The BigML Team is bringing Fusions to the BigML platform on July 12, 2018. As explained in our introductory post, Fusions are a supervised learning technique that can be used to solve classification and regression problems. Fusions combine multiple Machine Learning models (decision trees, ensembles, logistic regressions, and/or deepnets) and average their predictions. Fusions rely on the same principle of ensembles that the combination of several models often outperform the individual models it is composed of.
In this post, we will take you through the four necessary steps to train, analyze, evaluate, and predict with a Fusion using the BigML Dashboard. We will use the data of the for sale homes in Corvallis, Oregon from the Redfin search engine. You can find the full dataset in the BigML Gallery. We want to predict the home prices using as inputs the home characteristics in the dataset (size, number of bedrooms, baths, etc.). We filtered from the dataset the houses with a higher price than $600,000 because there were eight outlier houses with very high prices that could introduce noise to our models.

1. Create a Fusion
To create a Fusion you need at least one existing model (decision tree, ensemble, logistic regression or deepnet). In this case, we already trained an ensemble and a deepnet, each of them yielded an R squared of 0.77 and 0.78, respectively. The main goal is to improve these single model performances by creating a Fusion.
You can create a Fusion using multiple options, which are listed below so you can select the one that best fits your needs:
- If you want to start by selecting one model, click the “Create Fusion” option from the 1-click menu.
- If you prefer to select multiple models at the same time you can do it from the model list and then click the “Create Fusion” button.
- If you want to select multiple models that belong to an OptiML, you can do it from the OptiML model list.
In this case, we are using the first option:
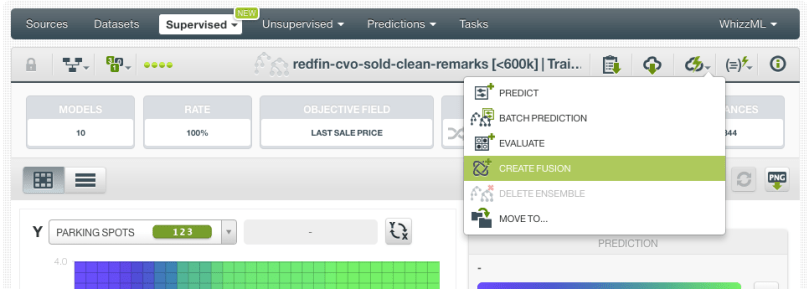
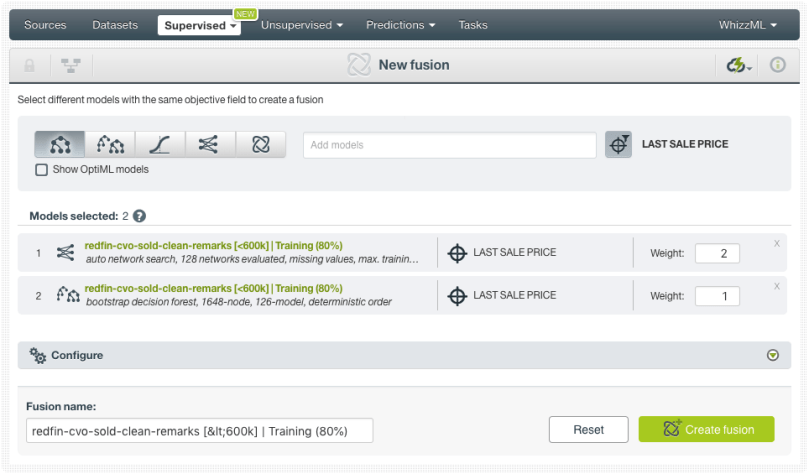
Any of these options will redirect you to the New Fusion view (see image below). From this view you will be able to configure a set of options:
- See the models selected, select more models or remove them. All the models must have compatible objective fields. That’s why BigML sets the first selected model objective field name as a filter so you can only select models with the same objective field name. However, you can remove this filter in case two models have the same objective field but different names.
- Assign different weights to the selected models. At the prediction time, BigML will use these weights to make a weighted average of the model predictions.
- Map your model fields with the Fusion fields in case two models have the same field but they have different names.
In this example, we are selecting our two models, the ensemble and deepnet, to create the Fusion. Since the deepnet seems to perform a bit better than the ensemble, we are giving it a weight of 2. This means that the deepnet will have two times more impact than the ensemble in the Fusion predictions.
