As Machine Learning use grows, the need for engineering solutions to cover all the diversity of real end-to-end scenarios that arise becomes more obvious. Originally, people mainly focused on creating and tuning the best model that your data could produce. Nowadays, that task can be handled nicely by automated procedures like OptiML and AutoML, which will smartly find the best combination of model types and parameters for the business problem at hand. But still, once we find the right model the challenge of building the right framework to use it as a piece of software ready for production remains. In short, we need actionable models.
Since the very beginning, BigML has been aware of that need as every model created in BigML is immediately available for prediction through our API. But still, some scenarios need models to be distributed and deployed elsewhere. Again, BigML‘s white-box-model philosophy favors that, as all models (and datasets or any other resource) created in the platform are also downloadable as JSON files. Historically, we’ve provided tools to be able to integrate those models in several software environments and today we will be presenting bigmlflow, the flavor that you can add to MLFlow to manage and deploy BigML’s Machine Learning models.

The BigML Flavor
Using Machine Learning models in MLFlow requires building flavors for them. Each flavor uses libraries that take care of the details needed to correctly serialize and predict using the model’s information. For BigML’s supervised models, this is handled by bigmlflow.
Installing bigmlflow is as easy as using pip
pip install bigmlflow
and the install procedure will take care of installing dependencies, like the right version of MLFlow or the BigML Python bindings, needed to access BigML’s API. So in a single line, you are ready to start working.
Registering BigML Models with MLFlow
To begin with, let’s get into MLFlow‘s environment and start its dashboard with the following command
mlflow server --backend-store-uri=sqlite:///mlrunsdb.db \
--default-artifact-root=file:mlruns \
--host localhost \
--port 5000
which will use the file system to store all the model-related artifacts while MLFlow entities are stored in sqlite tables. We’ll also set the environment variable needed for MLFlow to know where the tracking will be handled.
export MLFLOW_TRACKING_URI=http://localhost:5000
Typing this URL in our browser, we see a clean interface waiting for us to create or register new models. As we want to focus on deploying and operating our models to ensure they are actionable, we will first register an existing BigML model in the MLFlow experiments list using bigmlflow. This requires:
- Downloading the model JSON file from BigML’s API
- Using the bigmlflow library to register the model
The bigmlflow repo contains an examples directory where you can find some BigML models. In this example, we will use a logistic regression
https://github.com/bigmlcom/bigmlflow/blob/master/examples/bigml_logistic/logistic_regression.json
that has been built using data from patients that may or may not have diabetes and whose objective is predicting whether a new patient will be diabetic (diabetes=True) or not (diabetes=False).
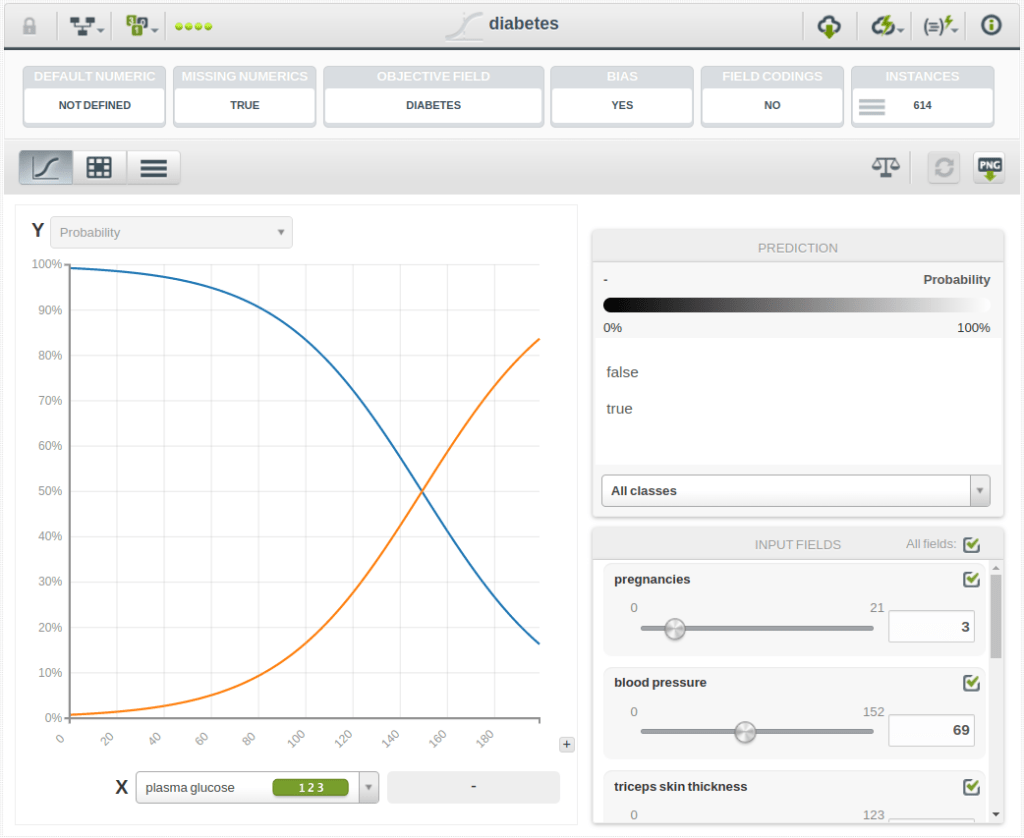
Of course, you can instead download any of the models that you create in BigML. However, as resources are private, your credentials should be provided for authentication. Once you set them as environment variables, the download code would amount to
from bigml.api import BigML api = BigML() api.export("logisticregression/62605ed90c11da5789002caf", "logistic_regression.json")
where logisticregression/62605ed90c11da5789002caf would be the ID of the model to be downloaded and the download would be stored in a logistic_regression.json file in your current directory.
Now we’d like to register that model. After that, we will be able to load it again to produce predictions from it and to assign an endpoint that will provide a REST API where we will be able to send Panda’s Dataframe inputs and receive the corresponding predictions. The code is also simple enough.
import json import mlflow import bigmlflow MODEL_FILE = "logistic_regression.json" with mlflow.start_run(): with open(MODEL_FILE) as handler: model = json.load(handler) bigmlflow.log_model(model, artifact_path="model", registered_model_name="my_model")
The model appears as registered in the MLFlow console:

