One click and you’re done, right? That’s the promise of OptiML and automated Machine Learning in general, and to some extent, the promise is kept. No longer do you have to worry about fiddly, opaque parameters of Machine Learning algorithms, or which algorithm works best. We’re going to do all of that for you, trying various things in a reasonably clever way until we’re fairly sure we’ve got something that works well for your data.
Sounds really exciting, but hold your horses. Yes, we’ve eliminated the need to optimize your ML model, but that doesn’t mean you’re out of the loop. You still have an important part to play because only you know how the model is going to be deployed in the real world. Said another way, only you know precisely what you want.
In this post, the last one of our series of posts introducing OptiML, I’m going to talk about a couple of the things you still have to worry about even if you use OptiML to find the best model. And I’m not talking about data wrangling or feature engineering, though you certainly still have to do that. I’m talking about ways that you can really make or break the process of model selection.
It’s important here to realize that these worries aren’t at all unique to OptiML. These are things you always have to worry about whenever you’re trying to choose from among the infinity of possible Machine Learning methods. What OptiML does is brings these worries front and center where they belong, rather than hiding out among lists of possible parameters.
We Have The Technology
The core technology in OptiML is Bayesian Parameter Optimization, which I’ve written about a few other times. The basic idea is simple: Since the performance of a model type with given parameters is dependent on the training data, we’ll begin by training and testing a few different models with varying parameters. Then, based on the performance of those models, we’ll learn a regression model to predict how well other sets of parameters will perform on the same data. We use that model to generate a new set of “promising” parameters to evaluate, then feed those back into our regression model. Rinse and repeat.
There’s a little bit of cleverness here in choosing the next set of promising parameters. While you want to choose parameters that are likely to work well, you also don’t want to choose parameters that are too close to what you’ve already evaluated. This trade-off between optimization and exploration motivates various “acquisition functions” that attempt to choose candidates for evaluation that are both novel and likely to perform well.
But all of that is handled for you behind the scenes. It seems like this thing is absolutely primed to give you exactly what you want. So what could possibly go wrong?
Nothing, as long as you and the algorithm are on the same page about exactly what you want.
What Do You Really Want?
If you open up the configuration panel for OptiML, you’ll notice that one of the first choices we offer you is that of the metric to optimize. This is the metric that will drive the search above. That is, the search’s goal will be to find the best possible value for the metric you specify.
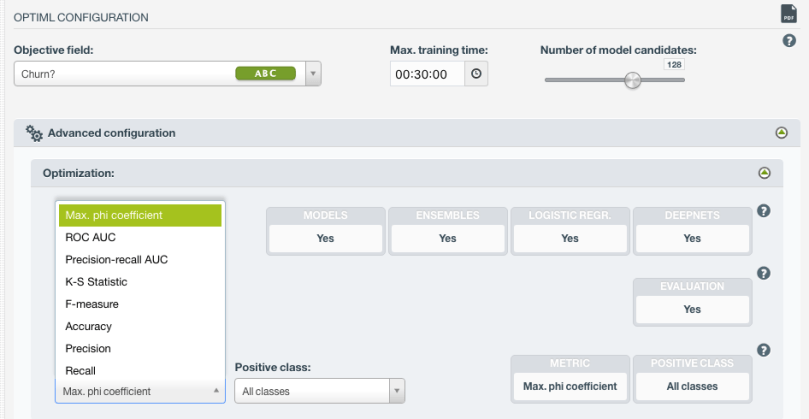
For the non-experts among us, the list of metrics probably looks like word salad. Which one should you choose? To give you a rough idea, I’ve made a flowchart that should get you to a metric that suits your use case.
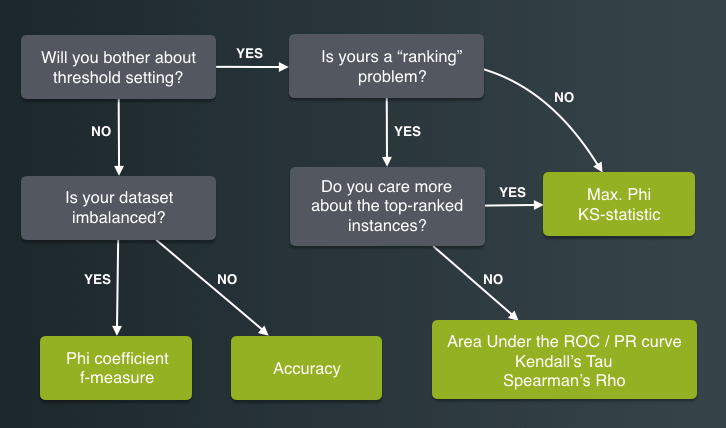
The first question in that flowchart is whether or not you want to bother with setting a prediction threshold. This refers to the use of BigML’s “operating point” feature. Generally, if you can, you’ll want to do this, as it allows you finer control of the model’s behavior. For users with less technical savvy, though, it’s significantly easier to just use the default threshold. In this case, if your dataset is balanced, you can simply tell OptiML to optimize the accuracy. If the dataset is imbalanced, you might want to try optimizing the phi coefficient, or the F-measure, which control in different ways for imbalanced data.
If you are willing to set a threshold, then you can go a bit deeper. The first thing you can ask yourself is whether or not you have a ranking problem. This is a problem for which the individual correctness of predictions isn’t the primary goal, and instead we seek to rank a group of points so that the positive ones are in general higher ranked than the negative ones.
A good example of a ranking-style prediction is ranking stocks for stock picking. Typically, you’re going to have some number of stocks you’re willing buy which is much smaller than the number of total stocks you could buy. What matters to you in this case isn’t whether you get each and every instance right. What matters is whether or not those top few examples are likely to be positive.
