Very often datasets are imbalanced. That is, the number of instances for each of the classes in the target variable that you want to predict is not proportional to the real importance of each class in your problem. Usually, the class of interest is not the majority class. Imagine a dataset containing clickstream data that you want to use to create a predictive advertising application. The number of instances of users that did not click on an ad would probably be much higher than the number of click-through instances. So when you build a statistical machine-learning model of an imbalanced dataset, the majority (i.e., most prevalent) class will outweigh the minority classes. These datasets usually lead you to build predictive models with suboptimal classification performance. This problem is known as the class-imbalance problem and occurs in a multitude of domains (fraud prevention, intrusion detection, churn prediction, etc). In this post, we’ll see how you can deal with imbalanced datasets configuring your models or ensembles to use weights via BigML’s web interface. You can read how to create weighted models using BigML’s API here and via BigML’s command line here.

Weights
A simple solution to cope with imbalanced datasets is re-sampling. That is, undersampling the majority class or oversampling the minority classes. In BigML, you can easily implement re-sampling by using multi-datasets and sampling for each class differently. However, usually basic undersampling takes away instances that might turn to be informative and basic oversampling does not add any extra information to your model.
Another way to not dismiss any information and actually work closer to the root of the problem is to use weights. That is, weighing instances accordingly to the importance that they have in your problem. This enables things like telecom customer churn models where each customer is weighted according to their Lifetime Value. Let’s next see what the impact of weighting a model might be and also examine the options to use weights in BigML.
The Impact of Weighting
Let me illustrate the impact of weighting on model creation by means of two sunburst visualizations for models of the Forest Covertype dataset. This dataset has 581,012 instances that belong to 7 different classes distributed as follows:
- Lodgepole Pine: 283,301 instances
- Spruce-Fur: 211,840 instances
- Ponderosa Pine: 35,754 instances
- Krummholz: 20,510 instances
- Douglas-fir: 17,367 instances
- Aspen: 9,493 instances
- Cottonwood-Willow: 2,747 instances
The first sunburst below corresponds to a single (512-node) model colored by prediction that I created without using any weighting. The second one corresponds to a single (512-node) weighted model created using BigML’s new balance objective option (more on it below). In both sunbursts, red corresponds to the Cottonwood-Willow class and light green to the Aspen class. In the first sunburst, you can see that the model hardly ever predicts those classes. However, in the sunburst of the weighted model you can see that there are many more red and light green nodes that will predict those classes.

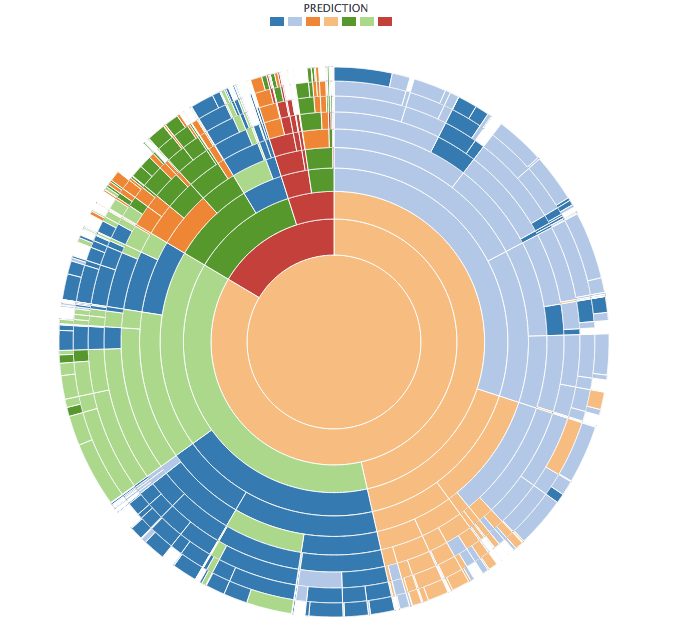
So as you can see, weighting helped make us aware of outcomes of predicted classes that are under-represented in the input data that otherwise would be shadowed by over-represented values.
Weighting Models in BigML
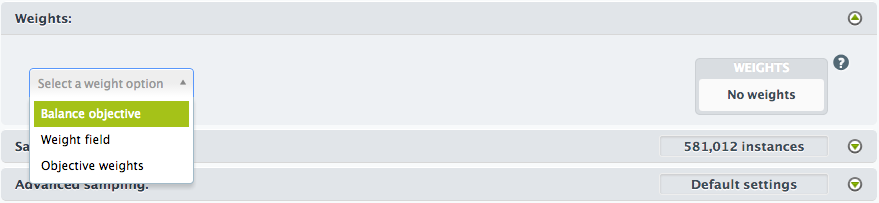
BigML gives you three ways to apply weights to your dataset:
- Using one of the fields in your dataset as a weight field;
- Specifying a weight for each class in the objective field; or
- Automatically balancing all the classes in the objective field.
Weight Field
Using this option, BigML will use one of the fields in your dataset as a weight for each instance. If your dataset does not have an explicit weight, you can add one using BigML new dataset transformations. Any numeric field with no negative or missing values is valid as a weight field. Each instance will be weighted individually according to the value of its weight field. This method is valid for both classification and regression models.

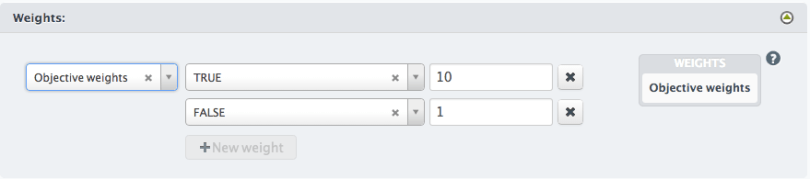
Objective Weight
This method for adding weights only applies to classification models. A set of objective weights may be defined, one weight per objective class. Each instance will be weighted according to its class weight. If a class is not listed in the objective weights, it is assumed to have a weight of 1. Weights of value zero are valid as long as there are some other positive valued weights. If every weight does end up being zero (this can happen, for instance, if sampling the dataset produces only instances of classes with zero weight) then the resulting model will have a single node with a nil output.
Balance Objective
The third method is a convenience shortcut for specifying weights for a classification objective which are inversely proportional to their category counts. This gives you an easy way to make sure that all the classes in your dataset are evenly represented.

Finally, bear in mind that when you use weights to create a model its performance can be significantly impacted. In classification models, you’re actually trading off precision and recall of the classes involved. So it’s very important to pay attention not only to the plain performance measures returned by evaluations but also to the corresponding misclassification costs. That is, if you know the cost of a false positive and the cost of a false negative in your problem, then you will want to weigh each class to minimize the overall misclassification costs when you build your model.

{kind=link}
One comment