 Since I currently work at a Machine Learning company, it may surprise some to find out that I am currently enrolled in Andrew Ng’s Machine Learning class thru Coursera. I am taking the class because I want to be able to have a meaningful conversation with our mysterious Machine Learning gurus at BigML. Anyhow, I am apparently not the only person interested in taking this class; the first time it ran, it had more than 100,000 students sign up. This makes it clear that lots of people want to learn more about Machine Learning. Also, that Coursera is awesome.
Since I currently work at a Machine Learning company, it may surprise some to find out that I am currently enrolled in Andrew Ng’s Machine Learning class thru Coursera. I am taking the class because I want to be able to have a meaningful conversation with our mysterious Machine Learning gurus at BigML. Anyhow, I am apparently not the only person interested in taking this class; the first time it ran, it had more than 100,000 students sign up. This makes it clear that lots of people want to learn more about Machine Learning. Also, that Coursera is awesome.
But the dark side of those enrollment numbers is the completion rate for the course, thought to be around 10%. What happened to those 90% that made them drop out? According to Daphe Koller, one of the Co-Founders of Coursera: “Their intent is to explore, find out something about the content, and move on to something else.”
And, that’s reasonable. The world is ablaze with articles about “Big Data” and “Machine Learning” so of course there are a ton of people who want to know what it is all about. But when they look at the syllabus and see matrix functions, and partial derivatives they realize that what they want is to wield a ML hammer, not forge one. To quickly apply the principles of Machine Learning and see results from their data. If you’re in that 90%, then you don’t need Coursera; you need BigML!
The Challenge
What got me thinking about this was a recent exercise in the course which involved programming a Neural Network to solve the problem of handwritten digit recognition. The dimensions of the network were provided as part of the exercise, along with a framework of code to run the algorithm. The bulk of the task then was to implement the “backpropagation” algorithm to determine the correct activation values for each node in the network.
And it was hard. While I enjoyed the challenge, and I was very happy when my network showed a better than 95% accuracy at recognizing digits (note: over the training set – more on that later), the algorithm was obtuse. Moreover, when I started playing with my Neural Network and trying to train other datasets, there was always an uneasy level of guesswork: how many nodes, how many layers, how many iterations.
And in the middle of my testing, I suddenly wanted to know: could I solve this seemingly difficult problem of digit recognition with a tool as easy to use as BigML? Before we start, let’s get two issues out of the way. First, we have to deal with the fact that BigML doesn’t offer a Neural Network algorithm. But fear not, BigML does support Random Decision Forests, and we have some pretty solid science behind our assertion that they are as good.
Second, I need to address the criticism that this is an apples to oranges comparison, which is true. The ml-class is meant to teach Machine Learning, and BigML is meant to leverage Machine Learning. Those are totally different goals. But remember the premise of this article is to address the 90% that signed up for the course wanting to “…explore, find out something about the content”, and to show that BigML is an ideal platform for people to explore Machine Learning and to even get results immediately.
Walkthru
So, let’s get the data out of the ml-class matlab format and into something that BigML will understand. From octave:
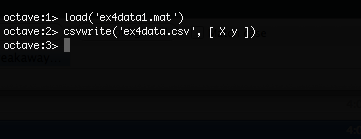
The first command loads the matlab formatted data into octave. The matrix “X” is 5000 rows by 400 columns. Each row of X is 400 floating point numbers representing the greyscale values of a single 20×20 pixel image of a handwritten digit. The matrix “y” contains the numeric value of each image. To format this data for BigML, we create a 5000 row by 401 column matrix with the y values in the last column and save it as a CSV file.
