The idea of real time machine learning seems simple enough: build a system that immediately learns from the freshest data, and it will always give you the best, most up-to-date predictions. In practice, however, learning and predicting are two distinct steps that happen in sequence. First we use an algorithm to find patterns in our data; these patterns are a “model”, and we’ve “trained” the model on our data. Next we take a new data point and look it up in the model to get a prediction; this lookup step is called “scoring”.
For example, I used BigML to train a model on the famous Iris data set, with the goal of using a flower’s measurements to predict its species. The resulting decision tree model organizes flowers into groups, which are easy to see in this SunBurst visualization:
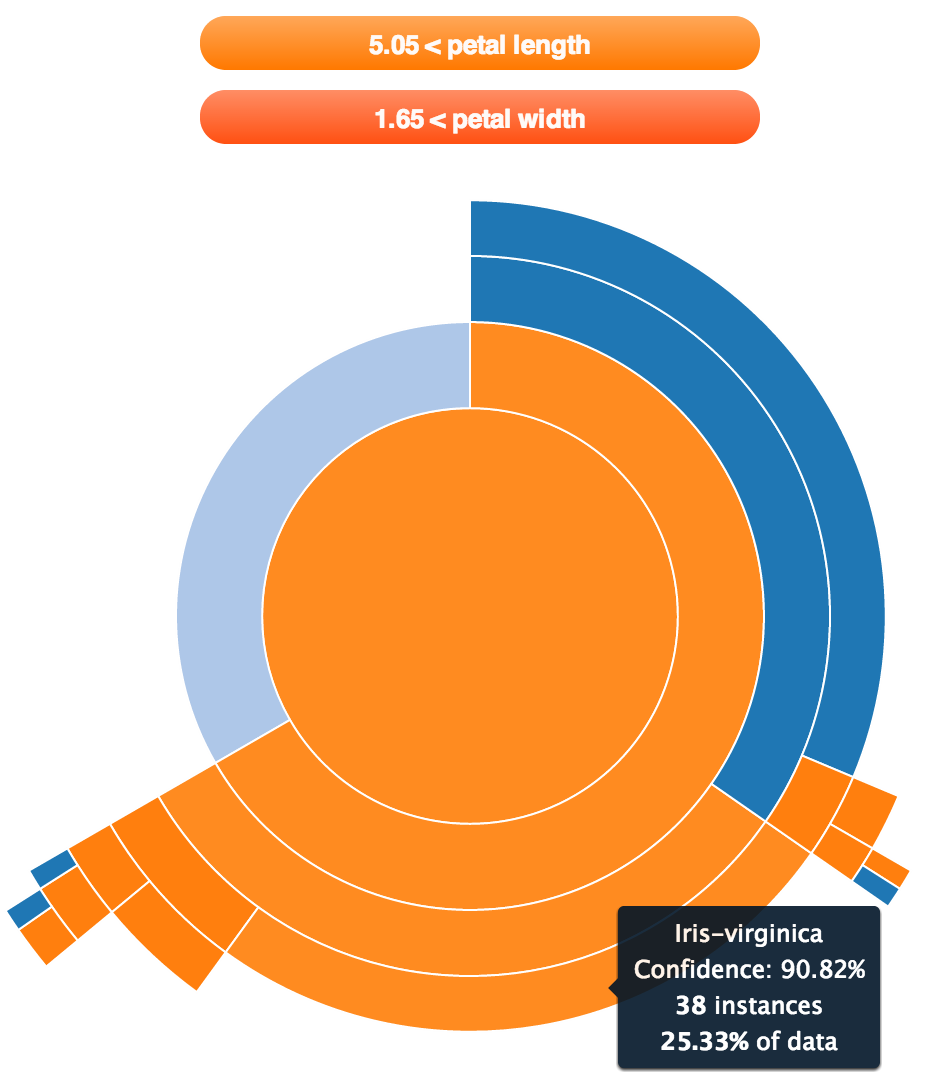
There’s one group of flowers with petal width more than 1.65 cm and petal length more than 5.05 cm, and in that group the concentration of Iris virginica is very high (actually 100% in this dataset). So if I’m out in a field near the Gulf Coast and find a purple flower with these measurements, I’m pretty confident that I know its species. If I can’t remember the species name—perhaps I’m just starting out as a botanist—then I can just look it up in the decision tree model, shown here as a collection of nested if/then statements:
IF petal_length <= 2.45 THEN
species = Iris-setosa
IF petal_length > 2.45 AND
IF petal_width > 1.65 AND
IF petal_length <= 5.05 AND
IF sepal_width > 2.9 AND
IF sepal_length <= 6.4 AND
IF sepal_length > 5.95 THEN
species = Iris-virginica
IF sepal_length <= 5.95 THEN
species = Iris-versicolor
IF sepal_length > 6.4 THEN
species = Iris-versicolor
IF sepal_width <= 2.9 THEN
species = Iris-virginica
IF petal_length > 5.05 THEN
species = Iris-virginica
IF petal_width <= 1.65 AND
IF petal_length <= 4.95 THEN
species = Iris-versicolor
IF petal_length > 4.95 AND
IF sepal_length > 6.05 THEN
species = Iris-virginica
IF sepal_length <= 6.05 AND
IF petal_width <= 1.55 THEN
species = Iris-virginica
IF petal_width > 1.55 THEN
species = Iris-versicolorWhen I do this lookup, I’m “scoring” the new flower I just found, guessing its species using a model that was “trained” on previous flowers whose species was known. This lookup is very fast, because I only care about the rules (highlighted in blue) that match the one new flower I’m examining. If I used BigML to export this model as code, a computer would do the same fast lookup for the new flower, using the same small number of rules. This is one of the nice features of decision tree models: because they’re just big nested if/then statements, they look up predictions for new data points really fast—they “score” very quickly.
Which brings us back to the meaning of “real time”. The Iris example shows that you can score quickly without having to train in real time. And in practice, it’s often overkill to train a model in real time: there’s no reason to think an entire field of purple flowers will suddenly have shorter petals from one minute to the next, and likewise we don’t expect sudden big changes in a database of movie ratings or credit card transactions. In some cases, like text recognition, the patterns we’re trying to learn hardly change at all over time.
BigML provides four ways to do scoring: by using our web UI, by using our API, by exporting the model as code with a single click, or by using our new high performance PredictServer for large scale applications. In cases where a model actually needs frequent retraining, BigML does that too, using parallel computation and streaming data to train models in seconds or minutes, even on large datasets.
So the next time someone waxes poetic about real time machine learning, make yourself look really smart by asking if they mean real time training or real time scoring. But be careful: they might offer you a job, or maybe even jump off a bridge.
