We love data, big and small and we are always on the lookout for interesting datasets. Over the last two years, the BigML team has compiled a long list of sources of data that anyone can use. It’s a great list for browsing, importing into our platform, creating new models and just exploring what can be done with different sets of data.
In this post, we are sharing this list with you. Why? Well, searching for great datasets can be a time consuming task. We hope this list will support you in that search and help you to find some inspiring datasets. Some data sources are great for complementing your own data. Others are interesting or just fun to play with. If you have your own list of favorite data sources and want to share them, feel free to let us know and we’ll update our list.
Categories of data sources
We grouped the links into some categories. Here is a short discussion of the categories, with some examples.
Machine Learning Datasets
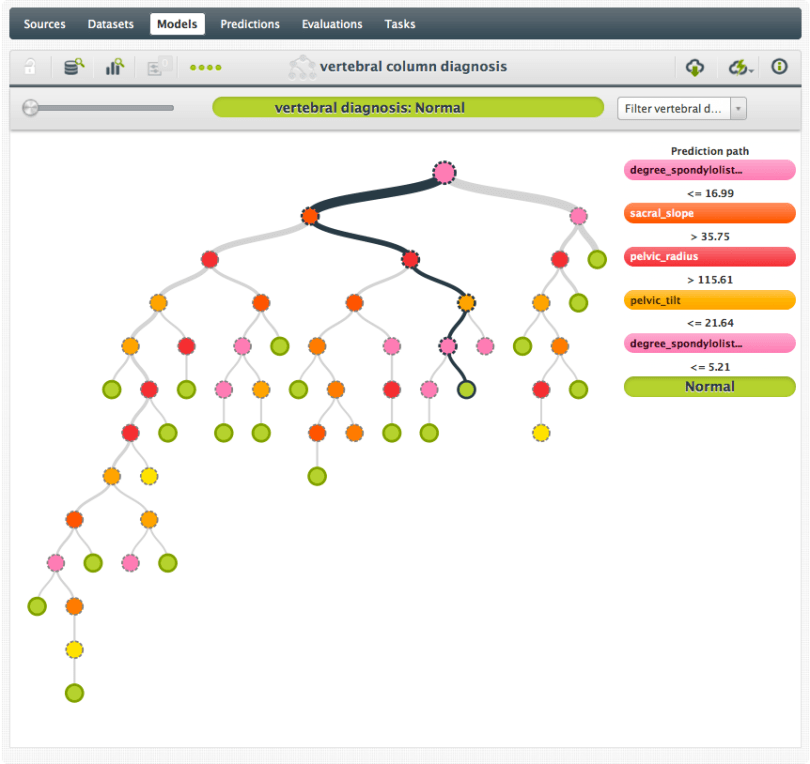
Although many datasets can be used for machine learning tasks, these sources are specifically pre-processed for machine learning. We included one of the most famous sources of machine learning datasets in here: the UCI Machine Learning Repository. There are hundreds of datasets in this repository, nicely categorized so you have multiple angles to search. All datasets are well documented, including data set descriptions. One of the datasets you can find here is the widely used ‘iris’ dataset. Another example is this vertebral column dataset that has data on 6 features to diagnose orthopaedic patients.
| Example: | Vertebral Column Model, predicting one of three condition of the vertebral column, based on various metrics. |
| File: | vertebral_column_data.zip |
| Format: | .csv and .arff |
| Access: | direct download |
| License: | Adhere to citation policy |
Machine Learning Challenges
Our next group of links contains links to Machine Learning Challenges. Each challenge comes with data and usually this data is available for download, even after the challenge is closed. So challenges offer an interesting source of all kinds of data. One of the leaders in this field is Kaggle. But lesser known challenges like Digging Into Data or Causality Workbench have interesting repositories too.
Marketplaces and data hubs
There is an ever growing number of places where one can offer data, search data and download data. Some are commercial offerings that have both paid and free datasets. Others are more community style, non-commercial places where people share datasets. In this bundle we have combined these into a nice collection of places that have thousands of datasets. One of our favorites is Infochimps. Although they are now focusing on monetizing their big data platform, they still have a diverse data marketplace that is easy to browse through. Another great place is Microsoft’s Windows Azure Marketplace. This marketplace has both paid and free datasets that you can subscribe to. You collect the data through an API, through setting a query and downloading the results or through BigML’s integrated Azure Marketplace widget.
