The BigML Team is bringing Principal Component Analysis (PCA) to the BigML platform on December 20, 2018. As explained in our introductory post, PCA is an unsupervised learning technique that can be used in different scenarios such as feature transformation, dimensionality reduction, and exploratory data analysis. PCA, explained in a nutshell, fundamentally transforms a dataset defined by possibly correlated variables into a set of uncorrelated variables, called principal components.
In this post, we will take you through the five necessary steps to upload your data, create a dataset, create a PCA, analyze the results and finally make projections using the BigML Dashboard.

We will use the training data of the Fashion MNIST dataset from Kaggle which contains 60,000 Zalando’s fashion article images that represent 10 different classes of products. Our main goal will be to use PCA to reduce the dataset dimensionality which has 784 fields containing pixel data to build a supervised model that predicts the right product category for each image.

1. Upload your Data
Start by uploading your data to your BigML account. BigML offers several ways to do so: you can drag and drop a local file, connect BigML to your cloud repository (e.g., S3 buckets) or copy and paste a URL. In this case, we download the dataset from Kaggle and just drag and drop the file.
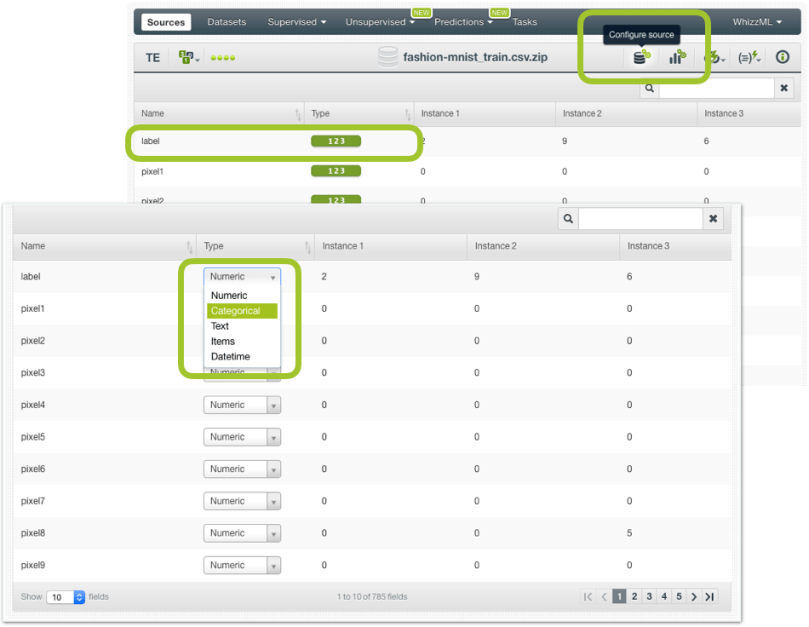
BigML automatically identifies the field types. We have 784 input fields containing pixel data and correctly set as numeric by BigML. The objective field “label” is also identified as numeric because it contains digit values from 0 to 9, however, we need to convert this field into categorical since each digit of this field represents a product category instead of a continuous numeric value. We can easily do this by clicking on the “Configure source” option shown in the image below.
2. Create a Dataset
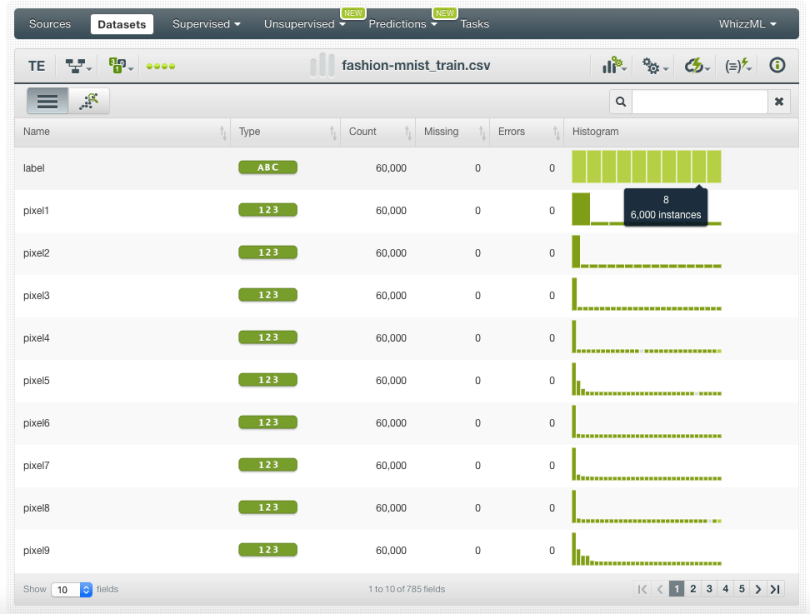
From your source view, use the 1-click dataset menu option to create a dataset, a structured version of your data ready to be used by a Machine Learning algorithm.
