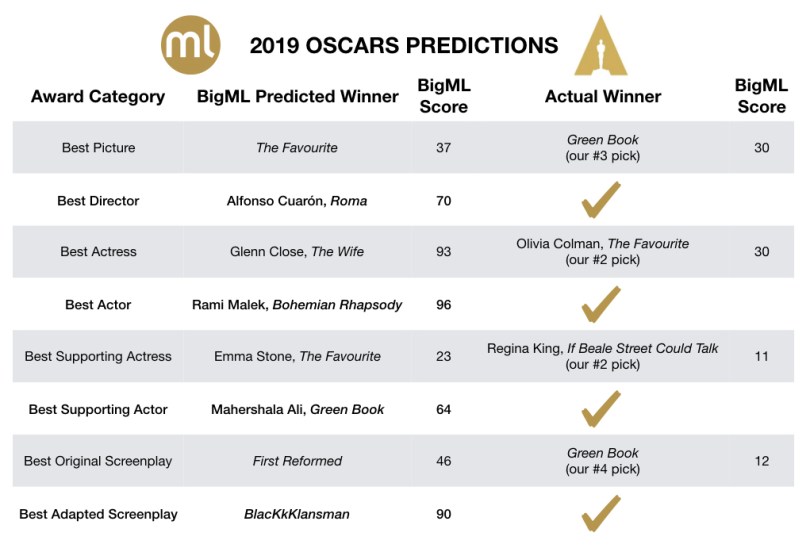
The 91st Academy Awards this Sunday, the first without a host in 30 years, proceeded without a hitch and seemed to sit well with the worldwide audience. For the third year in a row, we applied the BigML Machine Learning platform to predict the winners. This year, we got 4 out of 8 right for the major award categories. While this may seem mediocre, it’s notable that the confidence scores for the most likely nominee to win for 3 out of the 8 categories were well below 50%, meaning those were virtual coin toss type categories with multiple weak favorites going up against each other. Lo and behold, we whiffed on all three weak favorites: Best Picture, Best Supporting Actress and Best Original Screenplay.

At this stage, we can merely speculate the reasons behind the Academy members’ votes, but we can peek behind the curtain to understand how our Machine Learning models made their predictions. So, let’s dive in! Our results are shown in the table below. For two of the missed categories, the actual winners were our second choice, and Green Book, the winner of Best Picture was a close tie as our number 3 pick.
This year we relied on two new tools added to our toolbox that can be game-changers when it comes to improving accuracy and saving time in your Machine Learning (ML) workflows. The first method involved OptiML (an optimization process for model selection and parameterization) which is both robust and incredibly easy-to-use on BigML. Once we had collected and prepared the datasets, which is often the most challenging part of any ML project, all we had to do was hover over the “cloud action” menu and click OptiML. Really, that’s it!
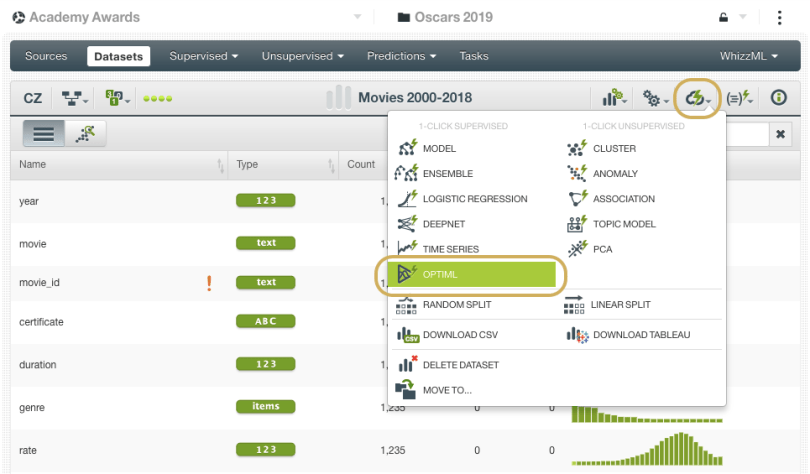
After running for about an hour, the OptiML returns a list of top models for us to inspect further and apply our domain knowledge. In that relatively short amount of time, the OptiML processed over 700 MB of data, created nearly 800 resources and evaluated almost 400 models. How about that?!
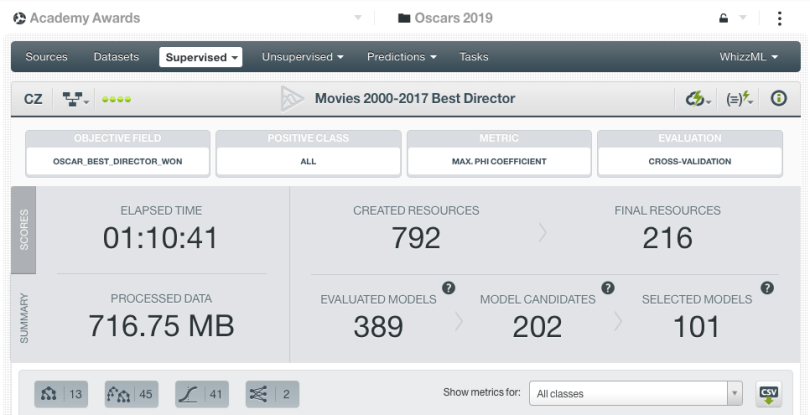
Next, we took the list of selected models (the top performing 50% out of the total model candidates from OptiML) and built a Fusion, which combines multiple supervised learning models and aggregates their predictions The idea behind this technique is to balance out the individual weaknesses of single models, which can lead to better performance than any one method in particular (but not always, see this post for more details). The screenshot below shows the Fusion model for the Best Director category, which was comprised of 13 decision tree, 45 ensembles, 41 logistic regressions and 2 deepnets. The combined predictions of all those models contributed to our pick of Alfonso Cuarón, director of Roma, to take home the prize.