Now we upload the “ex4data.csv” file into BigML – the fields will be automatically detected by BigML, but we need to correct the objective field to be categorical:
With that change, all that remains is to 1-click dataset:
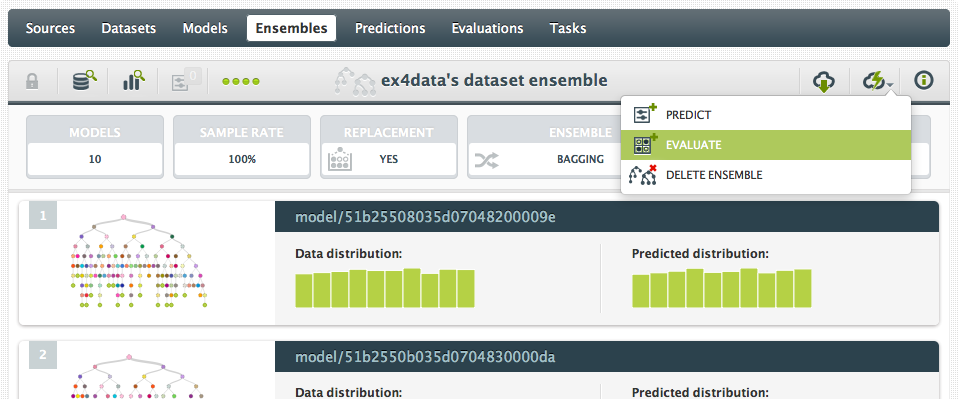
And, then 1-click ensemble:
That’s it! We now have a Random Decision Forest in BigML for recognizing handwritten digits! So how does it perform compared to the Neural Network? The final step in the ml-class test was to evaluate the Neural Network over the training set, which we can do in BigML as well using an evaluation over the original dataset:
And the result? 98.06% accuracy…
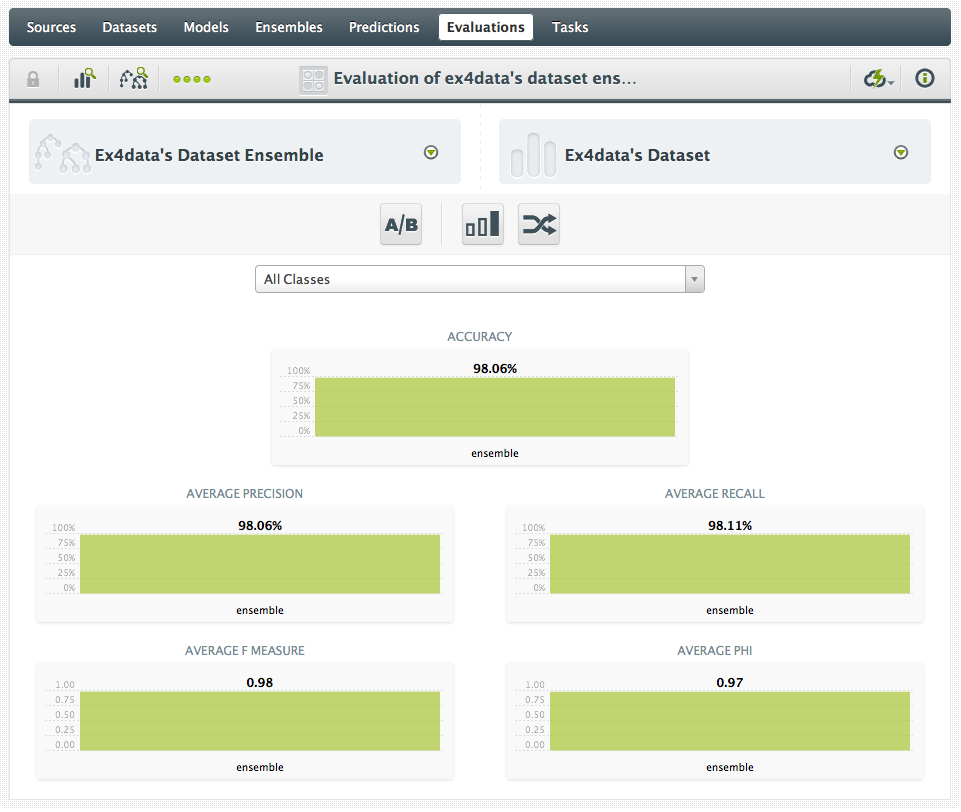
So, that was incredibly easy. And fast. No programming, no guesswork, just a couple of clicks and I’m done. BigML even performed slightly better out of the box than the neural network I trained (but see below). Even better, we now have a model in BigML that can be used via an API to create predictions. I could easily wire this model into an application that is generating images of handwritten digits and start using it to recognize digits.
A Real Evaluation
One last thing: Let’s address the issue of evaluating over the training set. This is at best only valid as a “check” that your model is working, and not a good test as to whether or not the model will actually make good predictions on data that it has not seen. Imagine if I just made a model using a script that performed a table lookup over the original data? Then my evaluation over the training set would always be 100% accurate!