A second concern here, if you have a ranking problem is whether or not the top of the ranking is more important than the rest. The stock picking example is clearly a case where it is: You care about the profitability or lack thereof of the stocks you pick, and are less concerned with the ones you didn’t, so the correctness of the top of the ranking, of those stocks the algorithm told us to pick, is of higher importance than the correctness of those ranked near the bottom. In this case, a metric based on the optimal threshold for the data, like Max. Phi, will typically correlate well with a model’s performance.
The opposite case is a draft-style selection, where you don’t necessarily get to pick from the top of the order. You may pick in the middle or at the end, but you always want your pick to have highest possible chance of being correct. In this case, metrics like the ROC AUC, or one of the rank correlation metrics like the Spearman correlation would be an appropriate choice.
Optimizing for the right metric is one way you can squeeze a little bit more performance out of your model. If a one or two percent difference isn’t that important to you, you can do perfectly fine without this step. If you’re very concerned about performance, however, or have a very particular way of measuring performance, it’s important to understand these metrics: There’s pretty good evidence that these metrics aren’t in complete agreement a significant amount of the time, so take your time and choose the right one.
Cross-Validation: You’re Doing It Wrong!
So, once we have our metric selected, how does OptiML decide which of your possible models is best? Of course, by default, we use cross-validation, as does most everyone. The idea here, if you’re unfamiliar, is that you hold out a random chunk of the data as the evaluation set and train your model on the rest. Then, just to be sure you haven’t gotten lucky (say, by choosing most of the difficult-to-classify points into your training data rather than your test data), you do it a bunch of times and aggregate the results.
It’s a simple idea that tends to work well in practice . . . until it goes horribly wrong in the worst possible way, which is why we offer the option for a custom holdout set.
Within cross-validation lies a brutal trap for the unwary: If your training instances contain information about each other that will be unavailable in a production setting, cross-validation will give results that are anywhere from “optimistic” to “wildly optimistic”.
What do I mean by “information about each other”? One place this happens a lot is with data that’s distributed in time, and where adjacent points share a class. Consider stock market prediction, supposing you want to predict whether a stock is going to be higher or lower at the end of the day for each minute of the day, based on, say, the trailing ten minutes of data (volume, price, and so on). First note that it’s very likely that adjacent points share a class (if the market’s close is higher than its level at 10:30, probably that is also true at 10:31 and 10:32). Note also that these adjacent minutes also share a lot of history; most of their trailing 10 minutes overlap.
What does all of this add up to? You’ve got points that are near-duplicates of one another in your dataset. If you take a random chunk of data as test data, it’s likely that you have near-duplicates for all of those points in your training data. Your model, having seen essentially the right answers, will perform very well, and cross-validation will tell you so. And it will be disastrously wrong, because on days in the future, where you don’t have answers from nearby instances, the classifier will fail completely. Said another way, cross-validation gives you results for predictions on days that you see in training. In the real world, your model will not have the benefit of seeing points from the test day in the training data.
Lest you think this is a rare case, consider trying to predict a user’s next action in some sort of UI context. You might have 10,000 actions for training, but only a couple dozen users. Users tend to do the same thing in the same way over and over again, so for every action in your training data, there’s probably several near-duplicates in your test data. The model will get very good at predicting the behavior of your training users, and cross-validation will again tell you so. But if you think that performance is going to generalize to a novel user, you’re very much mistaken.
It’s a problem that’s probably more common than you think, and the root cause is again Machine Learning giving you just what you asked for. In this case, you’re asking, “if I knew the correct classes for a random sample of most of the points in the dataset, how well could I predict the rest”. And cross-validation answers “Very well!” and gives you a fist bump. Many times, the answer to that question is a good proxy for the answer to the real question, which is, “how well will my model predict on data that is not part of the dataset?” But for certain cases like the ones above, it most certainly is not.
The solution isn’t difficult – you just construct a holdout set that measures what you want, rather than what cross-validation is telling you. If it’s how a model trained on past stock prices will predict future stock prices, you hold out the most recent data for testing and train on the past. If you want to know how well your UI model will generalize to novel users, you hold out data from some users (all of their data) and train on the remaining users. Once you’ve constructed the appropriate holdout dataset, you pass it to OptiML and get your answer.
Sometimes it can be difficult to know for sure if your problem falls into this category. But if your problem has a character where the data comes in “bins” of possibly correlated instances, like days, users, retail locations, servers, cities, etc., it never hurts to just try a test where you hold out some bins and test on others. If you see results that are worse than naive cross-validation, you should be very suspicious.
The Big Picture
Automated Machine Learning doesn’t know how you’re going to deploy your model in the real world. Unless you tell it differently, the best it can do is make assumptions that are true in many cases and hope for the best. Ensuring the model is optimized for use in the real world and that you have a reasonable estimate of its performance therein is always part of the due diligence you have to perform when engineering a Machine Learning solution. OptiML allows you to focus on these choices – the parts of your ML problem outside of the actual data – and leaves model optimization to us.
And remember, whether or not you use OptiML, BigML, or any other ML software tool, the choice of metric and manner of evaluation are important issues that you ignore at your own peril! The more we can push these “common sense rules” about Machine Learning into the general discourse about the subject, the closer we get to a world where anyone can use Machine Learning.
Want to know more about OptiML?
If you have any questions or you would like to learn more about how OptiML works, please visit the release page. It includes a series of blog posts, the BigML Dashboard and API documentation, the webinar slideshow as well as the full webinar recording.
