We’ve seen in the past several blog posts on how you can learn simple image classifiers with BigML, via the interface, the API, and with the BigML Python Bindings, and we’ve also seen that you can train unsupervised models on the same images. But let’s dig a little deeper and explore different approaches to an image processing problem.

One of the things we try hard to do at BigML is, to paraphrase Alan Kay, make simple things simple and complex things possible. It’s a relatively simple thing to train an image classifier: You have a bunch of images, those images have classes, and you want to train a model that will classify any new image into one of those classes.
One great application of this is the area of security and monitoring: You have a system constantly looking at something and you want to be alerted when that thing changes. For example, you have a security camera looking at a room, and you’d like to be alerted when a person enters.
This problem has a lot of variations. One of these, used by a client of BigML, is to monitor a surface for changes of a specific type. For example, if a person is shooting at a target, we’d like to flag changes in the image of the target that corresponds to new holes in the surface and reject any other changes.
The Only Constant is Change
To sense a change in the image, a simple approach is to use a form of image differencing, where (again, in its simplest form) you subtract the gray-level values of each pixel in the current frame of video from a “reference image” (say, an image where you know there’s nothing in it) and take the absolute value. Differences between the two images will show up as white pixels, and everything that’s the same will be black. Try it, and you’ll see that this is very effective at the classic children’s activity, “Find the differences between these pictures”:

While it’s easy and effective to use image differencing to find unfamiliar things in images, it’s also easy to imagine cases where changes in the image correspond to something other than the thing you’re looking for: The camera may move slightly, things may blow in the wind, lighting may change, things like debris or small animals may dance through the field of view, and so on. So we get a classic image classification problem. In summary, we have images that show a difference between the current scene and the reference, and those images have two classes: differences we care about and differences we don’t.
In the case of this target surface monitoring problem, as a first filter, we convolve the difference image with a hole-shaped filter and only flag areas of the image that “could be” a hole. For each of these, we capture a 32×32 close-up image of the difference of the current surface image with the “reference surface image” in the video.
Most of these correspond to small movements of either the camera or the surface itself, which causes the image to align slightly differently with the reference, and thereby show differences around high-contrast areas of the reference image:

But some of the differences are clearly holes:

And there are some that are a bit ambiguous:

The Simple
So, Machine Learning! Labeling all of these gives you a pretty straightforward dataset. The validation predictions on the trained classifier, while not a substitute for a proper evaluation, suggest that deep learning can more than handle this job.
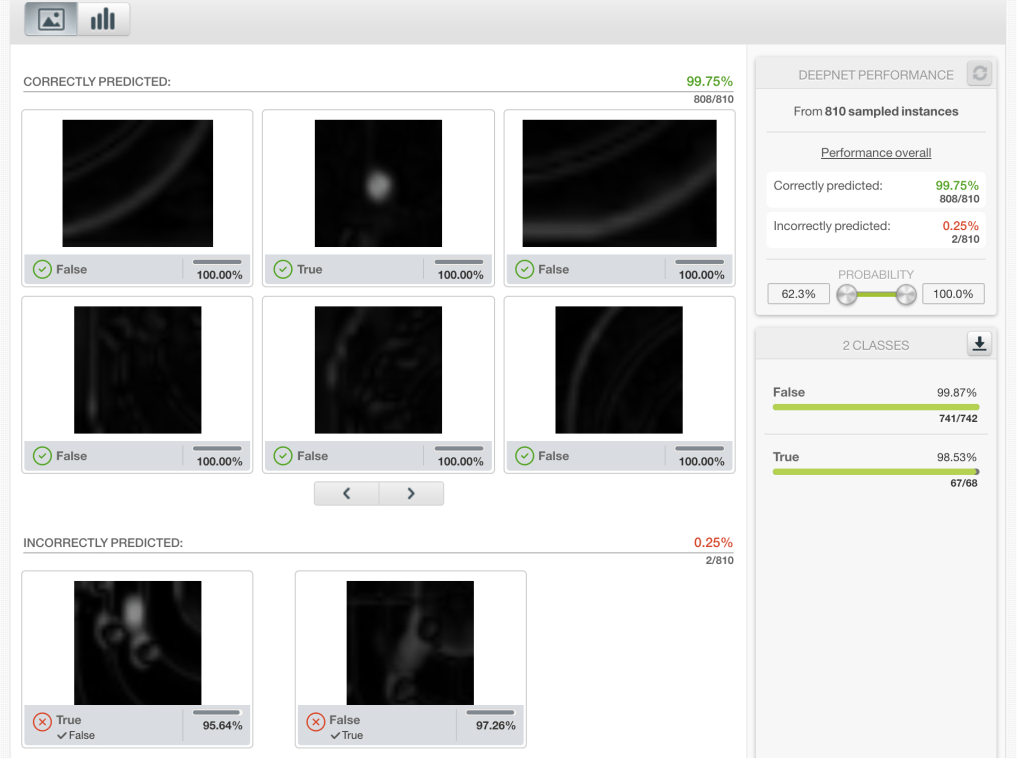
So we’re all done, right? Dust off our hands and go get a beer? Maybe. But also, maybe you have 10 cameras running, and this all has to run in real-time. Now what? Go out and grab 10 GPUs? If you’ve got that kind of money, that’s great, but I sure don’t. Moreover, by doing this you’re volunteering to deal with the nightmare maintenance problems that come with having 10 different machines to keep running, network together, and so on.
Wouldn’t it be nice if we could make this happen all on one machine? All we need is for things to run ten times faster! How hard could that be?
. . . and the Complex
Deep learning works very nicely for these sorts of image processing problems. But there are a few other things that work pretty nicely and are way faster. For example, by default, BigML extracts “histogram of gradients” features for both the whole image and several sub-windows. If you train any model besides a Deepnet on this data, it will use these extracted features as inputs. When you’re configuring your composite image source, you can change the type of features that are extracted:

If you check the documentation, you’ll see that some of those features encode the color information from the image, some encode the texture information, but the histogram of gradients encodes primarily edge and shape information. That seems pretty relevant for this problem, so we’ll train a Logistic Regression using those features and do an evaluation:

It’s very good, but not quite as good as the Deepnet. Overall, it’s about 98% accurate, which isn’t enough for this application. More importantly though, as we can see, at 100% recall for the positive class, we’re at 73.3% precision, while only predicting 10% of the total instances to be positive. This means that using this classifier, we’re able to reject 9/10 images with near-100% confidence, leaving only the “potentially positive” 1/10 images to be passed to the other classifier.
This is important because the logistic model with the histogram of gradients features is way, way faster than a full Deepnet.
$ gradle test --tests *timeTest*
> Task :test
com.bigml.deepnet.ResourceTest > timeTest STANDARD_OUT
Deepnet time per image: 120.58 msec.
Logistic time per image: 0.69 msec.
Results: SUCCESS (1 tests, 1 successes, 0 failures, 0 skipped)We see that on a (commodity) laptop, the logistic model runs 120.58 / 0.69 = about 175x faster than the deepnet. Since 9/10 images never have to see the full Deepnet, and only see this much faster model, we get near 10x speedup without sacrificing any accuracy.
This example highlights one of the best things about BigML, not just for image processing, but on the platform in general. While other Machine Learning solutions focus on letting you optimize and monitor individual models, BigML allows you to combine the Lego pieces of the platform to solve complex problems that can’t be solved by single models alone. With the ultimate goal of building efficient solutions top of mind, when the simple is not enough, BigML always has the complex ready and waiting on the sidelines.
Do you want to know more about Image Processing?
Please visit the dedicated release page and join the FREE live webinar on Wednesday, December 15 at 8:30 AM PST / 10:30 AM CST / 5:30 PM CET. Register today, space is limited!
