Predicting is not a terribly exact activity. If you want to know exactly what will happen tomorrow, you’ll have to wait until the day after tomorrow. And then it’s called ‘reporting’. It has the obvious downside that through a report there is little you can do to anticipate what happened yesterday. If you want to be better prepared for what is happening in the future and act upon it, you’ll have to predict and accept that predicting comes with uncertainty.
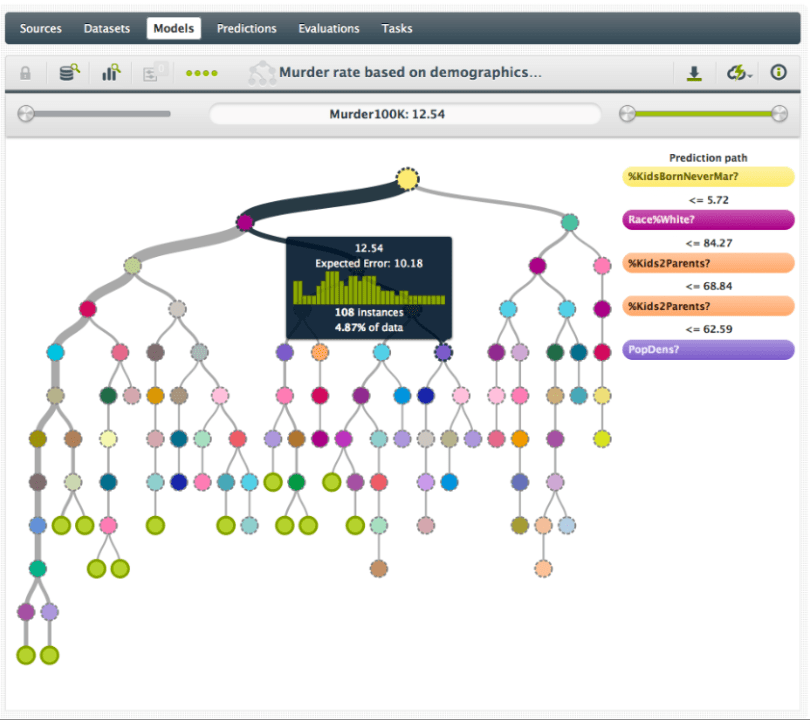
BigML has just released new features to support you in working with that uncertainty. As you explore your predictive model and navigate the various decision paths that lead to predictions, you can now see how confident we are that it is a correct prediction. At every single node we will show you:
- The number of instances that support this node
- What percentage that is from your total training data
- The distribution of all values at this node
- The actual prediction at that node
- For categorical trees, the confidence level for the prediction at the node
- For regression trees, the expected error for the prediction at the node
These last two, the “confidence level” and the “expected error” are there to help you measure how certain you can be of your prediction. Both values are based on two sources. Firstly, they take into account the distribution of the classes at this node. For instance, if ten instances pass through a node, seven ‘yes’ and three ‘no’, the prediction will be ‘yes’ but with a lower confidence than when all ten instances are a ‘yes’. Secondly, confidence takes into account the number of instances that the prediction is based upon. Uncertainty about a predicted class is higher with only 10 instances than, for instance, with 1,000 instances. So the confidence will be higher as the prediction is based on more instances.
Using these numbers, we can create “confidence intervals” around some of the statistics at each node. The idea is to give you a number that will probably underestimate the performance of your model. So our confidence number for classification trees means essentially, “BigML is fairly certain that the prediction at this node will be right at least this percentage of the time”. Similarly, the expected error for regression trees means that your average prediction error at this node will be almost certainly better than the number provided. In short, these numbers are both pessimistic estimates of the truth.
Of course, these numbers come with the usual caveats. If you train your model on, say, car sales in San Francisco and use it to to predict car sales in Alpha, Michigan, you’ve just ruined everything. Confidence and error, like the rest of your model, is only useful when your training data is “somewhat similar” to your testing data (in statistics we would say that the data must be drawn from the same distribution).