Clicking on the model link, we see the information about the internal reference to the model. In this case, runs:/6297eabd4c2449f89e40ff503ca0fbf6/model. Imagine you want to setup a service that predicts using that model. You just need to use the mlflow models serve command
mlflow models serve --model-uri runs:/6297eabd4c2449f89e40ff503ca0fbf6/model \
-p 1234 --env-manager=local
and a new web service will be awaiting your input data to generate predictions. We can send a couple of inputs to it for a quick taste of what we can get.
$ curl http://localhost:1234/invocations \
-H 'Content-Type: application/json' \
-d '{"columns":["plasma glucose"], "data": [[90], [220]]}'
[{"path": ["plasma glucose <= 123"], "confidence": 0.69324, "distribution": [["false", 85], ["true", 24]], "count": 109, "distribution_unit": "categories", "prediction": "false", "next": "bmi", "probability": 0.7781363636363636}, {"path": ["plasma glucose > 123", "plasma glucose > 166"], "confidence": 0.75033, "distribution": [["true", 23], ["false", 2]], "count": 25, "distribution_unit": "categories", "prediction": "true", "next": "bmi", "probability": 0.9001923076923077}]
So there you are! A BigML model deployed and ready to predict in your local server. Of course, you can use the rest of the options offered by MLFlow and deploy it in Google Cloud, AWS ML, or your platform of choice.
Tracking BigML experiments
We just went from last to first in our explanation of how BigML can be integrated in MLFlow and showed you the final step of the entire solution, but of course, there’s more to it. You can use the tracking provided by MLFlow to record your experiments with BigML too.
For instance, let’s take a look at the following part of the code provided in our training example at bigmlflow.
with mlflow.start_run():
model = api.create_model(train, args=model_conf)
print("Creating Model.")
api.ok(model, query_string="limit=-1")
evaluation = api.create_evaluation(model, test)
print("Creating Evaluation")
api.ok(evaluation)
print(
"BigML model: %s\nconf:%s (%s)"
% (
model["object"]["name"],
model["object"]["name_options"],
model["resource"],
)
)
print("accuracy: %s" % evaluation_metric(evaluation,
"accuracy"))
print("precision: %s" % evaluation_metric(evaluation,
"average_precision"))
print("recall: %s" % evaluation_metric(evaluation,
"average_recall"))
mlflow.log_param("args", json.dumps(model_conf))
mlflow.log_metric("accuracy", evaluation_metric(evaluation,
"accuracy"))
mlflow.log_metric(
"precision", evaluation_metric(evaluation,
"average_precision")
)
mlflow.log_metric("recall", evaluation_metric(evaluation,
"average_recall"))
A model is created in BigML using api, the same API connection object that we mentioned before. When finished, it’s evaluated with a previously created test holdout. The configuration parameters used to create the model, stored as model_conf , are also logged in the MLFlow experiment information, together with some of the evaluation metrics provided. We now have a new experiment that will show these values:

Of course, in realistic scenarios there are lots of parameters that you can change, and evaluations offer plenty of metrics and operating points that should be tracked as well.

The good news is that you’ll always be able to automate the logging because all configuration parameters and results will be available in BigML’s resources as served by the API. As you can see, bigmlflow helps you get the best of both BigML and MLFlow APIs. Still, if you have scenarios not covered by this combination, just let us know about your needs and we will be happy to assist you with other BigMLOps setups.

One comment