In the dataset view, you will be able to see a summary of your field values, some basic statistics, and the field histograms to analyze your data distributions. You can see that our dataset has a total of 60,000 instances where each of the 10 classes in the objective filed has 6,000 instances.
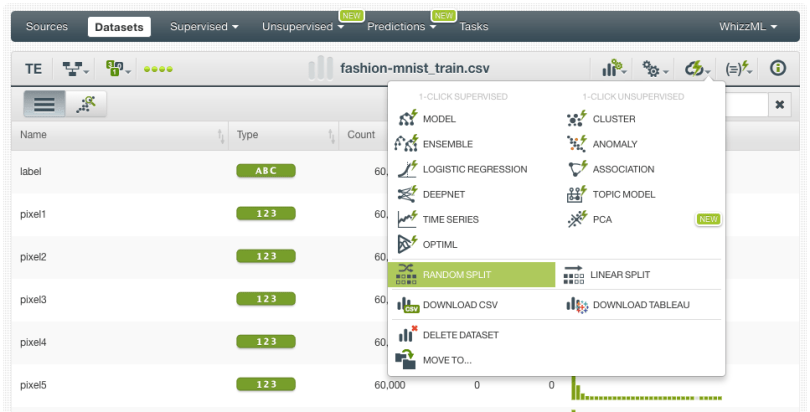
3. Create a PCA
Before creating the PCA we need to split our dataset into two subsets: 80% for training and 20% for testing. This is because our main goal in building a PCA is to reduce our data dimensionality to build a supervised model that can predict the product categories afterwards. If we used the full dataset to build the PCA and then split the resulting dataset into the train and tests subsets to build the supervised model, we would be introducing data leakage, i.e., the training set would contain information of the test set. However, this split wouldn’t be necessary if we wanted to use PCA for other purposes such as for data exploration.
Next, we take the 80% training set to create the PCA. You can use the 1-click PCA menu option, which will create the model using the default parameter values, or you can adjust the parameters using the PCA configuration option. Another important thing to consider at this point is that we need to exclude our objective field from the PCA creation to avoid another possible data leakage scenario. Otherwise, we will be mixing information about the objective field into the principal components that we will use as predictors for our supervised model.
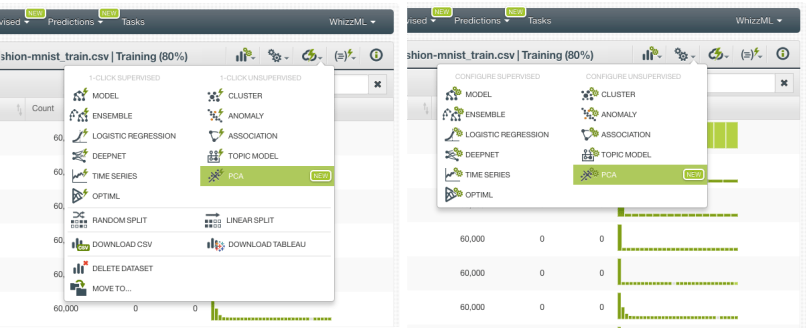
BigML provides the following parameters to configure your PCA:
- Standardize: allows you to automatically scale numeric fields to a 0-1 range. Standardizing implies assigning equal importance to all the fields regardless if they are on the same scale. If fields do not have the same scale and you create a PCA with non-standardized fields, it is often the case that each principal component is dominated by a single field. Thus, BigML enables this parameter by default.