|
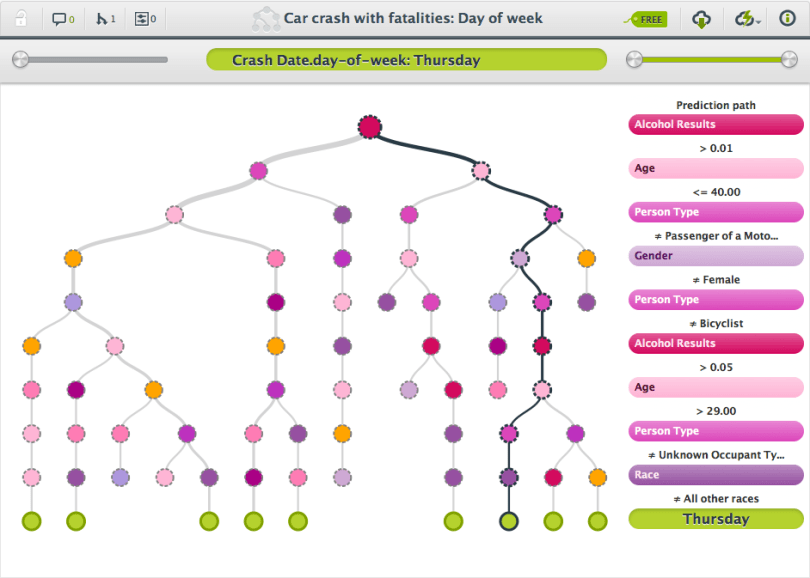
Example: |
Car crash with fatalities, day of week: models day of week patterns in car crash fatalities. |
| File: | USA 2011 Car Crash Data |
| Format: | CSV |
| Access: | OAuth |
| License: | Terms set by the publisher of the data. |
Open companies
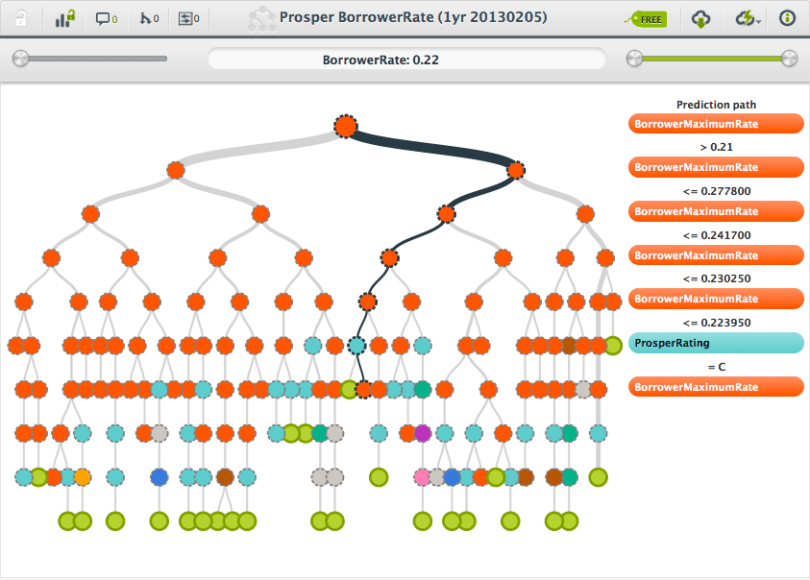
We found some companies that share some of their data through downloads or API. We hope this short list is just the beginning and many more will follow! Among the early adopters are Best Buy, Ebay and LendingClub. Also on this list is Prosper: we’ve created a daily feed through their API to model Prosper Status, Borrower Rate, Loan Status and Bid Count.
| Example: | Prosper Borrower Rate model, predicting the rate at which a borrower can get money. |
| File: | various files |
| Format: | XML and CSV |
| Access: | Direct download and through ProsperAPI |
| License: | Prosper API Terms of Use |
Data search engines
There are even special search engines that help you find data and data sets. Like Quandl, where you can search in over 3,000,000 financial, economic and social datasets. Open data @CTIC will let you scout open data initiatives worldwide. Zanran is a web site where you can search the web for data and statistics.
