BigML’s new release is here! Join us on Thursday, July 12, 2018, at 10:00 AM PDT (Portland, Oregon. GMT -07:00) / 07:00 PM CEST (Valencia, Spain. GMT +02:00) for a FREE live webinar to find out the enhanced version of the BigML platform. We will be showcasing Fusions, the new BigML resource that solves classification and regression problems using the power of multiple supervised models with a single click!
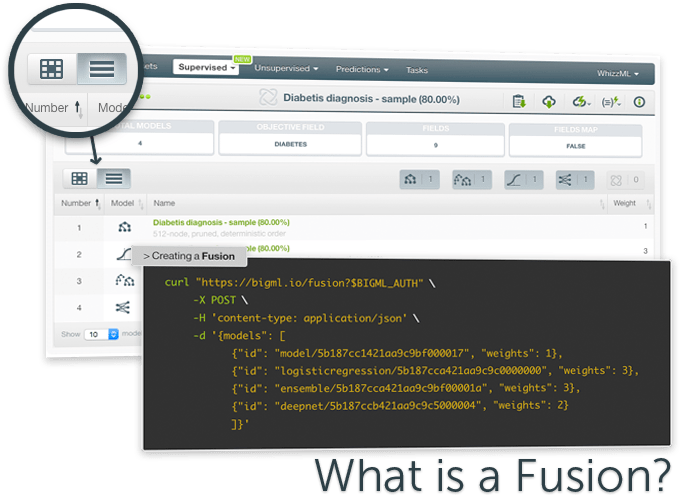
The BigML Development Team has been working hard to bring Fusions to our platform, which will be available on the BigML Dashboard, API, and WhizzML on July 12. A BigML Fusion is a combination of several Machine Learning models that can include decision tree models, ensembles, logistic regressions, and deepnets. Following the same principle as ensembles, Fusions aggregate predictions to balance out the individual weaknesses of single models, and as a result, typically provide better performance than any of the individual components. Thus, Fusions can then be seen as a heterogeneous ensemble composed of different types of supervised models instead of decision trees only.
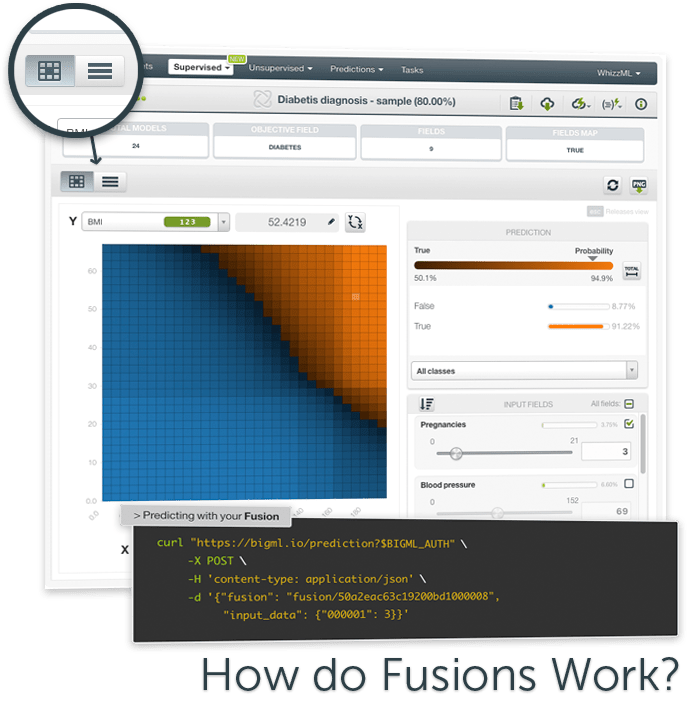
You can use Fusions to solve classification and regression problems. For classification problems, Fusions perform an average of the per-class probabilities across all the component models and predicts the class with the highest probability. For regression models, the final prediction is the result of averaging the per-model predicted values. You can also assign weights to your models so BigML will perform a weighted average to calculate the final prediction. It’s worth mentioning that all the Machine Learning models composing your Fusion can be created using different datasets and different input fields, but they all must have the same objective field. Furthermore, the models of a given Fusion can be built separately or you can let OptiML build them for you automatically.
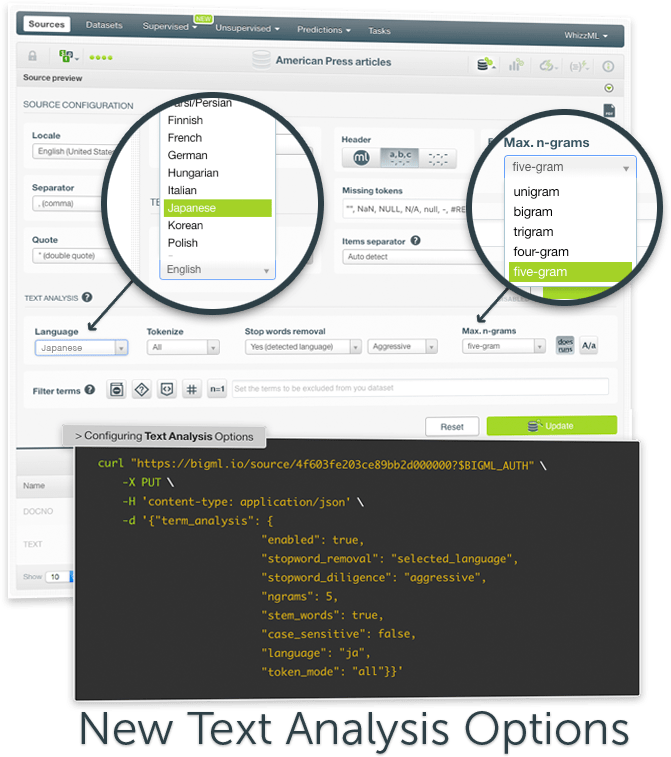
In addition to the main resource of this launch, BigML is also releasing new Text Analysis options to help you identify more patterns in your text data for both supervised and unsupervised models. Now, you can process text in 22 different languages, we have enabled the maximum n-gram size to consider for your text analysis, there are new stop words removal techniques available, as well as stemming for the new languages, and the option to filter and exclude certain groups of unwanted words. You can configure these options from your source so they will be taken into account by all your models. Moreover, you can easily configure these options for your topic models regardless of your original source configuration.
Want to know more?
If you have any questions or you would like to learn more about how Fusions and the new Text Analysis options work, please visit the release page. It includes a series of blog posts, the BigML Dashboard and API documentation, the webinar slideshow as well as the full webinar recording.
