We’re happy to share new options to automatically analyze the text in your data. BigML has been supporting text fields as inputs for your supervised and unsupervised models for a long time, which pre-process your text data in preparation for Machine Learning models. Now, these text options have been extended as new ones have been added to further streamline your text analysis and enhance your models’ performance.
- BigML supports 15 new more languages. The total number has increased from 7 to 22 languages! Now you can upload your text fields in Arabic, Catalan, Chinese, Czech, Danish, Dutch, English, Farsi/Persian, Finish, French, German, Hungarian, Italian, Japanese, Korean, Polish, Portuguese, Turkish, Romanian, Russian, Spanish, or Swedish. BigML will auto-detect the language or languages (in case your dataset contains several languages in different fields) in your data. The detected language is key for the text analysis because it determines the tokenization, the stop word removal, and the stemming applied.
- Extended the stop words removal options: You can now opt to remove stop words for the detected language or for all languages. This option is very useful when you have many languages mixed in the same field. For example, social media posts or public reviews are usually written in several languages. Another related enhancement helps you decide the degree of aggressiveness that you want for the stop words removal i.e., light, normal, or aggressive. Depending on your main goal, there can be some stop words that may be useful for you, e.g., the words “yes” and “no” may be interesting since they express affirmative and negative opinions. A lower degree of aggressiveness will include some useful stop words in your model vocabulary.
- One of the greatest new additions to the text options is n-grams! Although you could already choose bigrams before, we’ve extended it so you can now include bigrams, trigrams, four-grams, and five-grams in your text analysis. Moreover, you can also exclude unigrams from your text and make the analysis based only on higher size n-grams (see the filter for single tokens below).
- Lastly, a number of optional filters to exclude uninteresting words and symbols from your model vocabulary have been added since specific words can introduce noise into your models depending on your context.
- Non-dictionary words (e.g., words like “thx” or “cdm”)
- Non-language characters (e.g., if your language is Russian, all the non-Cyrillic characters will be excluded)
- HTML keywords (e.g., href, no_margin)
- Numeric digits (all numbers containing digits from 0 to 9)
- Single tokens (i.e., unigrams, only n-grams of size 2 or more will be considered if selected)
- Specific terms (you can input any string and it will be excluded from the text)
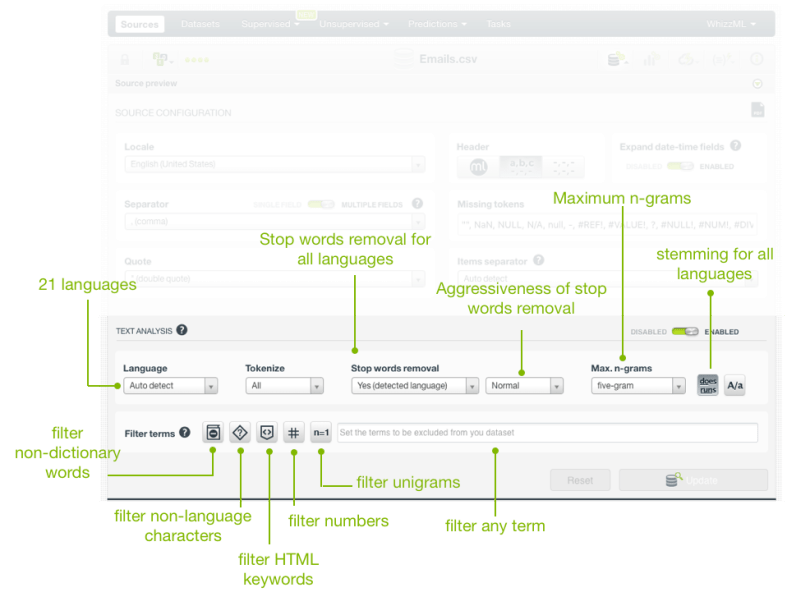
You can set up these options by configuring two different resources: sources and/or topic models. By configuring the source and then creating a dataset, you propagate the text analysis configuration to all the models (supervised or unsupervised) that you create from that dataset. Hence, an ensemble or an anomaly detector trained with this dataset will use a vocabulary shaped by the options configured at the source level. Topic models are the only resources for which you can re-configure these text options. This is because the topic model results are greatly impacted by the text pre-processing so BigML provides a more straightforward way to iterate on such models so you don’t need to go back to the source step each time.
Let’s illustrate how these new options work using the Hillary Clinton’s e-mails dataset from Kaggle. The main goal is to know the different topics in these e-mails without having to read them all. For this, we will create a topic model using this dataset. We assume you know how topic models work in BigML, otherwise, please watch this video.
We’re only using two fields from the full Kaggle dataset (“ExtractedSubject” and “ExtractedBodyText”) to create the topic model. First, we create the topic model with the BigML 1-click option which uses the default configuration for all the parameters.