So What is ‘Confidence’?
Confidence tells us how certain the model is that it predicts the right class at a certain node. It’s a value between 0%: ‘no guarantees at all on the quality of the prediction’ and 100%: ‘prediction is absolutely certain’. The full technical definition is: “Classification confidence is the lower end of the Wilson score interval (at 95% confidence) about the probability that the node’s prediction matches the class of one of the node’s instances”. Well, let’s just remember that the higher the confidence, the better.
Let’s look at two examples from the Iris-model that predicts one of three iris species.
 The prediction for this node is the species ‘iris versicolor’. 52 Instances reached this node, 48 of class ‘iris versicolor’ and four instances of class ‘iris virginica’. The confidence for this prediction is 81.82%, with both a high occurrence of the predicted class (48 out of 52) and a decent amount of instances.
The prediction for this node is the species ‘iris versicolor’. 52 Instances reached this node, 48 of class ‘iris versicolor’ and four instances of class ‘iris virginica’. The confidence for this prediction is 81.82%, with both a high occurrence of the predicted class (48 out of 52) and a decent amount of instances.

This node predicts ‘iris virginica’, based on three instances. Two instances with class ‘iris virginica’ and one with ‘iris versicolor’. The confidence is only 20.76%, mainly because of the low number of instances that support this prediction, but also because the majority class here is 2/3, whereas the previous case had a stronger majority.
How About ‘Error’ for Regression Trees?
For regression trees that predict a number in stead of a class, an error is given to indicate uncertainty. When a node predicts a value with an error of 9.01, it means that the prediction is, on average, likely to be within 9.01 of the target. Keep in mind that this is an average, so while a single prediction may be more than 9.01 away from the true target, on average you are likely to do better than that.
An example of Error:
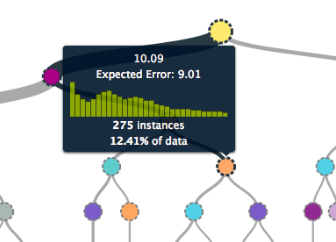
For this node, the tree predicts a value of 10.09, with an expected error of 9.01, based on 275 instances.
The expected error might not be the most useful number of you. You might have other questions like, “What’s the possible range for the target value at this node?”, or “What is the probability that a target at this node will be greater than some value?”, or even “Is my error more likely to be skewed to one side of the prediction?” To help answer those questions, the pop-up also shows you the distribution of those 275 instances. When you mouse over it, you’ll see the values in each bin of the histogram.
Confidence in Your Predictions
These features add to your insights and help you deal with the uncertainty that comes with working with predictive analytics. If you have questions or ideas for improving our services, we apreciate your feedback.

How can i get the confidence for the downloadable model e.g. in ruby?
How can i get the confidence in the executable model e.g. in ruby?
Instead of using the web version, download them model programmatically, and then reify the model locally. For example, using Python you can do something like this:
from bigml.api import BigML
from bigml.model import Model
api = BigML()
remote_model = api.get_model(‘model/52c7b3f90c0b5e6475000f07′)
local_model = Model(remote_model)
local_model.predict({}, with_confidence=True)
[u’false’, 0.61665, [[u’false’, 500], [u’true’, 268]], 768]
You’ll get the prediction, the confidence, the distribution, and the total count.
The json version of the model comes with the distribution and the confidence at each node of the tree.
Hope that helps!
Please connect with us at https://bigmlinc.campfirenow.com/f20a0 or drop us an email to support@bigml.com for faster support.
Best, francisco
Could anybody clarify me the definition of expected error? I don´t get to understand what it is.
Hi Jaime-
You can refer to Section 1.2.7 of our Dashboard documentation found here for a detailed explanation: https://static.bigml.com/pdf/BigML_Classification_and_Regression.pdf?ver=ff12bfb
thank you very much, it has helped me a lot