To make sure your Fusion improves the single model performances, you need to select high-performing models that are as diverse as possible. If you use several identical models or models with sub-par performance, the Fusion will not be able to improve on the results of the component models.
2. Analyze your Results
When the Fusion is created, you will be able to inspect the results in a Partial Dependence Plot (PDP). The PDP allows you to view the impact of the input fields on the objective field predictions. You can select two different input fields for both axes and the predictions are represented in different colors in a heat map format.
You can see below how the square feet and the parking spots impact the predictions: higher values for both measures results in a much higher price.

BigML also calculates the field importances for your Fusion as we do for other supervised models (except for logistic regressions). The Fusion field importances are calculated by averaging the per-field importances of each single model (decision trees, ensembles, and deepnets) composing the Fusion. If your Fusion only contains logistic regressions, the field importances cannot be calculated. In our case, you can see below that, by and large, the most important field to predict the house prices is the square feet (66%).

3. Evaluate your Fusion
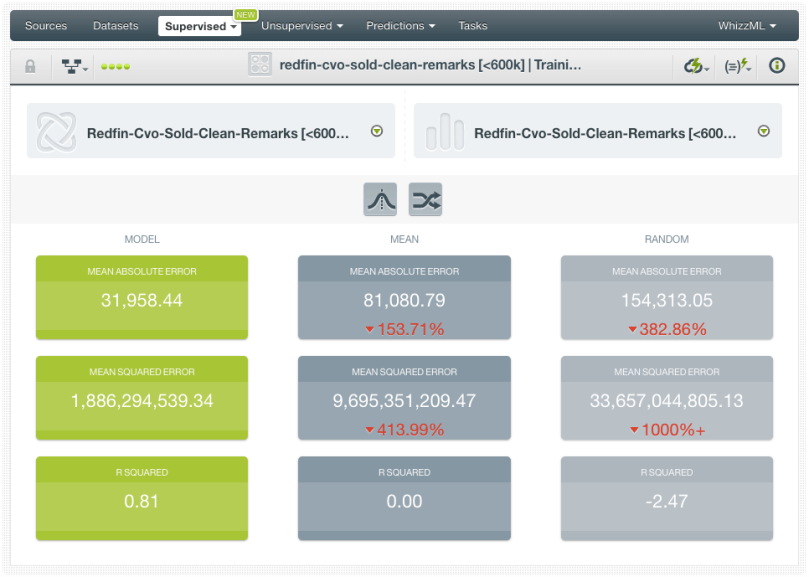
After analyzing our Fusion, we need to evaluate it with a dataset that has not been used to train the models similar to other supervised learning models. The performance measures for Fusions are the same as any other classification or regression model.
In our case, we evaluate by using the same dataset that we used to evaluate our ensemble and deepnet so the results are comparable. This happens to be a holdout set containing the 20% of the instances of our original dataset. In the end, we were able to achieve an R squared of 0.81 which is higher than the one we obtained for our single models (the deepnet was the most performant with a maximum of 0.78). You may think that the difference in performance is quite small. Although this may not be true for other use cases, it is not unusual to find only small gains in performance using Fusions. In most problems, the biggest gains in performance usually come from feature engineering or adding more data rather than solely from model configuration. However, to the extent that every % point in model accuracy and performance measures count, Fusions can be a quick solution to squeeze the juice further because they are so easy to execute on BigML.
4. Make Predictions
Predictions work for Fusions exactly the same as for any other supervised method in BigML. You can make predictions for a new single instance or multiple instances in batch fashion.
Single predictions
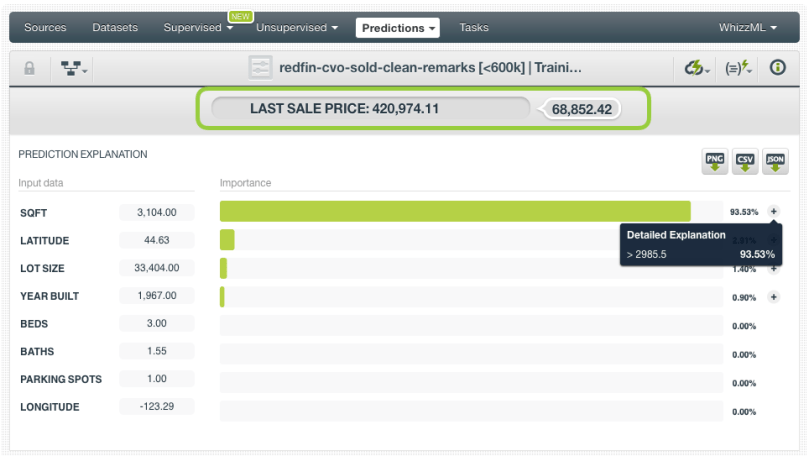
Click on the Predict option from your Fusion view. A form containing all your input fields will be displayed and you will be able to set the values for a new instance. Before clicking the Predict button, you can also enable the prediction explanation option. By using this option, you will obtain the importance of each input data in your prediction.