- Default numeric value: PCA can include missing numeric values as valid values. However, there can be situations for which you don’t want to include them in your model. For those cases, you can easily replace missing numeric values with the field’s mean, median, maximum, minimum or with zero.
- Sampling: sometimes you don’t need all the data contained in your test dataset to generate your PCA. If you have a very large dataset, sampling may very well be a good way to get faster results.
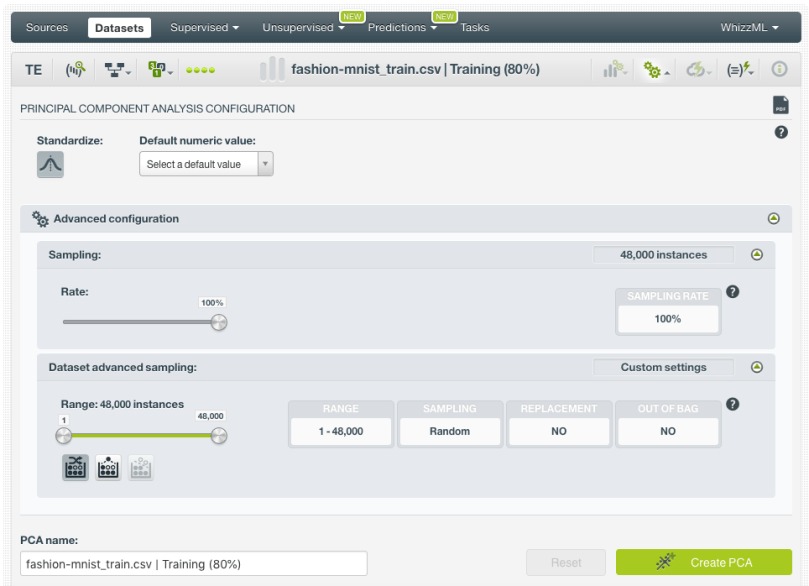
4. Analyze your PCA Results
When your PCA is created, you will be able to visualize the results in the PCA view, which is composed of two main parts: the principal component list and the scree plot.
- The principal component list allows you to see the components created by the PCA (up to 200). Each of the principal components is a linear combination of the original variables, is orthogonal to all other components, and ordered according to the variance. The variance of each component indicates the total variability of the data explained by that component. In this list view, you can also see the original field weights associated with each component that indicate each field’s influence on that component.
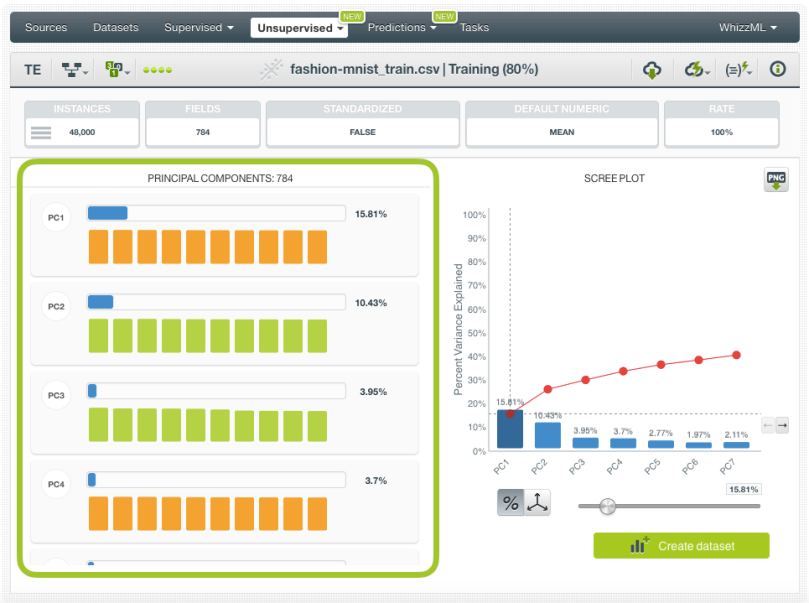
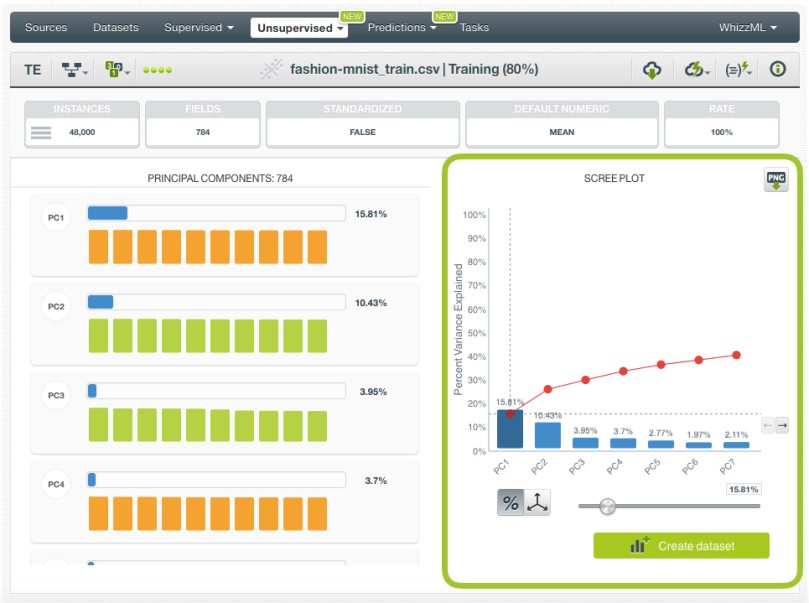