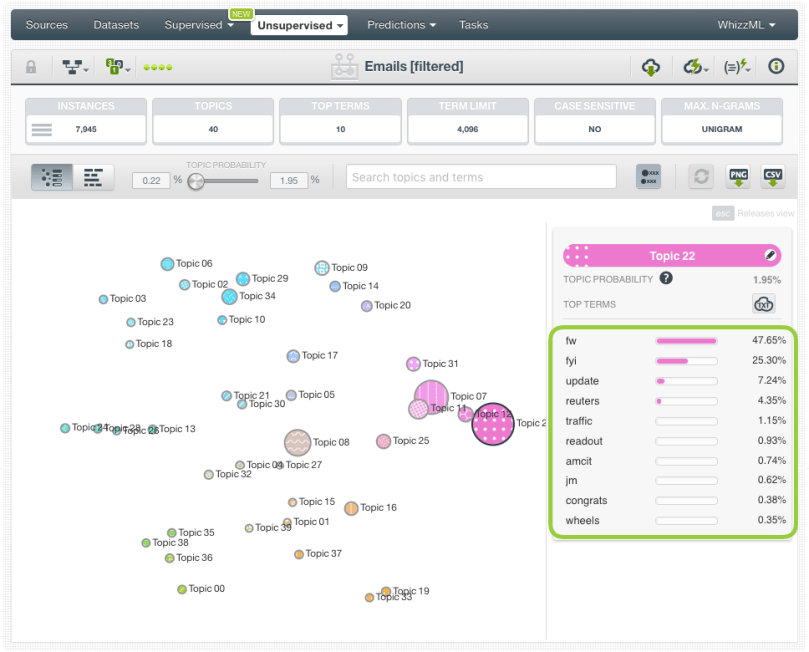
When the model is created, we can inspect the different topics by using the BigML visualization for topic models. You can see that we have some relevant topics like topic 36, which is about economic issues in Asia (mostly China). But most of the topics, even if they contain relevant terms, are also mixed with lots of frequent words, numbers, and acronyms (for example “fw”, “fyi”, “dprk”, “01”, “re”, “iii”, etc.) that don’t tell us much about the real content of the e-mails.
Let’s try to improve those results by configuring the text options offered by BigML. We can observe in our first model that there were some stopwords that we don’t really care much about such as “ok” or “yes”. Therefore, we set the stop words removal as “Aggressive” this time. We also had many terms and numbers that are not telling us anything about the e-mail themes, such as “09”, “iii” or “re”. To exclude those terms from our analysis, we’ll use the non-dictionary words and numeric digits filters. Finally, in order to get some more context, we’ll also include bigrams, trigrams, four-grams and five-grams to our topic model.
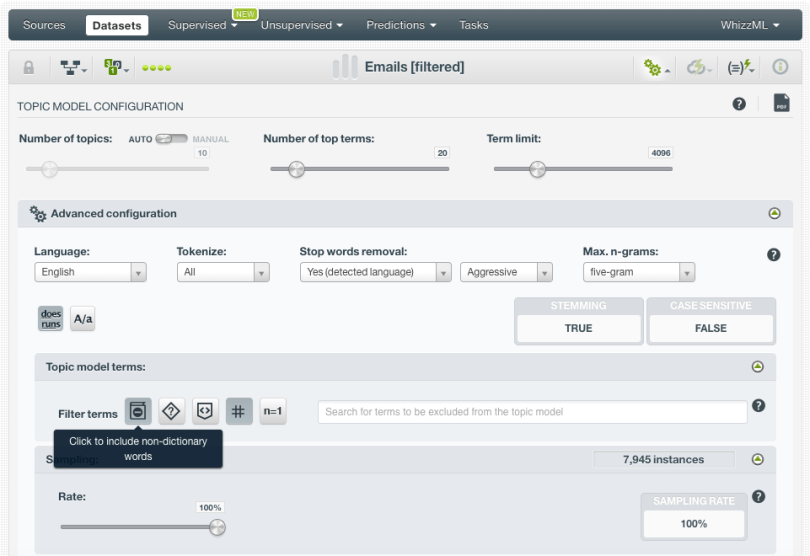
So we create the new topic model and… voilà! In a couple of clicks, we have a much more insightful model with more meaningful topics that help us better interpret the content of the underlying e-mails.
You can see that most of the meaningless words have disappeared and the terms within the topics are much more thematically related. For example, now we have five topics that contain the word “president” and talk about five different themes: European politics, current US government, US elections, US politics and Iran politics. In the model we built before, the minority thematics like Iran politics didn’t feature a topic of their own as they were mixed with other topics while other more frequent (but meaningless) words had topics of their own.
