As part of our release for Data Transformations, we have outlined both a use case and how to execute the newly available features in the BigML Dashboard. This installment demonstrates how to perform data transformations by calling the BigML REST API. In any machine learning workflow, data transformations tend to be one of the most time consuming, but entirely essential, tasks. BigML transformations enable this process to be more seamlessly integrated with the modeling process, keeping aligned with the mission of BigML to make Machine Learning simple and accessible. Access to BigML.io requires authentication and now is a good time to follow these steps if you have not done so already.
Inspection of the dataset
If you are not familiar with Black Friday, it refers to the day after Thanksgiving in the United States, which is traditionally one of the busiest days of the year for retailers and kicks off the profitable holiday shopping season. For this tutorial, we are making use of a dataset that can be found and downloaded on Kaggle and consists of more than 500,000 observations of shopping behavior. We have sampled from this original source to create a dataset in BigML consisting of 280,889 instances. The 12 fields in the dataset include:
- User ID: 5,891 distinct customers
- Product ID: 3,521 distinct products
- User demographics: gender, age, occupation, and marital status
- Geographic information: city category, stay in current city
- Product information: product category and purchase amount

Question: What factors are most indicative of a high spending customer?
Being able to reliably identify individuals with high spending is a frequent and critical task for data-savvy marketers. To answer this question, there are a series of data transformation steps that we will need to perform before training and evaluating supervised Machine Learning model.
- Group the dataset according to User ID
- Calculate total amount of spending per individual
- Join the User ID-aggregated dataset with the original dataset to include relevant demographic information
- Determine a threshold for “high spending” that seems reasonable
- Build a predictive model that discriminates between high spending and low spending customers
- Inspect the feature importance of the model
Grouping of the dataset by User ID can be accomplished by using the aggregate function in the Dashboard and the equivalent SQL query in the API. This will result in a new dataset named “User ID Grouped” that consists of 5,891 instances and four total fields: “User ID”, “count_Purchase”, “sum_Purchase”, and “avg_Purchase”.
curl "https://bigml.io/dataset?$BIGML_AUTH" \
-X POST \
-H 'content-type: application/json' \
-d '{"origin_datasets": ["dataset/5bcb47d4b95b397eec000066"],
"origin_dataset_names": {"dataset/5bcb47d4b95b397eec000066":"A"},
"name":"User ID Grouped",
"sql_query": "SELECT A.User_ID, count(A.Purchase) AS count_Purchase,
sum(A.Purchase) AS sum_Purchase, avg(A.Purchase) AS avg_Purchase
FROM A GROUP BY A.User_ID"}'
Because the newly created dataset does not include the interesting demographic information, we perform a join with the original data in order to add this information for each of the new instances. The fields that we are most interested here are those that define and describe the individual shoppers, not the products. To do this, we will execute three consecutive commands (shown in the image below). The first will keep the fields that we are interested in for this question. The second will remove duplicates. And finally, the third will join this dataset with our dataset about cumulative purchase behavior (“User ID Grouped”).
curl "https://bigml.io/dataset?$BIGML_AUTH" \
-X POST \
-H 'content-type: application/json' \
-d '{"origin_datasets": ["dataset/5bcb47d4b95b397eec000066"],
"origin_dataset_names": {"dataset/5bcb47d4b95b397eec000066":"A"},
"name":"User ID Demographics",
"sql_query": "SELECT A.User_ID, A.Gender, A.Age,
A.Occupation, A.City_Category, A.Stay_In_Current_City_Years,
A.Marital_Status FROM A"}'
curl "https://bigml.io/dataset?$BIGML_AUTH" \
-X POST \
-H 'content-type: application/json' \
-d '{"origin_datasets": ["dataset/5bcde92db95b397edd000036"],
"origin_dataset_names": {"dataset/5bcde92db95b397edd000036":"A"},
"name":"User ID Demographics [No Duplicates]",
"sql_query": "SELECT DISTINCT * FROM A"}'
curl "https://bigml.io/dataset?$BIGML_AUTH" \
-X POST \
-H 'content-type: application/json' \
-d '{"origin_datasets": [
"dataset/5bcdeed0b95b397ee200007e",
"dataset/5bcdff1cb95b397eec00009a"],
"origin_dataset_names": {
"dataset/5bcdeed0b95b397ee200007e": "A",
"dataset/5bcdff1cb95b397eec00009a": "B"},
"name":"DATA JOINED",
"sql_query":
"SELECT A.*, B.*
FROM A LEFT JOIN B ON A.User_ID = B.User_ID"
}'
By visually inspecting the “sum_purchase” field of our new dataset, we can see that it approximately follows a power law distribution. Rather than build a model that predicts the exact amount of spending, we are more interested in binning customers into groups of “low”, “high”, and “medium” total spending.
curl "https://bigml.io/dataset?$BIGML_AUTH" \
-X POST \
-H 'content-type: application/json' \
-d '{"origin_dataset": "dataset/5bce154ab95b397eec0000a4",
"new_fields": [{
"field": "(cond (< (f \"sum_purchase\") 100000) \"LOW\"
(cond (< (f \"sum_purchase\") 500000) \"MEDIUM\" \"HIGH\"))",
"name":"Discrete_Spending_Sum"}]}'
At this point, our data is in a Machine-Learning ready format. We can build a classifier that predicts whether a user is in the category “LOW”, “HIGH”, or “MEDIUM” based on the “Occupation”, “Age”, “Gender”, “Marital_Status”, “City_Category”, and “Stay_In_Current_City_Years”. For more information on how to train and evaluate models, you can consult the API documentation or previous API tutorials. We will jump ahead to view the feature importance of an ensemble classifier trained on this data.
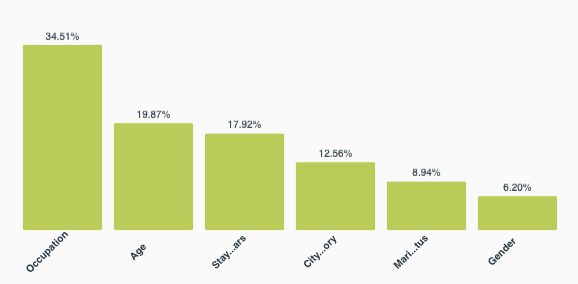
Analyzing the results
It appears that the most important fields for determining high spending are occupation (34.51%), followed by age (19.87%), and “stay in current city” (17.92%). Marital status and gender appear to contribute far less when determining who is a large spender. Considering that this dataset codes for 21 distinct occupations, there is ample opportunity to find additional correlations between spending habits and specific occupations in order to improve or personalize marketing efforts.
With SQL style queries, there are virtually limitless transformations and interrogations you can make for your dataset. You can reference our API documentation to find more examples and templates for how to make these queries programmatically with the BigML API.
Want to know more about Data Transformations?
If you have any questions or you would like to learn more about how Data Transformations work, please visit the release page. It includes a series of blog posts, the BigML Dashboard and API documentation, the webinar slideshow, as well as the full webinar recording.