- The scree plot helps you to graphically see the amount of variance explained by a given subset of components. It can be used to select the subset of components to create a new dataset either by setting a threshold for the cumulative variance or by limiting the total number of components using the slider shown in the image below. Unfortunately, there is not an objective way to decide the optimal number of components for a given cumulative variance. This depends on the data and the problem you are looking to solve so be sure to apply your best judgment given your knowledge of the context.
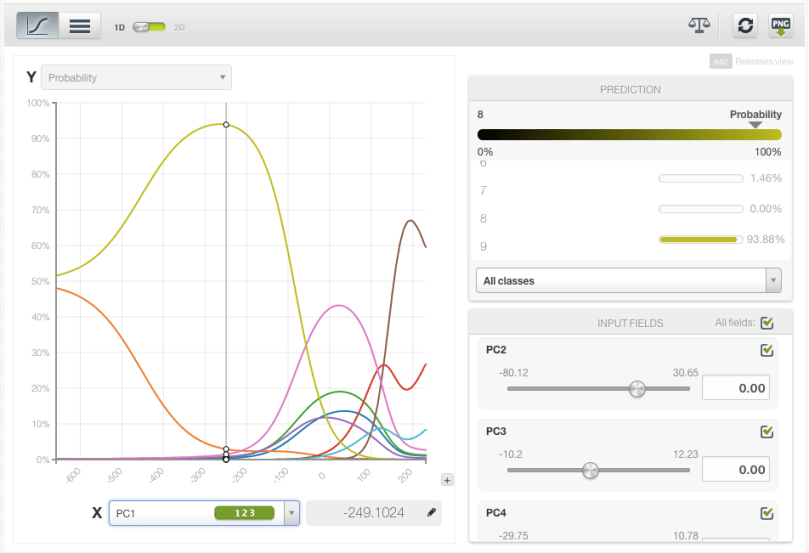
5. Create Projections
PCA models can be used to project the same or new data points to a new set of axes defined by the principal components. In this case, we want to make projections on our two subsets (the 80% for training and the 20% for testing) so we can replace the original fields by the components calculated by our PCA to create and evaluate a supervised model.
Create a Dataset from the PCA view
If you want to get the components for the same dataset that you used to create the PCA, you can use the “Create dataset” button that BigML provides in the PCA view. This option is like a shortcut that creates a batch projection behind the scenes. For our 80% subset, we are using this faster option. We can see in the scree plot that selecting around 300 components (out of the 784 total components) using the slider shown in the image below, gives us more than 80% of the cumulative variance which seems a large enough number to create a new dataset without losing much information from the original data.