So, what if I really want to get a better idea of how my digit recognizer is working? A common method is to split the original dataset into two datasets – one to train the model with, and one to evaluate the model with. So, let’s think about writing a script to split the 5,000 lines into two randomly chosen sets…. or no!. This is also very easy in BigML. First, we split the dataset:
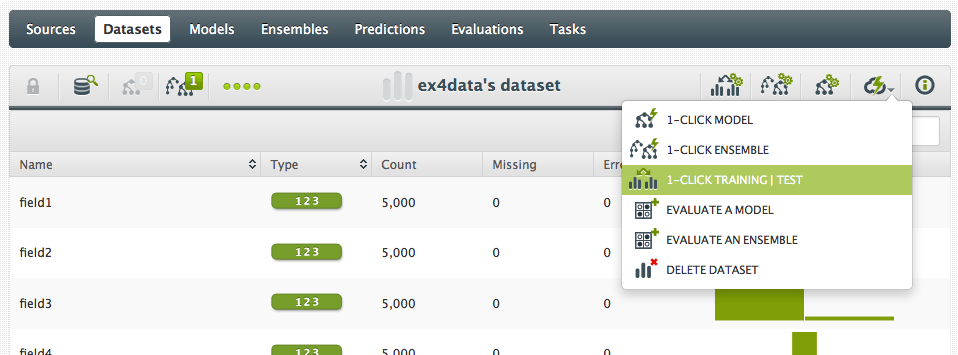
And now I have three datasets: the original “full” dataset, a “training” dataset containing a random 80% of the original dataset, and a “test” dataset with the remaining 20%. Now we can build the 1-click ensemble with the training set:
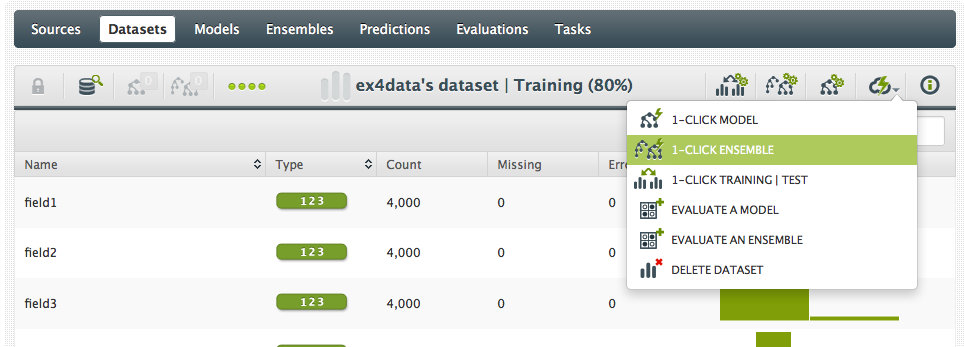
And when the ensemble is done, we evaluate it using the test dataset:

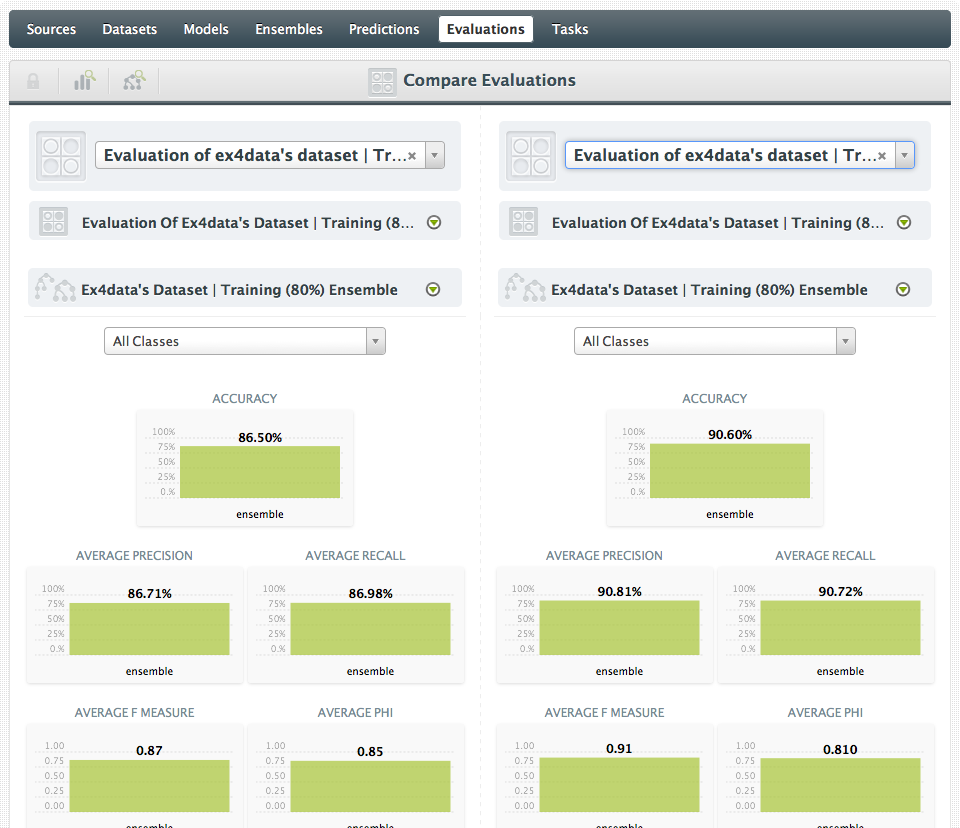
And the result? The accuracy when measured more realistically with data the model has not seen is now 86.5%.What if we needed higher accuracy? One way to improve accuracy of a Random Decision Forest is to build a larger forest with more trees. Let’s try the same training/test set but with 20 models instead of the 1-click default of 10 (I’m also switching to a Decision Forest instead of Bagging which is the 1-click default):
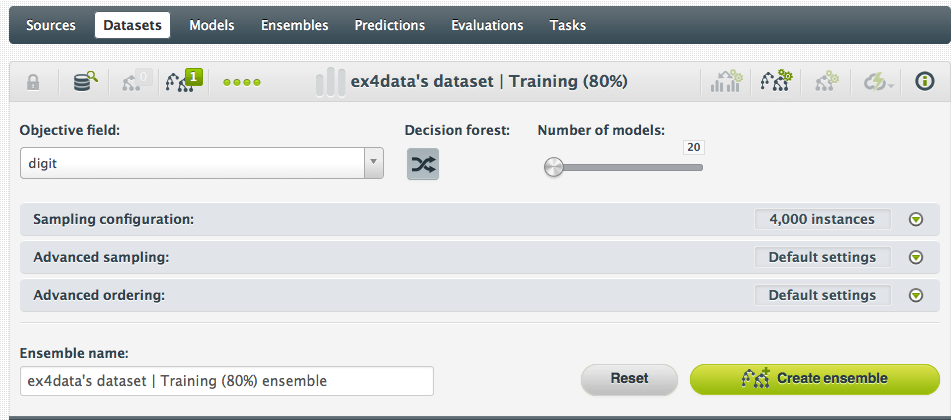
This new 20-model ensemble achieved a 90.60% accuracy over the test dataset!
And I just ran that test from my camp chair next to a fire with only a weak 3G connection!
Finally, what if you want to see those two evaluations side-by-side? Yeah, BigML can do that too:
Which shows:
