There is an ever expanding amount of data available on gazillions of web pages; and by analyzing that data you can bring very interesting insights to your business (the Variety of Big Data). Unfortunately, that data isn’t always structured in a way that allows it to be directly used to build predictable models, nor is it always easy to find reliable data on the topic in which you are interested.
To help address this issue, we’ve compiled a helpful list of public data sources you can check out, and we’ve recently recently partnered with Quandl, who expose over 6 million datasets through their service. But what if your model requires information that is out there on the web that isn’t indexed or readily available in tabular form?
A cool start-up from the UK called import.io has a solution for exactly this scenario—their data browser lets you extract data from multiple web pages and export that data to a CSV file that can be easily uploaded to BigML for predictive modelling purposes!
Etsy sales predictive model
Imagine that you want to build a model that predicts average sales in Etsy stores. To do this, you’d want to create a structured file with field values for all the stores based on information from a sample of 60,000 Etsy stores; this data sample may include things like the number of products in a store’s catalog, the volume of customer feedback, the store’s number of admirers, the store’s open date, etc.
In order to build our predictive model, you’d want to create a structured file with a first row specifying the column names…
store,items,feedback,sales,admirers,open_date,positive_feedback
and a series of comma-separated rows like:
ancagray,38,45,117,1853,2010-10-13T00:00:00.000,100 HiddenAcresSoapCo,65,228,448,1716,2012-08-12T00:00:00.000,100 inameliart,96,81,150,4614,2011-01-13T00:00:00.000,100 ManniaTitta,132,213,484,1115,2010-04-17T00:00:00.000,100 tiffinstudio,15,9,35,1027,2011-11-19T00:00:00.000,100 MagicJewelryStore,77,17,63,810,2011-12-18T00:00:00.000,100 MissBettysAttic,2108,3185,6759,4204,2010-10-21T00:00:00.000,100 ...
But how do we obtain/create these records for this dataset and model? Etsy doesn’t have an API that exposes this data. In fact, the data that we need is distributed across etsy.com, displayed in the various store pages. We could copy and paste a small set of values, but to do the same for 60,000 stores would be impossible. This is where import.io’s data browser comes into play.
import.io’s Crawler
The crawler, a feature within the import.io data browser, was designed to extract data from multiple web pages within a website. Once you have this data, import.io will export it into a CSV file, which you can then upload to BigML to build predictive models.
Once you have downloaded and installed the browser, you simply choose “New Crawler” and navigate to the site you want to get data from. Then, define the data on a sample page by the values you decided on earlier. You must capture the values displayed on the website in order to build a complete row in the final CSV.
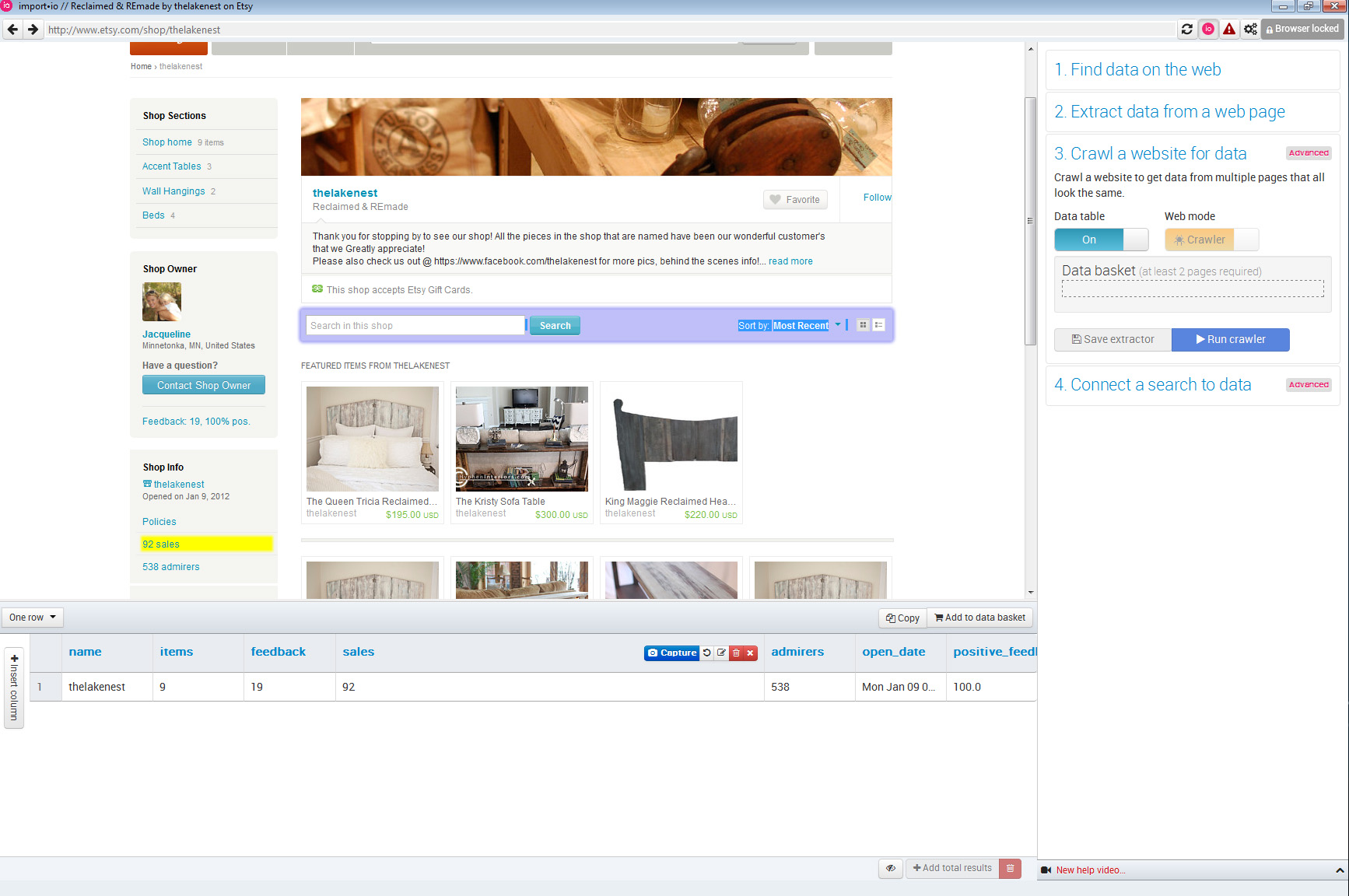
When all the field values are captured for a single store in the current webpage, you have to add it to the basket as a trained page, and move to another page that contains the same kind of data for another store.
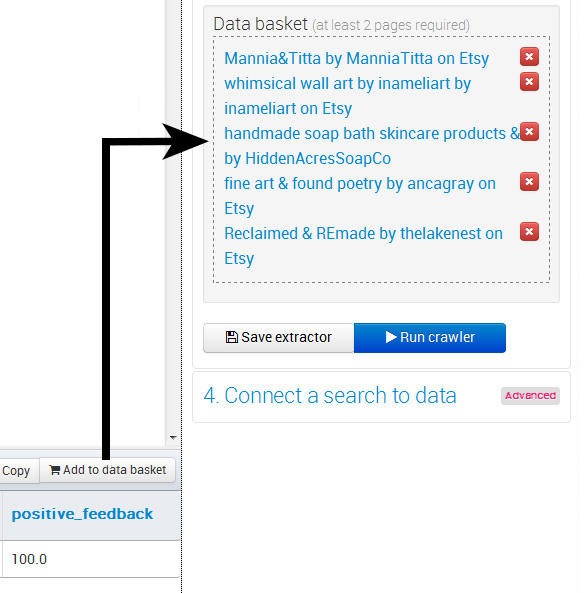
Once you have defined enough pages (usually 5) and added them to the basket, the crawler is now ‘trained’; i.e., it knows how to extract every field value for the rest of the pages of the website.