After the dataset is created we can find it listed on our Dashboard. The new dataset will include the original fields used to create the PCA and the new principal components taking into account the threshold set.
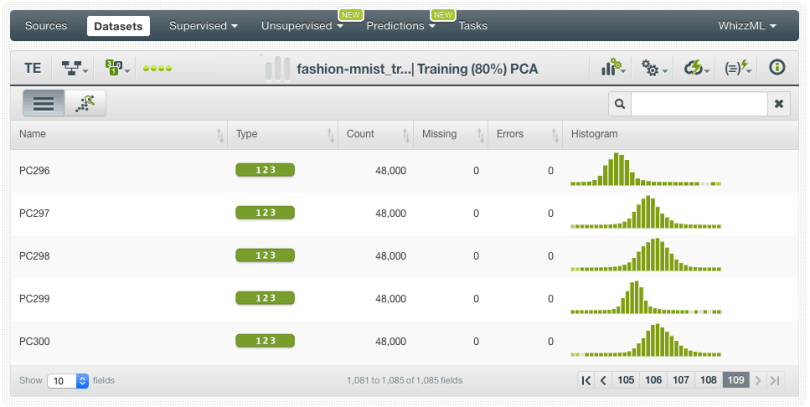
Create a Batch Projection
If you want to use a different dataset than the one used to create the PCA, then you need to take the long path and click on the “Batch projection” option. We are using this option for our 20% subset. The step-by-step process is explained below.
1. Click on the option “Batch projection” from the PCA view.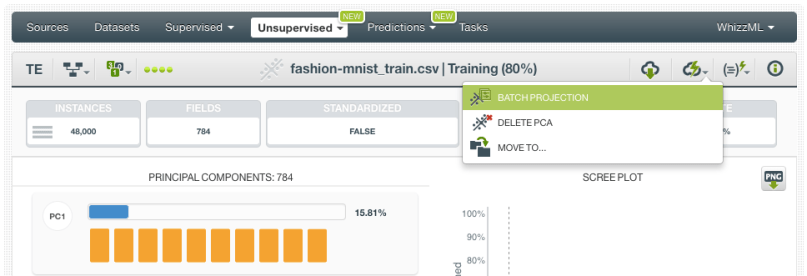
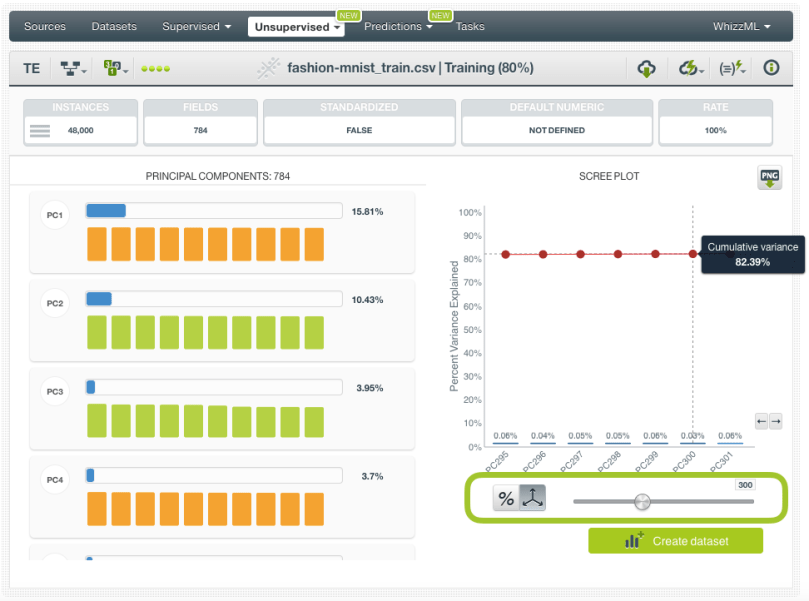
2. Select the dataset you want to use and configure the batch projection if you want. In this case, we are selecting the 20% test subset and we are limiting the number of components to be returned up to 300 by using the slider shown in the image below (as we did with the training set before). 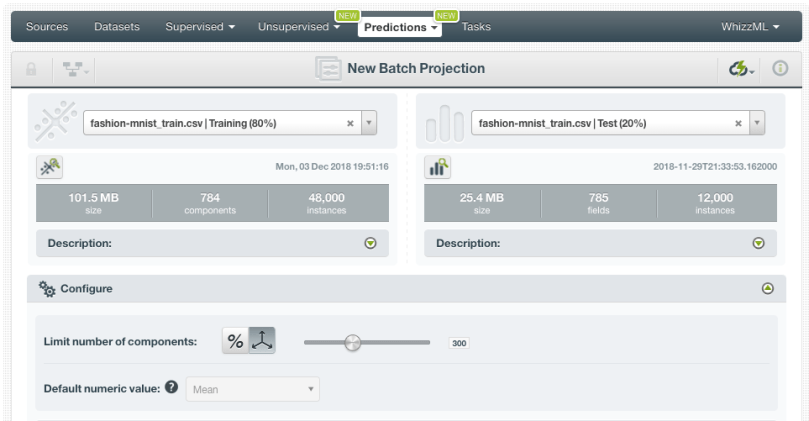 We can also choose to remove the original fields or not. In this case, we are keeping them since we want to use the same 80% and 20% subsets to build and evaluate two different supervised models: one with the original fields and another one with the components.
