The effective use and adoption of Machine Learning requires algorithms that are not only accurate, but also understandable. To address this need, BigML now includes functionality that allows for Prediction Explanation, model-independent explanations of classification and regression predictions. In this post, we will summarize what it means for a prediction to be “explainable,” why this is important, and share a use case in which prediction explanation plays a key role.
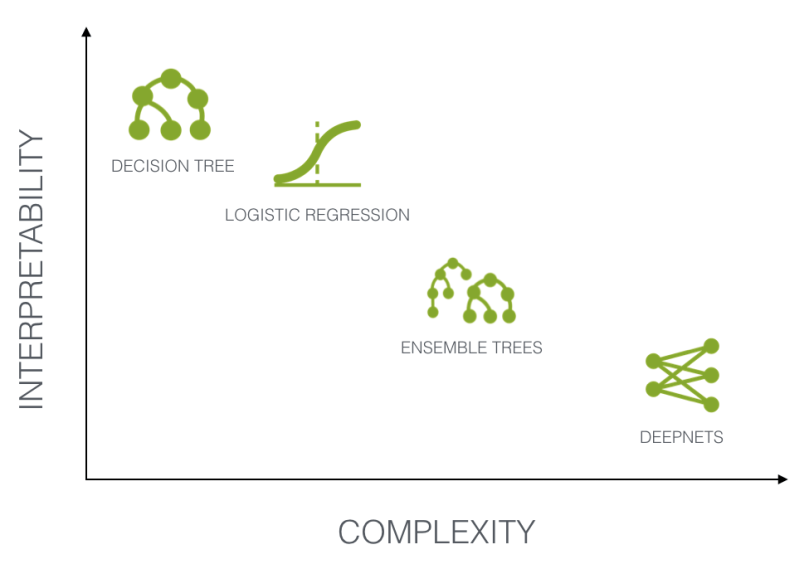
Rather than being hard-programmed with an exhaustive set of “if-then” rules, Machine Learning algorithms “learn” rules based on large datasets of examples. Understanding what these rules are, and how they are applied to new data, is generally referred to as the interpretability or explanation of the model. While less complex (high bias) algorithms are generally based upon more extensive underlying assumptions about the structure of the data being evaluated, and therefore are typically somewhat interpretable, more complex models such as neural networks are increasingly utilized despite functioning largely as a “black box.”
Why Now?
The far-reaching consequences of adopting Machine Learning algorithms for predictive applications involving human behavior and decision making has contributed to a paradigm shift in attitude within the European Union, resulting in the establishment of the General Data Protection Regulation (GDPR) effective May 25, 2018. While much of this regulation is focused on the protection and storage of personal data, GDPR also includes a “right to explanation” with regard to Machine Learning algorithms applied to data of EU citizens. The legal implications of this regulation remain murky, but one component is clear: those in charge of designing and implementing Machine Learning algorithms that affect human subjects are also responsible for understanding and explaining how they work.
The underlying logic of a Machine Learning algorithm can be understood on two levels: global explanations and local explanations.
- A global explanation refers to how a particular algorithm functions in general, which can be a challenging task for methods such as deep neural networks. For decision tree models, global variable importance directly relates to the depth and frequency of split points for each variable.
- In contrast, local explanations identify which specific variable contributed to an individual decision, an increasingly critical requirement for applications dealing with human subjects and/or in highly regulated industries. It is essential to note that the most important variables in the global explanation of an algorithm do not necessarily correspond with the most important variables in a local prediction.
|
BigML Model Field Importance |
BigML Prediction Explanation |
|
Global Explanation |
Local Explanation |
|
Model dependent |
Model agnostic |
|
Assesses all predictions |
Assesses single prediction |
Understanding why a ML model provides a given prediction
When trying to understand why a Machine Learning algorithm comes to a particular conclusion, especially when that conclusion impacts an individual with a “right to explanation”, local explanations are typically more relevant. A classic example is the assessment of loan default risk. An individual applying for a loan can have an application approved or denied based on the likelihood that he or she will default on a loan. To illustrate this scenario more concretely, we will evaluate the Loan Default Risk dataset available in the BigML Gallery, using the newly launched Predictions Explanation tool. Shown below are the first five features in this dataset, although 21 fields exist overall, which consists of both categorical and numeric variables. The objective field of this dataset is the “class” field, which takes values of either “good” or “bad”.

