The 2012 US presidential elections saw Democrat Barack Obama win re-election, soundly defeating his Republican opponent Mitt Romney. “Soundly” of course, refers to the Electoral College results, where the President outpaced Romney 332-206. But the popular vote was proportionally much closer, with Obama taking 51%, to Romney’s 47%—demonstrating that while the President was favored by the majority of voters, America is still a nation very much divided by party lines.
What is the objective of this model?
We thought it would be interesting to look at the results at a more granular level based on different county-specific economic and demographic data like population density, age, unemployment rate, per capita income, home value, education level and more.
You can clone the model in BigML here, and the dataset here.
What is the data source?
We pulled elections data from The Guardian, and the demographics data from Esri, hosted in the Azure Datamarket. (as you may recall, BigML has provided users with a widget that makes it easy to browse and import data from the Azure Marketplace). The elections dataset had to polished to define the most voted candidate in every county, and the information was crossed with the demographic dataset using a relational database. The data was combined into a single .csv for BigML ingestion.
What was the modeling strategy?
While many (if not most) models built with BigML are done for predictive purposes, BigML is also very effective in analysis of historical data to uncover causal relationships between data, and to see how these relationships have influenced a net result. In this model, for example, we wanted to see how demographic and economic information influenced a candidate’s popularity in American counties. Plus, we think that guys like Nate Silver are already doing a pretty fine job of predicting election outcomes..
What fields were selected for this model?
While the .csv file that we generated had many fields, some fields have inter-dependencies and thus should not be selected together in the same model (i.e. party winner and candidate winner); however, these fields can always be used to build alternative models. Fields selected for this model were: total population, median age, % bachelors degree or higher, unemployment rate, per capita income, total households, average household size, % owner occupied housing, % renter occupied housing, % vacant housing, median home value, population growth 2010 to 2015 annual, house hold growth 2010 to 2015 annual and per capita income growth 2010 to 2015. The objective field in the model is the winner or most voted candidate in the county (Barack Obama / Mitt Romney). In total there were 3114 instances (which is the number of counties in the United States).
What did we find?
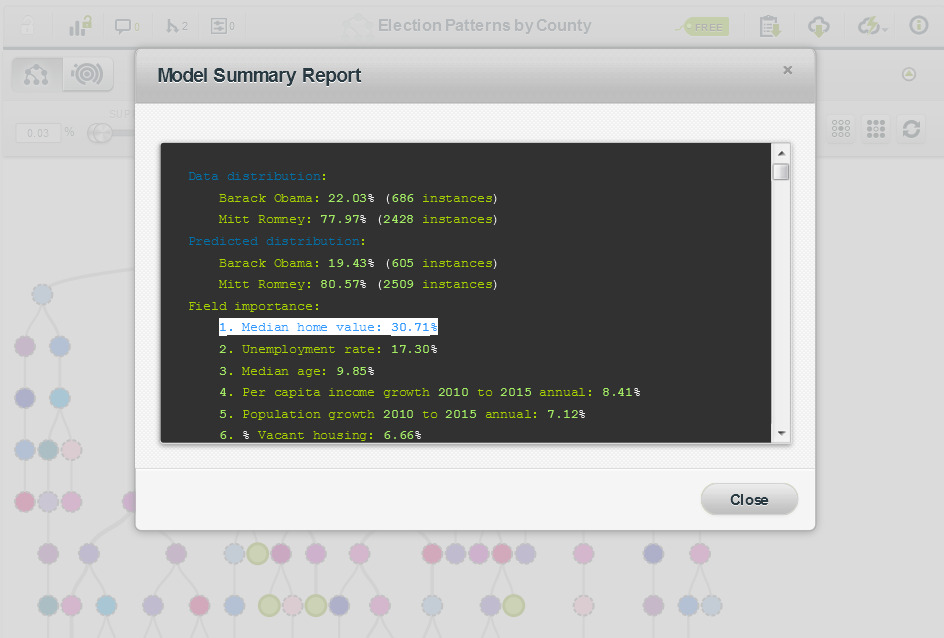
The field with the greatest importance was Median home value (30.71%).
