The idea of model fusions is pretty simple: You combine the predictions of a bunch of separate classifiers into a single, uber-classifier prediction, in theory, better than the predictions of its individual constituents.

As my colleague Teresa Álverez mentioned in a previous post, however, this doesn’t typically lead to big gains in performance. We’re typically talking 5-10% improvements even in the best case. In many cases, OptiML will find something as good or better than any combination you could try by hand.
So, then, why bother? Why waste your time fiddling with combinations of models when you could spend it on doing things that will almost certainly have a more measurable impact on your model’s performance, like feature engineering or better yet, acquiring more and better data?
Part of the answer here is that looking at a number like “R squared” or “F1-score” is often an overly reductive view of performance. In the real world, how a model performs can be a lot more complex than how many answers it gets wrong and how many it gets right. For example, you, the domain expert, probably want a model that behaves appropriately with regards to the input features and also makes predictions for the right reasons. When a model “performs well”, that should mean nothing less than that the consumers of its predictions are satisfied with its behavior, not just that it gets some number of correct answers.
If you’ve got a model that has good performance numbers, but it’s exhibiting some wacky behavior or priorities, using fusions can be a good way to get equivalent (or occasionally better) performance, but with the added bonus of behavior that perhaps appears a little saner to domain experts. Here are a few examples of such cases:
“Minding The Gap” with tree-based models
There are loads of literature out there showing that, for many datasets, ensembles of trees will end up performing as good or better than any other algorithm. However, trees do have one unfortunate attribute that may become obvious if someone observes many of their predictions: The model takes the form of axis-aligned splits, and so large regions of the input space will be assigned the same output value (resulting in a PDP that looks something like this):
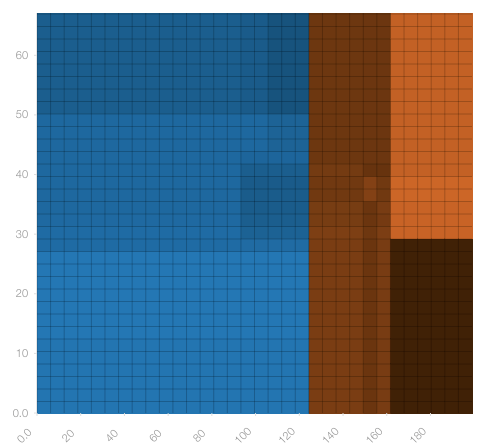
Practically, this will mean that small (or even medium-sized) changes to the input values will often result in identical predictions, unless the change crosses a split threshold, at which point it will change dramatically. This sort of stasis / discontinuity can throw many people for a loop, especially if you have a human operator working with the model’s predictions in real-time (e.g., “Important Feature X went up by 20% and the model’s prediction is still the same!”).
A solution to the problem is to fuse the ensemble to a deepnet that performs fairly well. This changes the above PDP to look more like this:
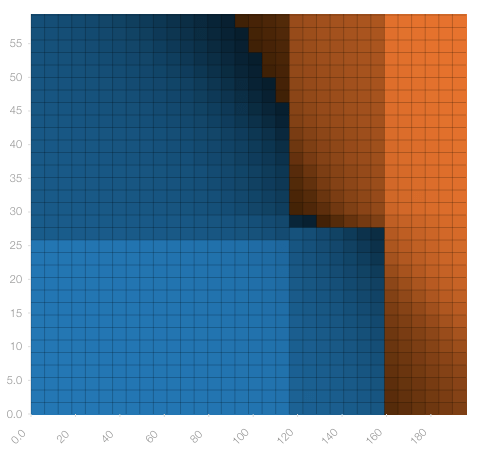
You’ll still see thresholds where the prediction jumps a bit, but there’s no longer complete stasis within those partitions. If the deepnet’s performance is close to the ensemble, you’ll get a model with more dynamic predictions without sacrificing accuracy.
The Importance of Importance
In the summary view of the models learned when you use OptiML, you’ll see a pull-down that will give you the top five most important fields for each model.
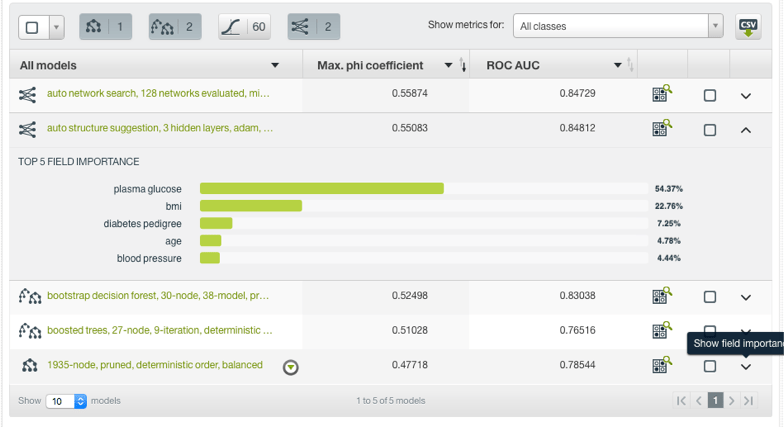
For non-trivial datasets, you may often see that models with equivalent or nearly-equivalent performance have very different field importances. The field importances we report are exactly what they say on the tin: they tell you how much the model’s predictions will change when you change the value of that feature.
This is where you, the domain expert, can use your knowledge to improve your model, or at least save it from disaster. You might see a case where a high performing model is relying on just a few features from the dataset, and another high performing model is relying on a few different features. Fusing the models together will give you a model guaranteed to take all of those features into account.
This can be a win for two reasons, even if the performance of the fused model is no better than the separate models. First, people looking at the importance report will find that the model is taking into account more of the input data when making its prediction, which people generally find more satisfying than the model taking into account only a few of the available fields. Second, the fused model will be more robust than the constituent models in the sense that if one of the inputs becomes corrupt or unreliable, you still have a good chance of making the right prediction because of the presence of the other “backup” model.
(Mostly) Uncorrelated Feature Sets with Different Geometries
Okay, so that’s a mouthful, but what I’m talking about here is situations where you’ve got a set of features, where some are better modeled separately from the others.
Why would you do this? It’s possible that a subset of the features in your data is amenable to one type of modeling and others to different types of modeling. If this is the case, and if those different features are not terribly well-correlated with one another, a fusion of two models, each properly tuned, may produce better results than either one on its own.
A good example is where you have a block of text data with some associated numeric metadata (say, a plain text loan description and numeric information about the applicant). Models like logistic regression and deepnets are generally good at constructing models that are algebraic combinations of continuous numeric features, and so might be superior for modeling those features. Trees and ensembles thereof are good at picking out relevant features from a large number of possibilities, and so are often well-suited to dealing with word counts. It seems obvious, then, that carefully tuning separate models for each type of data might be beneficial.
Whether the combination outperforms either one by itself (or a joint model) depends again on the additional performance you can squeeze out by modeling separately and the relative usefulness of each set of features.
That Is The Question
Hopefully, I’ve convinced you that there are reasons to use fusions that go beyond just trying to optimize your model’s performance; they can also be a way to get a model to behave in a more satisfying and coherent way while not sacrificing accuracy. If your use case fits one of the patterns above, go ahead and give fusions try!
Want to know more about Fusions?
If you have any questions or you would like to learn more about how Fusions work, please visit the release page. It includes a series of blog posts, the BigML Dashboard and API documentation, the webinar slideshow as well as the full webinar recording.