Data Journals
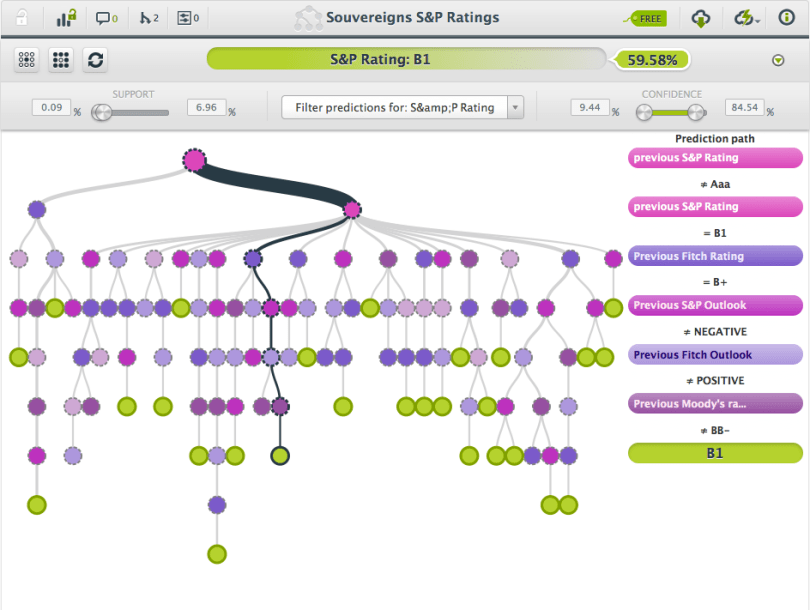
Then there are Data Journals. We only found a few. They not only publish data related stories, but also the data to go with the story. This way you can make your own analysis, visualization or models and even share them. At Sargasso most posts are in Dutch but you’ll find some in English with data-links and nice visualizations. The Guardian Data blog is iconic of course. This blog is very open to what you can do with the data they provide. It even has a separate Flickr group where you can upload new visualizations. As an example, here’s a post on credit ratings per country by S&P, Moody’s and Fitch that we created some models for.
| Example: | Souvereigns S&P Ratings, predicting a country’s S&P rating based on the previous ratings by the big rating agencies. |
| File: | https://docs.google.com/a/bigml.com/spreadsheet/ccc?key=0AonYZs4MzlZbdDdpVmxmVXpmUTJCcm0yYTV2UWpHOVE#gid=19 |
| Format: | Google Docs Spreadsheets |
| Access: | Download through Google Docs in multiple formats |
| License: | public data |
Open Data Sources
There’s a big push for governments to be transperant and share data. We found a lot of sources on open data and have grouped them into a number of bundles that are more or less self explanatory.
Local government that contain links to open data sites of cities and counties around the world. National Government, with links for countries, but also including (US) States and regions. International bodies and Agencies, like the United Nations, the Worldbank et cetera. Finally a special bundle for US agencies.
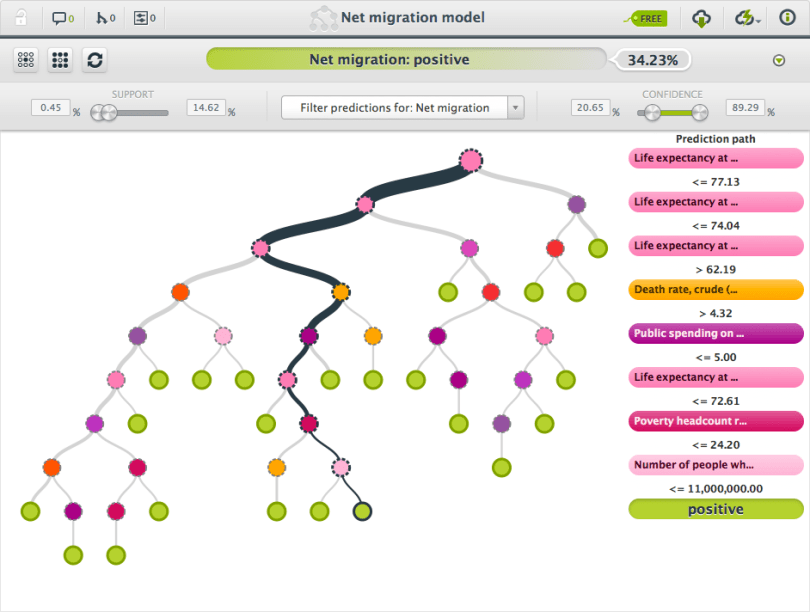
One of the International Organizations that has made an amazing amount of data available is the World Bank. There is for example the World Development Indicators Database. You can extract data from this database using a simple interface and download the data you are looking for. For this sample ‘Net Migration Model’ we combined various economic and demographic indicators with net migration data.
| Example: | Net Migration Model, predicting migration streams based on a number of indicators. |
| File: | data taken from World Development Indicators Database |
| Format: | csv, xls, txt |
| Access: | Direct Download |
| License: | Terms of Use for Datasets |
A list of lists
We also have a bundle that contain lists of data sources. You will find interesting new sources but also some doubles in these lists. Sources are for instance Hillary Mason’s Bundle of links on where to find research quality datasets, links to Quora questions & answers that contain references to data sources, blog posts that feature data source lists and a variety of other lists we found.
