Following our previous posts on how to improve results when using Machine Learning on imbalanced data, in this post, we’ll talk about oversampling and undersampling. We’ll discuss a particular example that will help us see how these approaches can be combined with an automated search to create a well-tuned model from our data.

The Imbalanced Example
The data we’re using to illustrate this post was published as one of Kaggle’s contests: Give Me Some Credit. You can download the CSV from Kaggle’s site or better yet you can quickly import it into BigML cloning it from our gallery. The data describes examples of loans that ended up becoming seriously delinquent (or not) in two years.

As seen above, the dataset is imbalanced, because it only contains a few examples of people recorded as seriously delinquent (< 7% of the data). Our goal is to find out if someone is prone to fall into that class, so we’re trying to build a model that does a good job of predicting the minority class. That can be difficult since the algorithm will tend to learn better the class with more examples, so we’ll need a technique to compensate for the imbalance.
The Baseline Model
We start by following the naive approach, that is, creating a simple model and evaluating it. That will give us a baseline of the performance that we’ll need to improve on. Let’s be careful, though, because the first step should be creating train/validation/test splits and ensuring that the proportion of instances that fall into the minority and majority classes is maintained in all of them. If your dataset is big enough with every class well-represented in it, a simple random split will do. However, the number of instances for the minority class can be very small if the imbalance is high, so it’s best to apply a stratified split on the minority class. That’s easily doable using the stratified split WhizzML script. We’ll use the train dataset to train all our models, the test dataset to create the final evaluations and compare their performances, and the validation dataset will be kept apart and used to help us in model tuning.
Our first model will be a decision tree and because we’re trying to solve an unbalanced problem aiming to predict the minority class, we can’t rely on accuracy to tell us if we’re doing good. Therefore, we’ll focus on the phi coefficient for the minority class, that is SeriousDlqin2yrs=”1″.