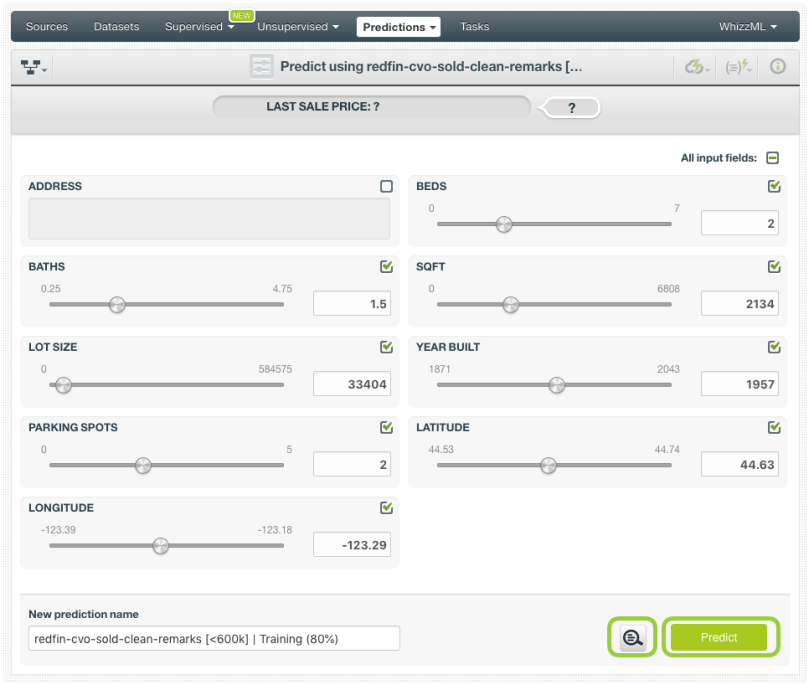
At the top of the view, you will get the prediction along with the expected error (for numeric objective fields) or the class probabilities (for categorical objective fields). Below the prediction, you can see the histogram with the field importances for this prediction. In this case, the most important field is the square feet (94%) because it is less than 2,986.
Batch predictions
If you want to make predictions for multiple instances at the same time, click on the Batch Prediction option and select the dataset containing the instances for which you want to know the objective field value.
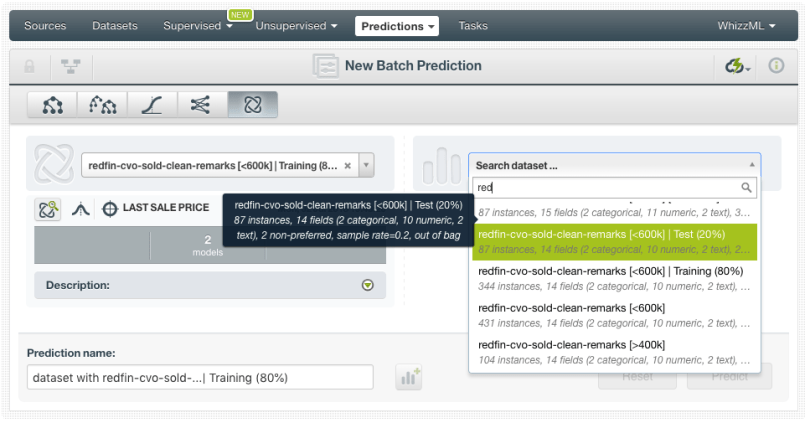
You can configure several parameters of your batch prediction like the possibility to include all class probabilities in the output dataset and file. When your batch prediction finishes, you will be able to download the CSV file and see the output dataset.
Want to know more about Fusions?
Stay tuned for the next blog post to learn how to use Fusions programmatically with the BigML API. If you have any questions or you would like to learn more about how Fusions work, please visit the release page. It includes a series of blog posts, the BigML Dashboard and API documentation, the webinar slideshow as well as the full webinar recording.
