This is a guest post by David Gerster (@gerster), a data scientist and investor in BigML.
I work at a consumer web company, and recently used BigML to understand what drives return visits to our site. I followed Standard Operating Procedure for data mining, sampling a group of users, dividing them into two classes, and creating several features that I hoped would be useful in predicting these classes. I then fed this training data to BigML, which quickly and obediently produced a decision tree:
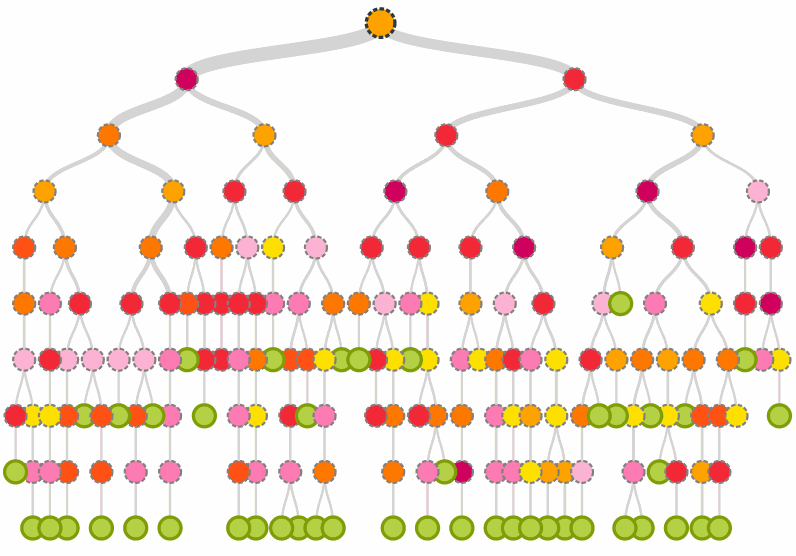
Next I used BigML’s interface to examine the tree’s many subsets, shown as “nodes” in the diagram above. I moused over a node at the top of the tree and saw that it achieved high separation for a large fraction of the training set:
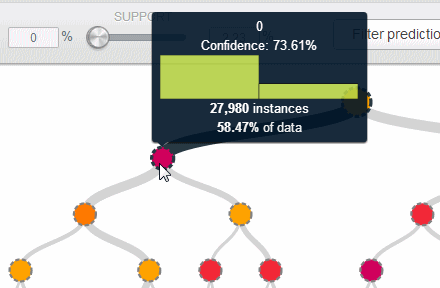
This one node covered 58% of the data, and separated the two classes with 73% confidence. (“Confidence” is a measure of node purity, and for this node 73% of the data belongs to class “0”.) With a little more work, I found another node that covered another 22% of the data, this time predicting class “1”. For the remaining 20% of data, the best rule I could find (after much mousing-over in the tree) was a single node with a lousy 51% confidence—barely an improvement over flipping a coin. I affectionately named these nodes Rule 1, Rule 2 and Blind Spot.
This is a common use for decision trees: gaining insight by finding the “best” nodes as measured by the fraction of data they cover (“support”) and their purity (“confidence”). When exploring a decision tree for insight, the goal is to find the smallest collection of useful rules that accurately summarizes your data.
Today BigML is launching the SunBurst visualization, which makes it much easier to gain insight from decision trees. Below is a SunBurst viz of my tree: the nodes are now shown as arcs, with the number of radians representing support and the color representing confidence. With a minimum of manual searching, I can easily find Rule 1, Rule 2 and especially the Blind Spot (which, together with its subsets, stands out in ugly, non-predictive brown):
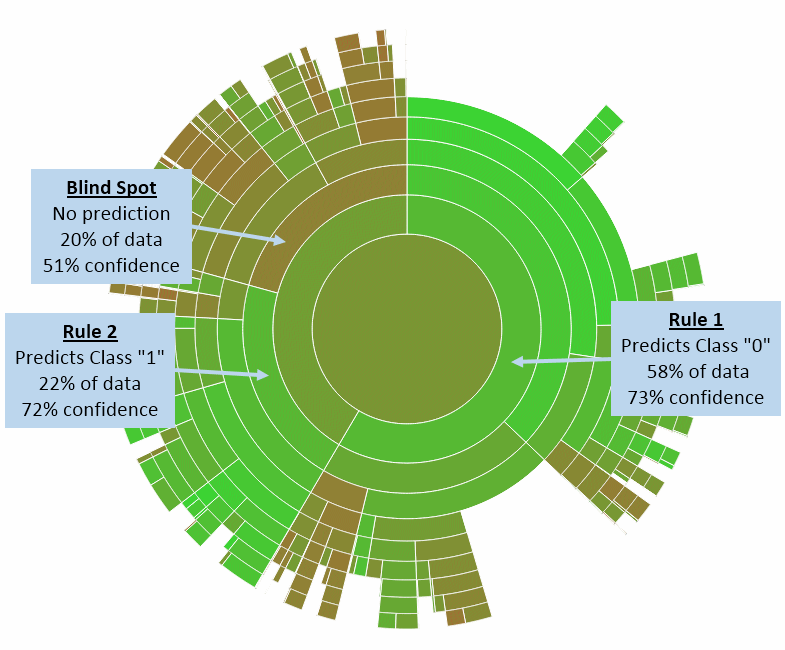
Let us ponder the amazing feat this Burst of Sun has achieved. In an eight-dimensional data set of 48,000 instances, I can see immediately which nodes have the highest combination of support and confidence. But wait, there’s more: I can also see exactly how all of the nodes fit together in a tree hierarchy, which gives me further insight into the data. For example, the upper right of the tree shows several large subsets of Rule 1 that glow bright green, and a closer look reveals that these subsets stack like Russian nesting dolls, each one prettier (but smaller) than its parent. So if I felt that Rule 1 misclassified too many instances, I could easily select one of its prettier children instead, choosing higher confidence at the cost of lower support.
Try out the SunBurst confidence visualization for yourself by training a model, going to the Models tab, and clicking the hypnotic SunBurst icon:

Then just click the Confidence icon. May all your nodes be green!

Better visualization obviously does not solve everything, and the usual cautions about understanding your data and validating your model still apply. While the above model is useful (since I haven’t said anything about the actual data it’s trained on, you’ll have to take my word for it), I still want to try a larger data set, and validate the resulting model by splitting the data into training and test. Perhaps most importantly, we cannot assume that two subsets with similar confidence but different predicted classes (like Rule 1 and Rule 2) will make equally valid rules in practice, since a false positive could be much, much worse than a false negative, or vice versa.
Nonetheless, the SunBurst is a huge leap forward in decision tree visualization. BigML’s Adam Ashenfelter explains that the SunBurst “may not be as intuitive as our regular tree view”, and he’s right—it’s about a thousand times more intuitive than the regular tree view. You can have my SunBurst when you pry it from my cold, dead retinas.

Reblogged this on DECISION STATS and commented:
a nice addition to Big Data Visualization- sunbursts (which I have covered in the Dat Viz chapter of my R book)
Great work by BigML.com
Is it possible to change the colours of a sunburst from the dashboard?
Thanks.