
July 5, 2018 3:26 pm
The results of many Machine Learning competitions, perhaps most famously the Netflix prize, have demonstrated that a combination of models often yields better performance than any single component model. The techniques used to aggregate multiple models go by several terms depending on the precise methodology, and include boosting, bagging, and stacking. At their core, the efficacy of such methods can be attributed to being able to somewhat mitigate the inherent performance costs due to bias-variance tradeoff. More colloquially, these methods are based on the same principle that guides the “wisdom of the crowd,” in which the collective opinion of a group tends to provide superior estimations than that of a single expert. In order to easily take advantage of this phenomenon, we have introduced Fusions to the supervised Machine Learning options available at BigML.
This blog post, the second in a series of 6 posts exploring Fusions, illustrates how Fusions can be applied to improve Machine Learning performance. For that, we will use a dataset of wine quality.
The dataset is available for download at both Kaggle and the UCI machine learning repository. This dataset consists of 1599 examples of wine samples, each characterized by 12 different variables of chemical properties of wine, including measurements such as pH, citric acid, and residual sugar. The objective field in this data set is wine quality, which ranges in value from 0 (low quality) to 10 (top quality), with most values falling at an intermediate level. Our task will be to treat this data as a regression problem in which we predict the quality score as accurately as possible using only these chemical properties. Unfortunately, the true identity or price point of the wines in this dataset are not available.
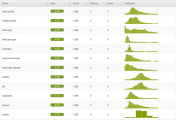
Overview of the fields included in the wine quality dataset
One way that Fusions can be used to improve the overall predictive performance is by combining different types of models. To demonstrate the concept, we split our dataset into training (80%) and test (20%) sets and trained both a deepnet and an ensemble decision tree, before combining the two into a Fusion and evaluating on the test set.
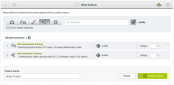
BigML Dashboard view for creating a new Fusion from existing models
Regression models in BigML can be evaluated using Mean Absolute Error (MAE), Mean Square Error (MSE) and R-Squared (R2), and all 3 are included in the table comparing evaluation metrics below. While the improvement is not dramatic, the simple process of aggregating the two weaker models into a Fusion yields a predictive model with superior performance with regards to both MSE and R2, and essentially equivalent performance in terms of MAE.
|
MAE |
MSE |
R2 |
|
|
Ensemble |
0.46 |
0.44 |
0.35 |
|
Deepnet |
0.50 |
0.41 |
0.39 |
|
Fusion |
0.47 |
0.39 |
0.42 |
Fusions can be created from models as long as the objective fields are identical. There is no requirement for the same training data to be used for the component models, as illustrated in the previous examples. In this scenario, let’s consider two models created from different sets of features, one being a simple univariate regression that consists of solely the most important field, “alcohol”, according to our previous Fusion model, and another trained using the remaining 11 variables.
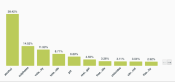
Field importance for the Fusion model previously created
In this case, we found that both the “Alcohol Only” and the “No Alcohol” models perform modestly, but as components of a Fusion, these relatively poor models have a performance on par with an optimized deepnet. While the result of this example may seem trivial given what we have already learned about this fairly straightforward dataset, it illustrates the flexibility in deploying Fusions in scenarios where existing models ingest different forms of training data for a common objective.
|
MAE |
MSE |
R2 |
|
|
Alcohol Only |
0.58 |
0.56 |
0.17 |
|
No Alcohol |
0.54 |
0.66 |
0.02 |
|
Fusion |
0.50 |
0.43 |
0.36 |
If Fusions can improve the performance of two simple models, the next logical step is to evaluate how much optimized models can be improved. Using OptiML, we generate a variety of top performing models in a single click, and select any of the results to combine into a Fusion model. In this case, we will use all 9 of the OptiML-generated models, which include 6 different ensemble tree models and 2 different deepnets.
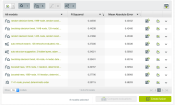
Creation of a Fusion using all models generated from OptiML
The Fusion created from the OptiML models yielded a MSE of 0.36 and an R squared value 0.47 when evaluated against our held out test set. This performance is not only greater than the other Fusions we created, but also is better than any of the 9 component models generated by OptiML. It quickly becomes apparent that chaining OptiML and Fusions together in a Machine Learning workflow simplifies the complicated iterative process of model tuning and aggregation into a concise and straightforward pipeline.
Machine Learning performance will almost largely depend on the quality of training data and the ingenuity involved in feature engineering, rather than the sophistication of the models themselves. Regardless, in applications where narrow margins in predictive performance matter greatly, aggregating the results of multiple models can often provide a much desired improvement in performance metrics. In your next Machine Learning project, we encourage you to use the power of BigML Fusions to combine the various models you may have created along the way and see if it yields an overall more reliable and accurate result.
Stay tuned for the next blog post to learn how to use Fusions with the BigML Dashboard. If you have any questions or you would like to learn more about how Fusions work, please visit the release page. It includes a series of blog posts, the BigML Dashboard and API documentation, the webinar slideshow as well as the full webinar recording.
Posted by gregoryantell
Categories: Decision trees, Deepnets, Ensembles, Fusions, Logistic Regression, Release, Webinar
Tags: 2018, BigML Fusions, Deepnets, Ensembles, Fusions, logistic regressions, models, Release, spring
Mobile Site | Full Site
Get a free blog at WordPress.com Theme: WordPress Mobile Edition by Alex King.