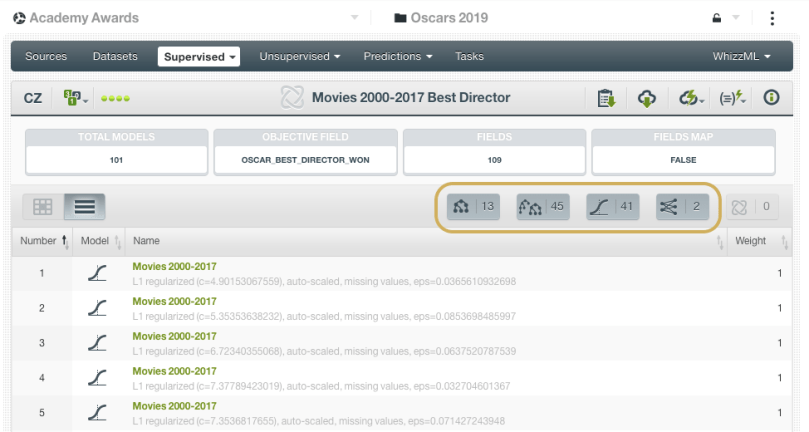
Have we really done the best Machine Learning can do? Is there a reason to believe that OptiML may not have found the best solution to this problem? My colleague, Charles Parker, BigML’s VP of Machine Learning Algorithms, chimes in with an explanation of how things get a little hazy here: Remember, OptiML is essentially doing model selection by estimating performance on multiple held out samples of the data. Since our Oscar data only goes back about 20 years, the number of positive examples in each held out test set is just a fraction of those 20 or so examples. Our estimation of the performance of each model in the OptiML will then be driven primarily by just a tiny number of movies. Indeed, if we mouse over standard deviation icon next to the model’s performance estimate in the OptiML (see screenshot below), we’ll see that the standard deviation of the estimate is so large that the performance numbers of nearly all of the models returned are within one standard deviation of the top model’s performance.
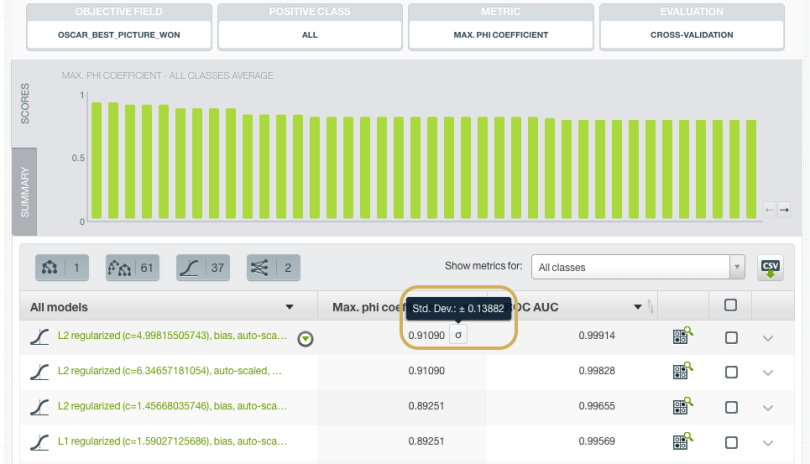
What does this mean? For one thing, it means that you don’t have enough data to test these models thoroughly enough to tell them apart. Thankfully, OptiML does enough training-testing splits to show us this, so we don’t make the mistake of thinking that the very best model is meaningfully better than most other models in the list.
Unfortunately, this is a mistake that is made all too often by people using Machine Learning in the wild. There are many, many cases in which, if you try enough models, you’ll get very good results on a single training and testing split, or even a single run of cross-validation. This is a version of the multiple comparisons problem; if you try enough things, you’re bound to find something that “works” on your single split just by random chance, but won’t do well on real world data. As you try more and more things, the tests you should use to determine whether one thing is “really better” than another need to be stricter and stricter, or you risk falling into one of these random chances, a form of overfitting.
In OptiML’s case, the easiest and most robust way to get a stricter test is to seek out more testing data. But we can’t time travel (yet!), and so we’re stuck with the data we have. The upshot of all of this is that, yes, there may very well be a better model out there, but with the data that we have, it will be difficult to say for sure that we’ve arrived at something clearly better than everything that OptiML has tried.
As it turned out, BigML was not alone in missing the mark for the top category predictions. DataRobot was counting on Roma to win Best Picture, and Green Book was not in their top three. Microsoft Bing and TIME also put their bets on Roma, so it goes to show you the reality of algorithmic predictions being tested in real world scenarios where patterns and “rules” don’t always apply.
Alright, alright, enough of the serious talk. As pioneers of MLaaS here at BigML, we care deeply about these matters concerning the quality and application of ML-powered findings so we couldn’t pass this chance to discuss. But back to red carpet results…we enjoyed the challenge of once again putting our ML platform to the test of predicting the most prestigious award show in the entertainment industry. To all users who experimented with making their own models to predict the Oscars, let us know how your results came out on Twitter @bigmlcom or shoot us a note at feedback@bigml.com.