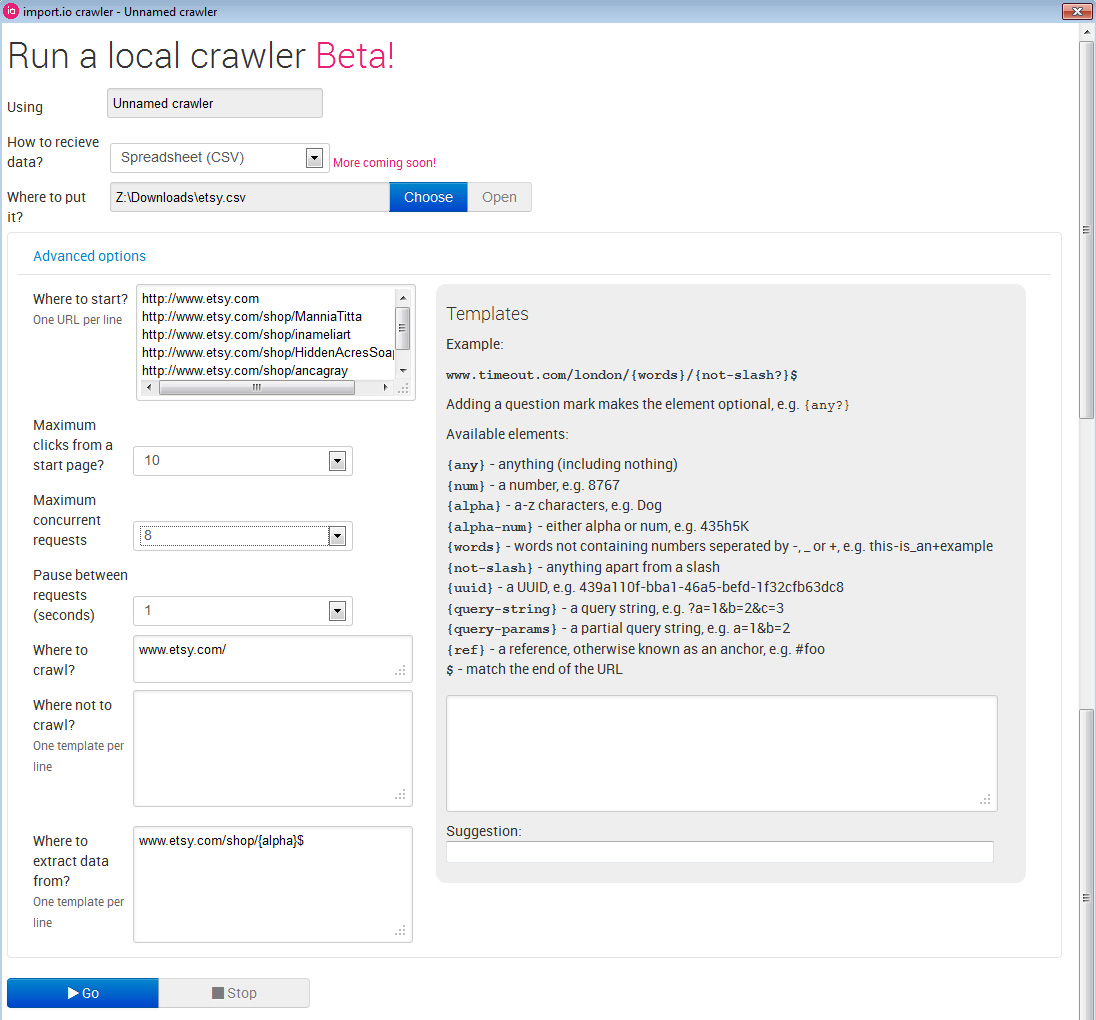
Now it is time to run the crawler. It is often helpful to set some of the configuration variables yourself to better focus the crawler and boost efficiency. You can set:
- CSV filename where data will be saved.
- Where to start: A set of URLs (automatically set as the trained URLs) where the crawler will start searching for new links to other pages within the site.