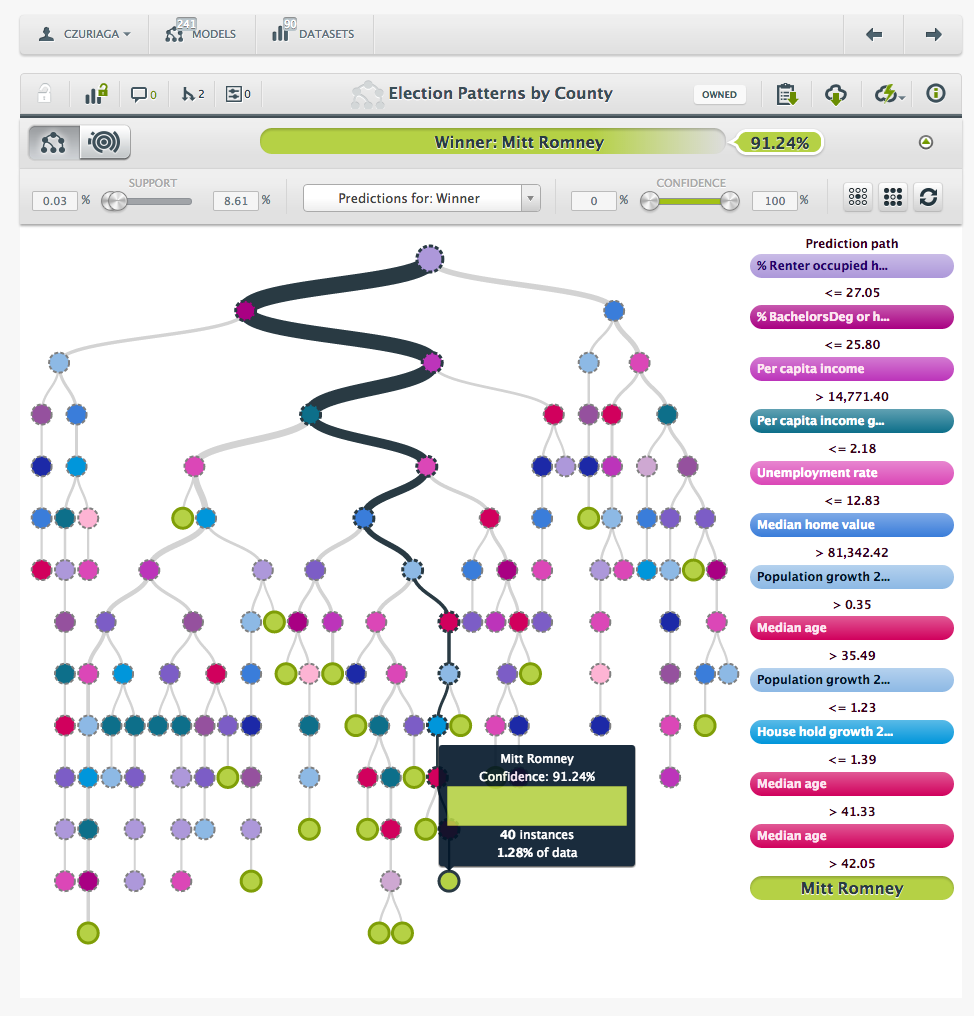
The top node of the tree was % Renter occupied housing—and you can observe below that Mitt Romney was the most voted in 2,428 counties, a whopping 76.48% of the total number of counties. Mr. Obama won the election, of course, so the disparity between the county-by-county vote and the actual popular vote is likely explained by the fact that Romney was the most voted in counties with small populations, while Obama was mainly in highly populated counties with larger cities.
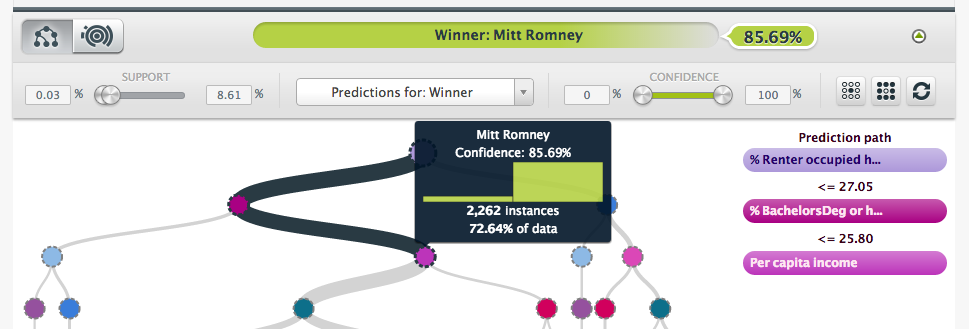
Looking closer at the tree, we see that the 83.23% of the counties where % Renter occupied housing was below the 27.05% threshold (meaning more people have home ownership), the most voted candidate was Mitt Romney. Looking at second level of the tree, in the left branch is observed that counties with a lower rate of citizens that hold at least a Bachelors also voted for Romney (85.69% confidence). Both the housing trend and the education trend support the fact that rural Americans were more likely to vote for Mr. Romney.
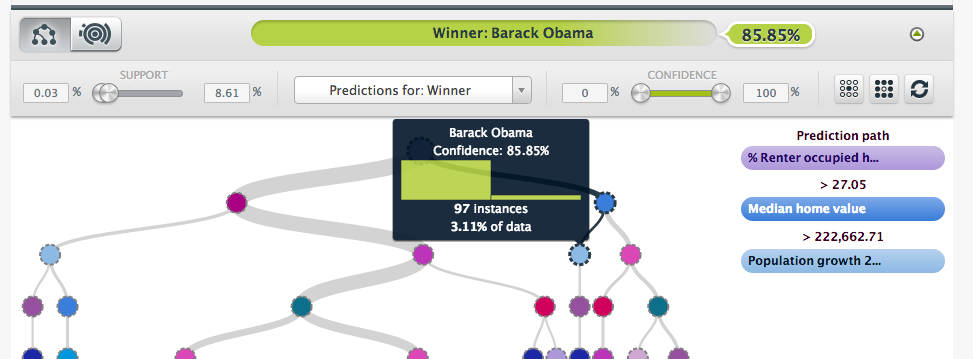
Furthermore, In the right branch, counties with high Median home value are for Obama (85.95%)—clearly another trait of urban voters. In fact, virtually every result of confidence splits following decision nodes throughout the tree supported this rural vs. urban trend.
To test and validate these relationships against actual data, we built a map based on the BigML dataset in CartoDB. And looking at this representation, we see that Obama won votes in the most populous counties, which were enough to take the state electoral votes, and ultimately to reclaim the Presidency.

Final Thoughts:
“Well, duh” you may say in pointing out that urban voters leaned left, while rural voters leaned right—this is a well-known trend in American politics since the early 1980’s. But what we found most interesting about this model was the ability to get a finer-grained understanding of what voter traits had the *greatest* impact on likely voting outcome (beyond just where someone lives), and also the associated confidence levels. Give it a shot, and let us know what you think!
