In this second post of our series, we’ll cover a use case example. Least squares linear regression is one of the canonical algorithms in the statistical literature. Part of the reason for this is that it’s very good as a pedagogical tool. It’s very easy to visualize, especially in two dimensions, a line going through a set of points, and the distances from the line to each point representing the error of the classifier. Kind people have even created nice animations to help you:

And herein, we have machine learning itself in a nutshell. We have the training data (the points), the model (the line), the objective (the distances from point to line) and the process of optimizing the model against the data (changing the parameters of the line so that those distances are small).
It’s all very tidy and relatively easy to understand . . . and then comes the day of the Laodiceans, when you realize that not every function is a linear combination of the input variables, and you must learn about gradient trees and deep neural networks, and your innocence is shattered forever.
Part of the reason to prefer these more complex classifiers to simpler ones like linear regression (and its sister technique for classification, logistic regression) is that they are often generalizations of the simpler techniques. You can, in fact, view linear regression as a certain type of neural network; specifically one with no hidden layers, non-linear activation functions, or fancy things like convolution and recurrence.
So, then, what’s the use in turning back to linear regression, if we already have other techniques that do the same and more besides? Answers to this question often come in two flavors:
- You need speed. Fitting a neural network can take a long time whereas fitting a linear regression is near-instantaneous even for medium-sized datasets. Similarly for prediction: A simple linear model will, in general, be orders of magnitude faster to predict than a deep neural network of even moderate complexity. Faster fits let you iterate more and focus on feature engineering.
- You have small training data. When you don’t have much training data, overfitting becomes more of a concern; complex classifiers may fit the data a bit better, but if you have small training data, your test sets are very small and so your estimates of goodness of fit become unreliable. Using models like linear regression reduces your risk of overfitting simply by giving you less variables to fit.
We’re going to focus on the second case for the rest of this blog post. One way of looking at this is the classic view in machine learning theory that the more parameters your model has, the more data you need to fit those properly. This is a good and useful view. However, I find it just as useful to think about this from the opposite direction: We can use restrictive modeling assumptions as a sort of “stand in” for the training data we don’t have.
Consider the problem of using a decision tree to fit a line. We’ll usually end up with a sort of “staircase approximation” to the line. The more data we have, the tighter the staircase will fit the line, but we can’t escape the fact that each “step” in the staircase requires us to have at least one data point sitting on it, and we’ll never get a perfect fit.
This is unfortunate, but the upside is loads of flexibility. Decision trees don’t care a lick whether the underlying objective is linear or not; you can do the same sort of staircase approximation to fit any function at all.
Using linear regression allows us to sacrifice flexibility to get a better fit from less data. Consider again the same line. How many points does it take from that line for linear regression to get a perfect fit? Two. The minimum error line is the one and only line that travels through both points, which is precisely the line you’re looking for. No, we can’t fit all or even most functions with linear regressions, but if we restrict ourselves to lines, we can find the best fit with very little data.
Linear Regression: More Power
Some of you may find the reasoning implied above to be a bit circular: “You can learn a very good model using linear regression, provided that you know in advance that a line is a good fit to the data.” It’s a fair point, but it can be surprising how often you find that this logic applies. It’s not odd to have a set of features, where changes in those features induce directly proportional changes in the objective, simply because those are the sorts of features amenable to machine learning in general. And in fact, these sorts of relationships abound, especially in the sciences, where linear and quadratic equations go much of the way towards predicting what happens in the natural world.
As an example, here’s a dataset of buildings that has measurements of the roof surface area and wall surface area for all of them, and the heat loss in BTUs for the building. Physics tells us that heat loss is proportional to these areas, and you break them out into roof and wall surface areas because those things are insulated differently. The dataset also has only 12 buildings, so we’ll use nine for training and three for test. Is it possible to get a reasonable model using so little data?

If we try a vanilla ensemble of 10 trees, we get an r-squared on the holdout set of 0.85. This isn’t bad, all things considered! Again, we’ve only got nine training points, so something so well-correlated to the objective is pretty impressive.
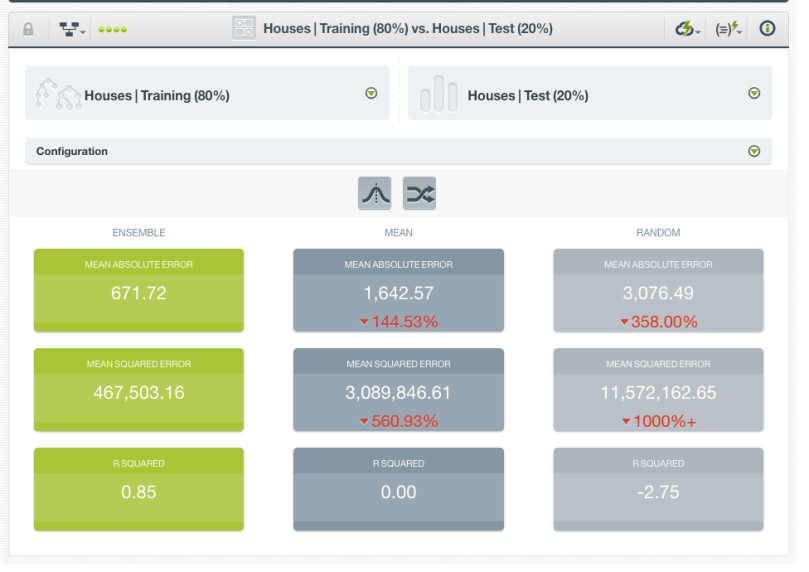 Now, let’s see if we can do better by making linear assumptions. After all, we said at the top that heat loss is, in fact, proportional to the given surface areas. Lo and behold, linear models serve us well: We are able to recover the “true” model for heat loss through a surface near-exactly.
Now, let’s see if we can do better by making linear assumptions. After all, we said at the top that heat loss is, in fact, proportional to the given surface areas. Lo and behold, linear models serve us well: We are able to recover the “true” model for heat loss through a surface near-exactly.

One caveat here is that you’re only evaluating on three points, so it’s hard to know if the performance difference we see is significant. We might want to try cross-validation to see if the results continue to hold. However, Occam’s razor principle implores to choose the simpler model even if their performances are equal, and prediction will be faster to boot.
Old Wine in New Bottles
Yes, linear regression is somewhat old-fashioned, and in this day and age where datasets are getting larger all the time, the use cases aren’t as many as they used to be. We make a mistake, though, to equate “fewer” with “none”. When you’ve got small data and linear phenomena, linear regression is still queen of the castle.
