Peer to peer lending has become more popular recently, with services like Kickstarter and Indiegogo serving as de facto investment vehicles, and services like LendingClub enabling individuals to serve the role of private lenders to people with credit problems or who may otherwise not be eligible for traditional loans. Kiva has a similar peer-to-peer focus, but has a charitable approach: all loans are interest-free and are primarily granted to individuals from emerging countries for the purpose of bettering themselves through business or education investments.
What is the objective of this model?
With a 99% repayment rate to date, the vast majority of Kiva loans are paid back in full. Nonetheless, we wanted to see how we can predict the outliers: the small fraction of loan recipients who were unable to repay the loans. You can view and clone the model here.
What is the data source?
We pulled the Kiva data from build.kiva.org, which is a Kiva-sponsored site targeted at enabling developers to get a granular understanding of Kiva data. To pull the data into BigML, we used a data snapshot, which included 1,122 JSON/XML files ranging from 1-3MB in size each. We then downloaded that .zip file of JSONs, and developed a Python script to process all JSON files, in order to build a unique CSV file with the fields we thought would be most relevant for our modeling objectives.
What was the modeling strategy?
Through the manner we accessed the data, it was already somewhat processed and optimized for BigML ingestion. However, we still had 29 fields to pick and choose from. Since our objective was to identify trends for the minority of Kiva borrowers that default, it was important to deselect certain fields that would likely skew the trees and results such as “paid date” (as that wouldn’t be relevant for unpaid loans), and also the field for “delinquent” (as that would have a disproportionate match with unpaid loans). We also deselected redundant fields (e.g., we chose “country” but not “country code”). Last but not least, the BigML heuristics automatically deselected two text fields as we do not *yet* have text processing support (but stay tuned!).
What fields were selected for this model?
Fields selected for this model were: country, loan amount (total size of loan request), funded amount (the actual amount loaned) sector (one of 15 industries), funding date (year, month, date and day of week). In total there were 500K+ instances.
What did we find?
The top node of the tree and the field with the greatest importance was funding year (76%). This is probably due to the fact that loans made more recently are still in repayment mode–and perhaps also due to improvement in Kiva’s processes as the organization has become more mature.
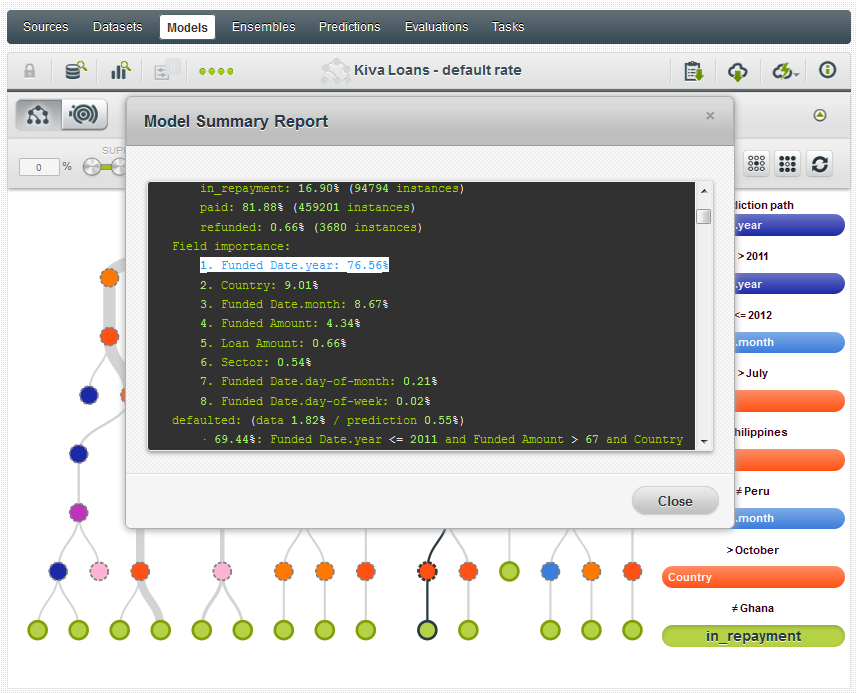
Based on all of these selected fields, we found that the loan with the highest confidence of default would have been a loan made in Afghanistan in the first quarter of 2011:

We looked at an iteration of the model without funding year (which would give you a better feel for which loans are most likely to be defaulted on), and the result was a pretty flat tree–but which again pointed to Afghanistan as the riskiest country in which to issue a Kiva loan when we filtered by “defaulted”.

Again, it is important to emphasize that with a 99% repayment rate, Kiva loans are still *very* likely to be repaid in full. To validate this point, we ran a prediction against an Ensemble of ten models with the original data points other than country, for a $1,500 loan. The predicted status was over 95% for “paid”–and bear in mind that the second most common options is “in progress.”

We encourage you to clone the dataset to your own account, and start running your own models and predictions. In addition to evaluating repayment status, you can change the objective field to predict sector or amount repaid or time to repayment. And visit www.kiva.org to see how you can get involved to directly help aspiring individuals in emerging communities around the world.
Stay tuned for an update on this study after we’ve released our advanced text processing and other new features into production–the text descriptions of the loan purposes add a very interesting variable!

2 comments