The new BigML release is here! Join us on Thursday, December 20, 2018, at 10:00 AM PST (Portland, Oregon. GMT -08:00) / 07:00 PM CET (Valencia, Spain. GMT +01:00) for a FREE live webinar to discover the latest addition to the BigML platform. We will be showcasing Principal Component Analysis (PCA), a key unsupervised Machine Learning technique used to transform a given dataset in order to yield uncorrelated features and reduce dimensionality. PCA is most commonly applied in fields with high dimensional data including bioinformatics, quantitative finance, and signal processing, among others.
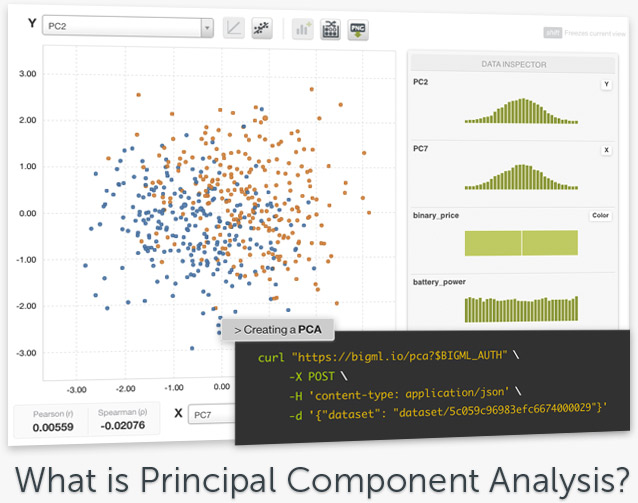
Principal Component Analysis (PCA), available on the BigML Dashboard, API and WhizzML for automation as of December 20, 2018, is a statistical technique that transforms a dataset defined by possibly correlated variables (whose noise negatively affects the performance of your model) into a set of uncorrelated variables, called principal components. This technique is used as the first step in dimensionality reduction, especially for those datasets with a large number of variables, which helps improve the performance of supervised models due to noise reduction. As such, PCA can be used in any industry vertical as a preprocessing technique in the data preparation phase of your Machine Learning projects.
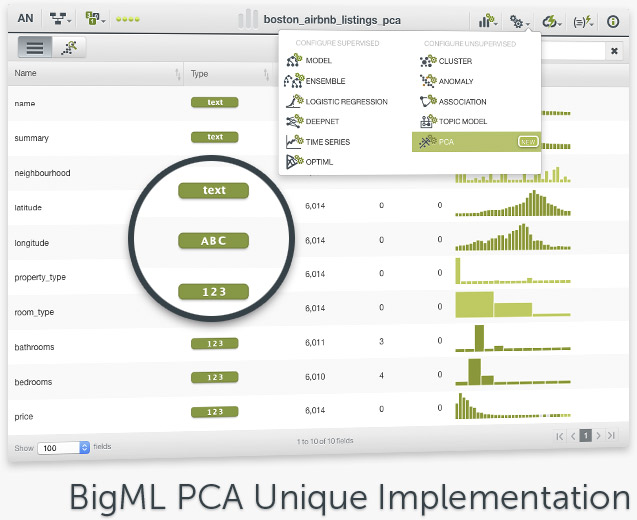
BigML PCA is distinct from other implementations of the PCA algorithm, our Machine Learning platform lets you transform many different data types in an automatic fashion that does not require you to configure it manually. That is, BigML’s unique approach can handle numeric and non-numeric data types, including text, categorical, items fields, as well as combinations of different data types. To do so, BigML PCA incorporates multiple factor analysis techniques, specifically, Multiple Correspondence Analysis (MCA) if the input contains only categorical data, and Factorial Analysis of Mixed Data (FAMD) if the input contains both numeric and categorical fields.