Following a standard train-test split of the 1000 instances in this dataset, we trained three different models: a Logistic Regression, an Ensemble Tree model, and a Deepnet using the one-click functionality of the BigML Dashboard. It is essential to first check that a model is achieving some level of performance beyond random chance before investigating either field importance or prediction explanations. In this case, all three models performed fairly similarly, with an f-measure of 0.6842 for the top model, an Ensemble.
The predictions page for Ensembles was selected in order to further investigate how the trained model is working. This page allows one to manually enter or adjust values for each variable considered by the model and to view the probability or confidence of the prediction. In addition to changing the input fields, there are also options to disable particular input fields, adjust the probability threshold, and select the positive class for the objective field. While this Dashboard provides a nice tool to observe how various inputs may affect predictions and to generate predictions for a single instance of particular interest, it comes up short in ultimately explaining specifically which variables are driving the output. This is where BigML’s Prediction Explanation comes in, and can be selected at the bottom of the page:
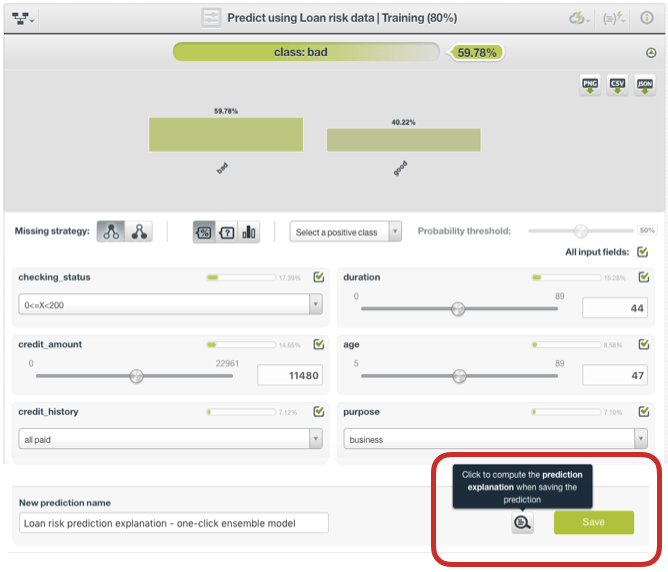
The prediction explanation represents the most important factors considered by the model in a single prediction given the input values. Each input value will yield an associated importance, with the importances across all input fields summing to 100%. The prediction explanation is calculated using the results of over a thousand distinct predictions using random perturbations of the input data. For some input fields, there exists a “+” icon next to the importance, which allows you to gather more info about the particular rule applied to the input data in achieving the final prediction. For example, in the figure below, the importance of 43.51% for the field “savings_status” is not explained by its precise value. Rather, it is because this field value is greater than 100 and less than 500.

White-box Predictions
In the past decade, we have experienced a tremendous proliferation of predictive applications utilizing Machine Learning, and this is only the beginning. Notably, many of these use cases have moved well beyond modeling physical systems and are extensively modeling nuanced human behavior and decision making. Subjecting humans to decisions made by Machine Learning algorithms is not without considerable ethical implications, a topic thoroughly examined in recent bestselling books such as Weapons of Math Destruction by Cathy O’Neil.
If you cannot explain your model’s predictions, expect pushback not only from regulators but also stakeholders. These circumstances have led to substantial “Explainable A.I.” initiatives such as DARPA funding a $6.5 million grant to Oregon State University’s College of Engineering research for making trustworthy and understandable A.I. systems, lead by Dr. Thomas Dietterich, Distinguished Professor (Emeritus) and Director of Intelligent Systems Research at Oregon State University, and Co-Founder and Chief Scientist at BigML.
In line with our ongoing efforts to lower the barriers of Machine Learning, BigML’s newest feature enables simple white-box interpretations of otherwise opaque statistical techniques. Prediction Explanation, now made beautifully simple.

One comment