BigML’s new release is here! Join us on Thursday, October 25, 2018, at 10:00 AM PDT (Portland, Oregon. GMT -07:00) / 07:00 PM CEST (Valencia, Spain. GMT +02:00) for a FREE live webinar to discover the new Data Transformation options added to the BigML platform, which will yield better results in your projects by simplifying a key part of any Machine Learning workflow.
![]()
In previous releases, BigML has focused on presenting a wide range of choices on new algorithm implementations and automation to help you solve a wide array of Machine Learning problems. Now, with the Data Transformations release, we reach an important milestone in our roadmap by enhancing our offering in the area of data preparation as well. Typically, data do not come in a format ready to start working on a Machine Learning project right away. Data from many different sources come in different formats, and with plenty of information that does not add any value for the algorithm that will learn from it. Therefore, preparing your data for your Machine Learning project is a key part of the process to obtain the best predictive model.
Although BigML already offers several automatic data preparation options (missing values treatment, categorical fields encoding, date-time fields expansion, NLP capabilities, and even a full domain-specific language for feature generation), we knew we still had more tools to add for full-fledged feature engineering within the platform. That is why BigML is adding new capabilities that greatly expand the functionality related to prepare your Machine Learning-ready dataset. The latest version of BigML lets you perform SQL-style queries over your datasets, significant improvements of the editor used to write feature generators in Flatline (our feature engineering DSL), and new ways of further improving feature engineering.
![]()
Up to now, the main ways of transforming datasets were sampling, filtering, and the addition of new fields. All of them work by scanning the input dataset and performing actions based on a finite number of rows at once. However, you cannot perform global operations like ordering, joins, or aggregations in this fashion. In this release, we introduce SQL-like queries that are able to perform such global transformations, among others. This set of operations is crucial for transforming the data you have into the data you actually need. With queries, you will be able to aggregate instances of your dataset, join datasets, as well as merge them. You can also easily execute your queries in a few clicks as you have the full power of SQL at your disposal through the BigML REST API. There’s more: the Dashboard will shortly support other capabilities like ordering instances, removing duplicates, and more!
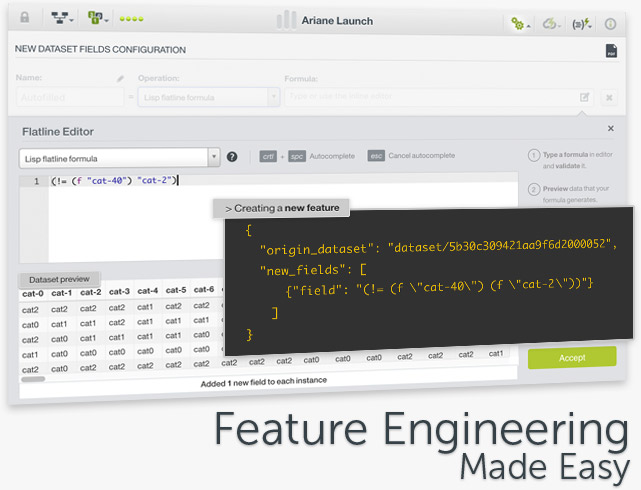
The BigML Flatline Editor has been upgraded to easily help you create new fields and validate existing Flatline expressions in your Dashboard in an even more friendly editor. For new BigML users who are not familiar with the term, Flatline is BigML’s domain-specific language for data generation and filtering, which helps you transform your datasets and engineer new features in a wide variety of ways. Apart from the Flatline editor, we also offer some common predefined operations from the Dashboard that allow you to create new features with a few clicks instead of writing formulas. Finally, we are adding sliding windows, one of the most common feature engineering techniques used in Machine Learning. Sliding windows are frequently applied to frame time series data by using previous data points to predict the next data points, e.g., sales for product X in the last rolling 14 days.
Do you want to know more about Data Transformations?
If you have any questions or you would like to learn more about how Data Transformations work, please visit the release page. It includes a series of blog posts, the BigML Dashboard and API documentation, the webinar slideshow, as well as the full webinar recording.