Miscellaneous
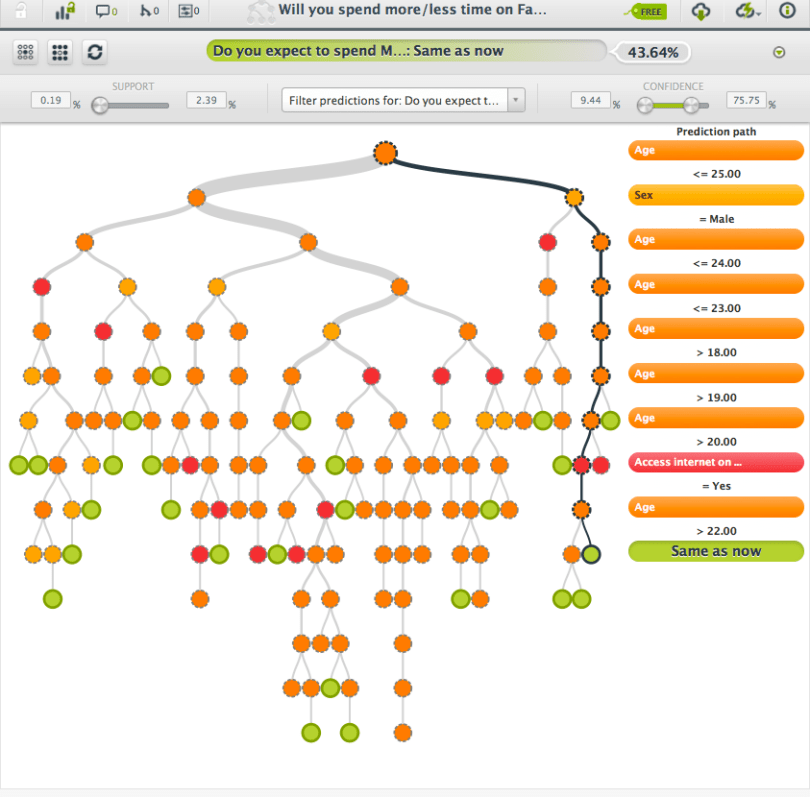
We’ll end with an interesting collection of miscellaneous sites that publish specific data, like Cosm.com where you can publish and download sensor data. You can find the Million Song Dataset here, Google’s n-gram datasets, data ranging from scientific to personal. It’s a great list to spend a rainy day on. As an example, take a look at the data from the Pew Internet & American Life Project. It is a rich source of data on internet related and social topics. Like this survey regarding the use of Facebook. We used it to make a predictive model on ‘Do you expect to spend more/less time on Facebook the upcoming year?’.
| Example: | Will you spend more/less time on Facebook?, predicting the amount of time people spend on Facebook. |
| File: | Omnibus_Dec_2012_csv.csv |
| Format: | csv, SPSS, Word |
| Access: | Direct Download |
| License: | Use Policy |
A Final Word
Just a final word about these lists. We focused on the English speaking part of the world, very aware of the fact that there are many sites in other languages that we missed. Even for the English speaking part, there’s no way we would find every possible source. Feel free to send us your favorite links at datasources@bigml.com and we will add them to the list!
We hope this great list of sources encourages you to go out and have fun with data. Not familiar with BigML’s services? No problem: registration only takes a minute, is free and will get you a good set of promotional credits to get you going with some of these datasets!

awesome set of links. much thanks.. but did bitly pay you to use their service? why not just do a couple sections of direct links so we can just bookmark them all easily? please?
Hi – Bit.ly did not pay us and neither did any of the sources mentioned in the blog post. We did try a number of different approaches, but in the end found the bundles a good way to reference and still keep a perfectly good readable blog post. I know there are pro’s and con’s. But you can simply bookmark the bit.ly page, still have access to all the references and keep up to date with future add-ons to the list.
I’m impressed, this will be super useful. I spend a decent amount of time looking around for datasets, and it’s harder than I would have imagined.
Finding out about Quandl is alone a pretty big victory.
All I can say is THANK YOU!
See also Pete Warden’s “Data Source Handbook” http://www.amazon.com/Data-Source-Handbook-Pete-Warden/dp/1449303145
Excellent list! See also KDnuggets page for Data APIs, Hubs, Marketplaces, and Platforms http://www.kdnuggets.com/datasets/api-hub-marketplace-platform.html
one more dataset http://endb-consolidated.aihit.com/datasets.htm – random 10,000 worldwide companies sampled from HitCompanies…
Does anyone know a streaming data source? A source that I can connect, for example SAP Event Streaming Processor (ESP), and build rules around this data before storing it somewhere.
Thanks,
MJ
HOW DO FIND DATA FOR MY MTECH PROJECT ON DATA MINING OF AN STANDARD IEEE JOURNAL????
Aggregated visitor interests dataset, https://www.jc-bingo.com/about
compiled based on 1 week web access logs. Includes visitor IP address, user-agent string, visitor country, accessed page languages and topics.