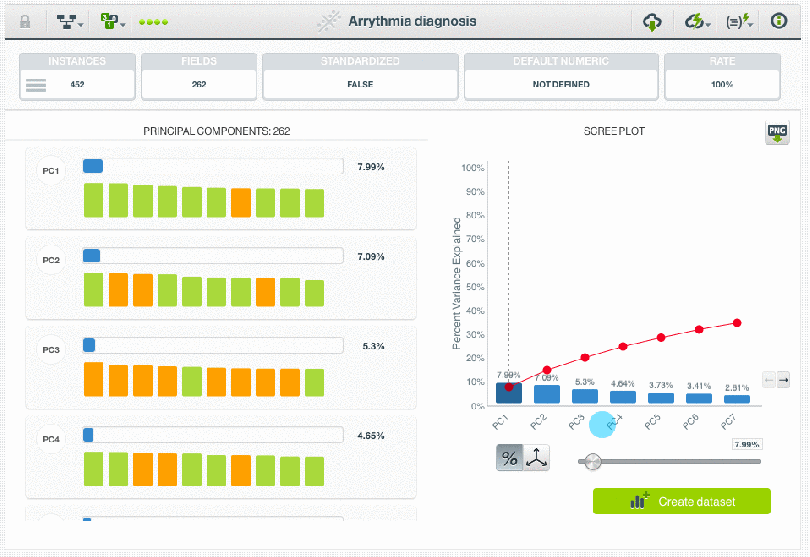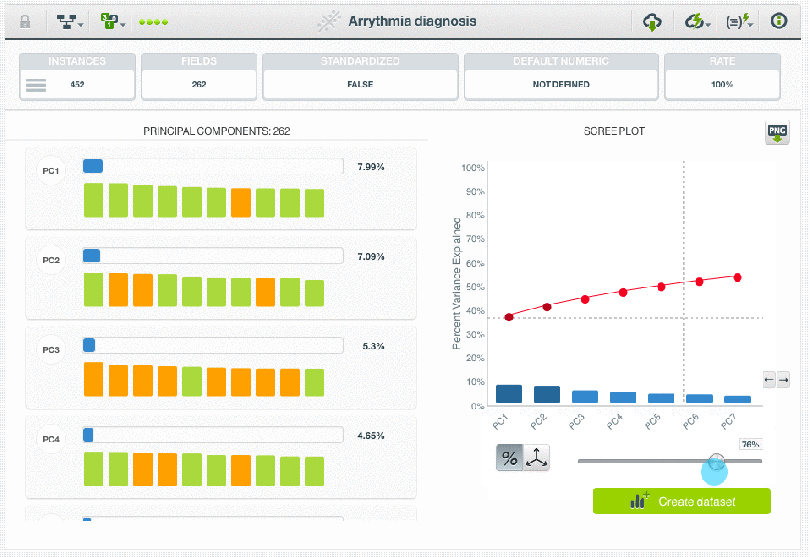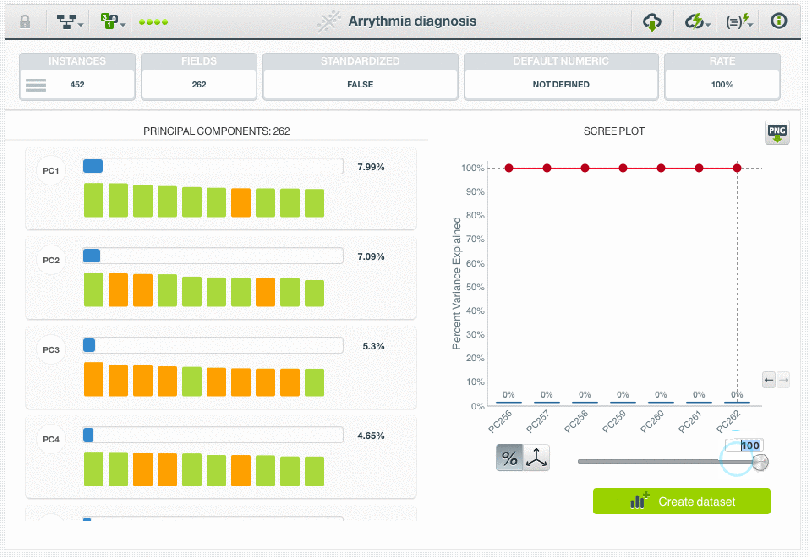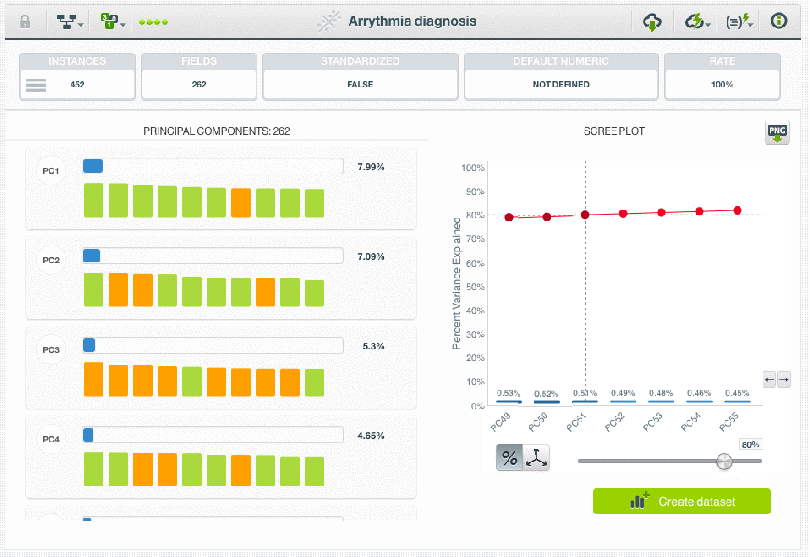

When we work with high dimensional datasets, we often have the challenge of extracting the discriminative information in the data while removing those fields that only add noise and make it difficult for the algorithm to achieve the expected performance. PCA is ideal for these events. While a PCA transformation maintains the dimensions of the original dataset, it is typically applied with the goal of dimensionality reduction. Reducing the dimensions of the feature space is one method to help reduce supervised model overfitting, as there are fewer relationships between variables to consider. The principal components yielded by a PCA transformation are ordered by the amount of variance each explains in the original dataset. Plots of the cumulative variance explained, also known as scree plots, are one way to interpret appropriate thresholds for how many of the new features can be eliminated from a dataset while preserving most of the original information.
Want to know more about PCA?
Please join our free, live webinar on Thursday, December 20, 2018, at 10:00 AM PT. Register today as space is limited! Stay tuned for our next 6 blog posts that will gradually present PCA and how to benefit from it using the BigML platform.
Note: In response to user inquiries, we are including links here to the datasets featured in the two images above showing the BigML Dashboard. For the first, we filtered a subset of AirBNB data fields available on Inside AirBNB, and for the second, the Arrythmia diagnosis dataset is available on the BigML Gallery. We hope you enjoy exploring the data on your own!

I was trying to reblog this post on my personal blog but don’t see this option anymore.
Reblogged this on BLACK BOX PARADOX and commented:
PCA is a statistical technique that transforms a dataset defined by possibly correlated variables (whose noise negatively affects the performance of your model) into a set of uncorrelated variables, called principal components. Read more below.