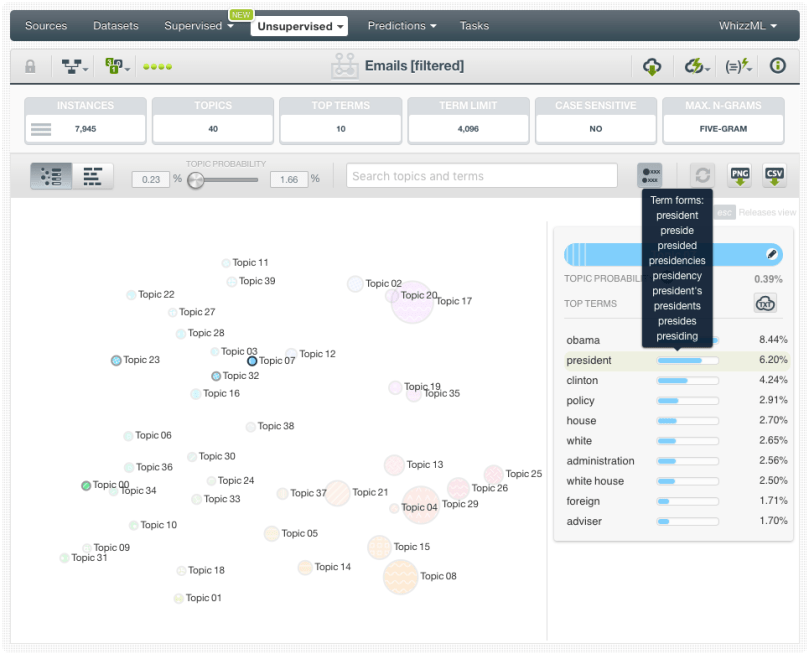
We may clean this model even further, and filter uninteresting words like “pm”, “am”, “fm”, etc. However, we feel satisfied enough with these topics and we prefer to spend the time creating a new model with a totally different approach.
Sometimes, the meaning of a single word can change if you look at the terms around it. For example, “great” may be a positive word, but “not so great” is indicating a bad experience. We can make this kind of analysis by using BigML n-grams and at the same time excluding unigrams from the topic model. The resulting model only includes topics that contain bigrams, trigrams, four-grams and five-grams. All topics show delimited themes that may be slightly different than the topics we obtained before. For example, the topic about the English politics was too broad before, it was mixed with European politics, however now it has two topics for its own.
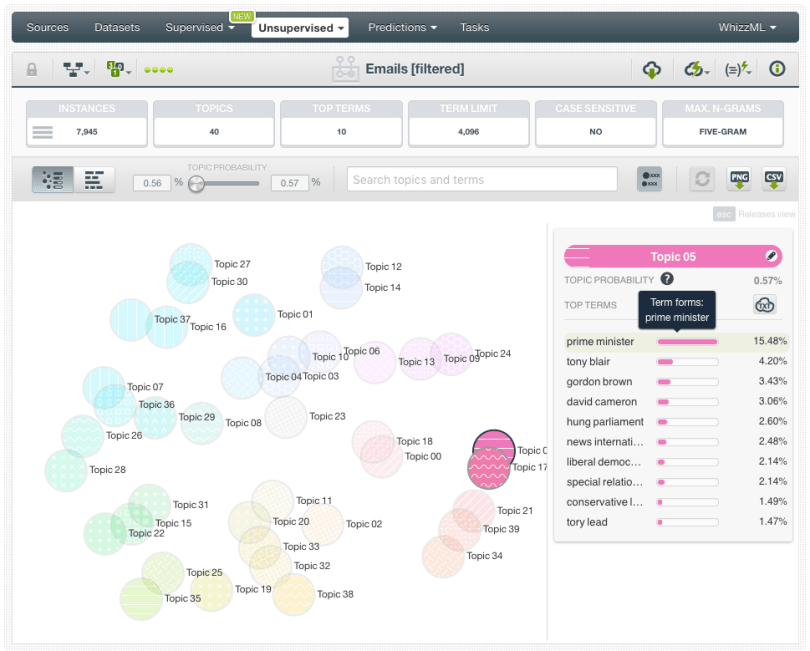
Ok, topic models and the new text options on BigML are great, but what is the main goal of all this? We could use these topics for many purposes. For example, to analyze the most mentioned topics in Hillary Clinton e-mails by calculating per-topic distributions for each e-mail (very easy with BigML’s topic distribution feature). Moreover, you could use the per-topic distributions as inputs to build an Association and see which topics are more strongly correlated. In summary, when you have a topic model created and the per-topic distributions calculated, you can use them as inputs for any supervised or unsupervised models.
Thanks for reading! As usual, we look forward to hearing your feedback, comments, or questions. Feel free to send them to support@bigml.com. To learn more, please visit this page.

Reblogged this on BLACK BOX PARADOX and commented:
Very interesting new text analytics tool from BigML! And all analysis is done using Web interface only with no need for coding. I will be trying it myself this weekend. 🙂