Note – if you are playing along at home trying to duplicate these results, you will burn thru a lot of BigML credits. We know this is the kind of testing you want to do, and because we are passionate about democratizing Machine Learning, we are now providing a subscription service so that you can run as many tasks as you want with only a fixed monthly (or quarterly or yearly) cost. Even better, the first 25 users who sign up for any of our subscription plans with the coupon code COURSERA will get a 25% discount!
Now is Your Time for Machine Learning
So, if you are eager to play with Machine Learning but despair at the idea of writing code, then don’t sign up for a Coursera class, instead get an account in BigML. It’s free to join and there’s nothing to install and no code to write. A browser is all you need to access the easy-to-use but powerful Machine Learning tools that BigML has created and to quickly start finding your own data insights. And if you do get stuck or just have a question, then don’t hesitate to contact us. We are always eager to help out!

Also I’m a big fan of Coursera Machine Learning class – I completed one myself -, but this is a very nice application to make Machine Learning available for everyone’s use!
Good Job!
Yes, this lesson that introduces Neural Nets is exactly where I dropped out last year.
The problem with the Coursera Machine Learning course by Dr Ng is that – – –
– – – the professor teaches you “A”, but you have to do “B” to pass. He teaches the theory of Neural Nets, but fails to teach the implementation. He expects you to implement it. From the theory.
Personally, I do better if I am shown how to do, first. Then I will be able to do that, after. And apparently, 90,000 people agree with me. OK, I am not MIT or Stanford material. Never said I was. But the course is apparently aimed at this calibur of student.