar that will take place on Wednesday, December 15, 2021, where we will present the latest and unique implementation of Image Processing in the BigML platform. You can also visit the dedicated Image Processing release page to learn about this new feature, what makes it different and special, and find out the wide variety of use cases that can be tackled with Image Processing, as well as how to work with your image data in the BigML platform.