We can also choose to remove the original fields or not. In this case, we are keeping them since we want to use the same 80% and 20% subsets to build and evaluate two different supervised models: one with the original fields and another one with the components.
3. When the batch projection is created, you can find the new dataset containing the components in your dataset list view.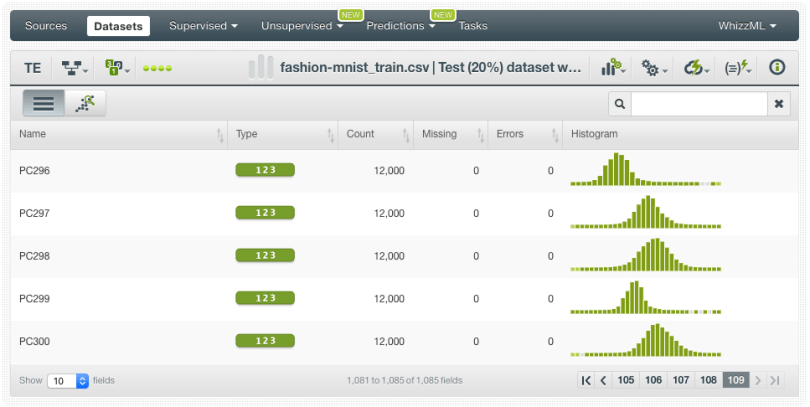
Final Results
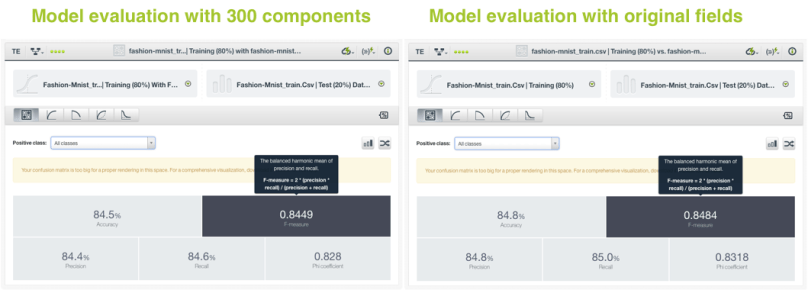
Using our reduced dataset with the 300 components, we create a logistic regression to predict the product categories. We also create another logistic regression that uses the original 784 fields that contained the pixel data so we can compare both models’ performances.
When we evaluate them, we can observe that the performances of the 300 component models (f-measure=0.8449) are almost exactly the same as the one from the model that used all of the original fields (f-measure=0.8484) despite the fact that we only used ~40% of the original fields. This simple act allows us to reduce model complexity considerably, in turn, decreasing the training and prediction times.
Want to know more about PCA?
If you would like to learn more about Principal Component Analysis and see it in action on the BigML Dashboard, please reserve your spot for our upcoming release webinar on Thursday, December 20, 2018. Attendance is FREE of charge, but space is limited so register soon!