- Maximum clicks (from start page): how deep you want the crawler to surf.
- Maximum concurrent requests.
- Pause between requests (sec).
- Where to crawl: Specify the domain where to extract data, avoiding external domains.
- Where not to crawl: You can filter by adding URLs in the website you certainly know there’s no data to be extracted (register pages, configuration pages, checkout pages…)
- Where to extract data from: A template with regular expressions of the pages that contain data. The template can be generated using the box at the right.
When the crawler is initiated, it begins to pull data from the identified set of web pages, starting with the trained pages. You can see the data as it is collected in the crawler’s log, now available to download as a CSV when running the crawler:
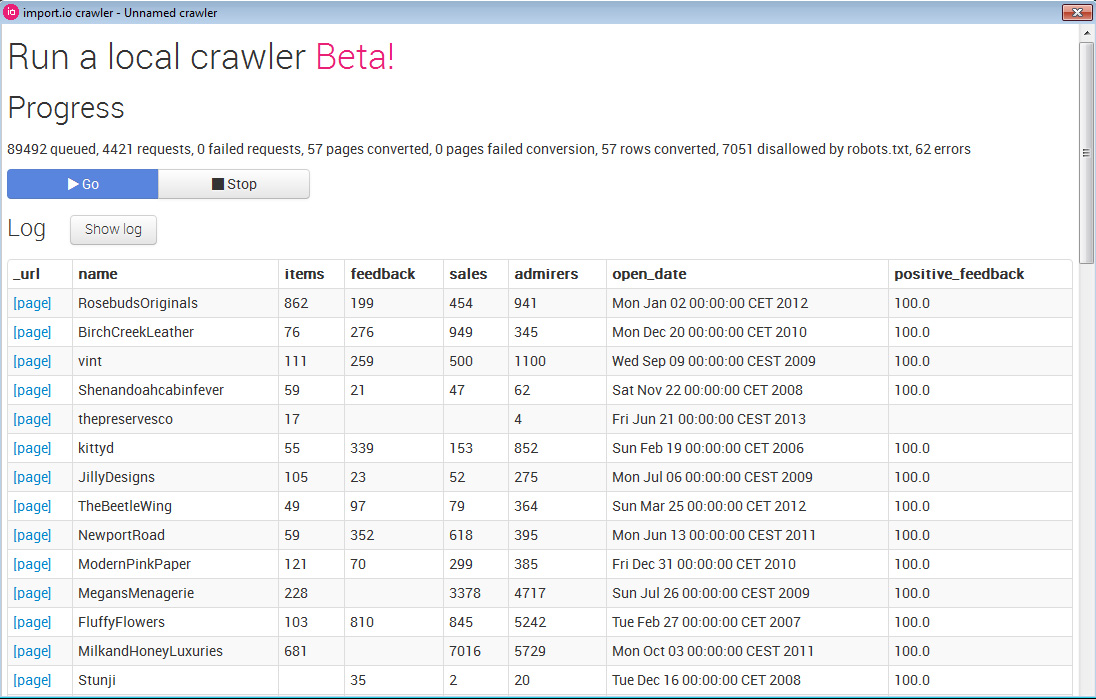
The crawler process can take anywhere from a couple of minutes to a couple of days, depending on the size of your sampling. You can also stop the Crawler manually once you think you have enough records. Once the process is complete, import.io can generate a CSV file that features data extracted from hundreds or thousands of pages—and it is now ready to be uploaded to BigML, to build predictive models.
Our end result
Using the data extracted via the crawler in import.io’s data browser, we created a 60k row dataset, resulting in a predictive model reflected in the decision tree below:
Where the store’s “number of sales” are predicted based on the other store variables.
And using our sunburst visualization you can quickly scan by expected error:

Give it a shot!
We’re excited by this new collaboration with import.io and think that our users will find the joint offering to be very useful. As a special promotion, we’ll grant a free one-month subscription to the first five users that publish models to our gallery using data pulled by the import.io data browser—simply email us with a link to your model and we’ll send you the special discount code!

One comment