As seen above, the recall is very poor, and that finally affects the phi coefficient as it will get closer to one only when both precision and recall approach 100%. Our goal is to find every loan that could be seriously delinquent, so we want to favor recall even if it means losing some precision. That said, we can’t afford to have too many False Positives either, so what can we do to optimize both recall and precision?
Oversampling vs. Undersampling
Two techniques are usually helpful to avoid the imbalance that is causing the poor performance of the model: oversampling and undersampling. Oversampling compensates for the imbalance by repeating the examples of the minority class and undersampling by keeping all the minority class examples and selecting only as many instances from the rest of the classes to produce a balanced sample. Hopefully, applying any of these will help the algorithm to learn better.
Let’s start by oversampling. BigML offers an option in the model creation configuration stage: balance_objective. It balances both classes by increasing the frequency with which the minority class instances are used to train the model, so to apply oversampling we only need to create a new decision tree using that parameter set to true.
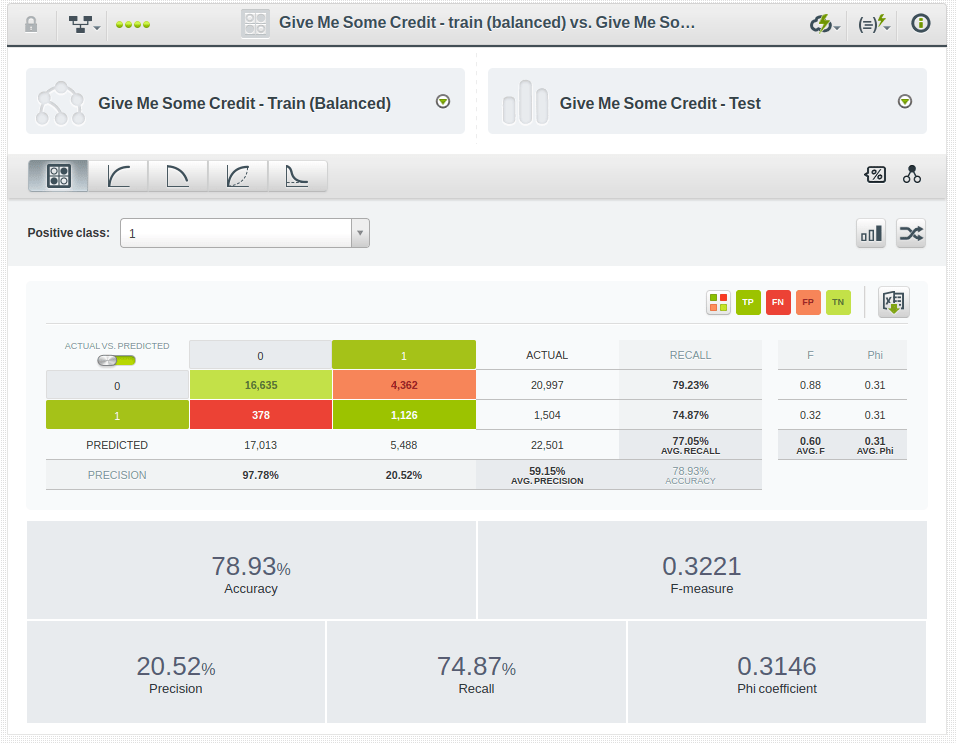
This has clearly improved the recall, but has resulted in a penalty on precision. However, the phi coefficient tells us that the model has improved altogether, so it seems to be evolving in the right direction.
As for undersampling, we select all the instances of the minority class and add to them a random sample of instances of the majority class to balance them. In this case, we can use the undersampling function available in the balanced-optiml WhizzML example script. Be in the know that many different undersampled datasets can be generated depending on the particular selection of the majority class instances, and their resulting models will vary slightly. Here’s the result for our particular case:
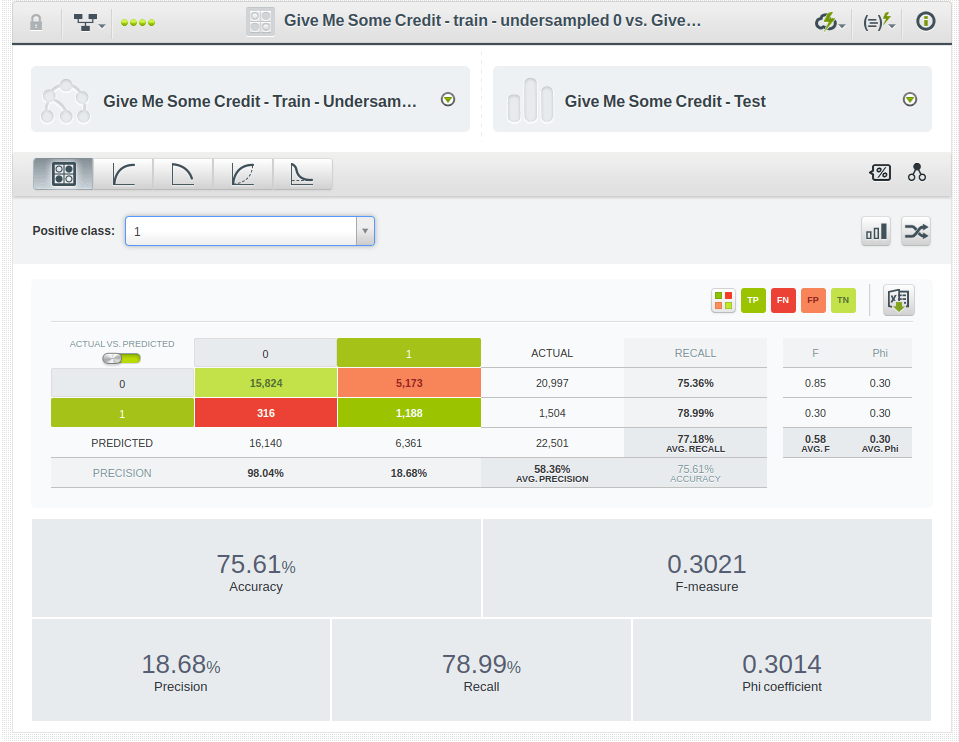
This step further increased recall but resulted in a higher penalty on precision. That means no improvement on the phi coefficient obtained with the simple balance_objective configuration option. For completeness, we tried a handful of different undersampled datasets and all of them produced similar results.
Automated Optimization
The three evaluations that we’ve seen so far correspond to decision trees that were not tuned (besides using the balance_objective parameter when oversampling). Obviously, we could try other models: ensembles, random decision forests, deepnets, logistic regressions, etc. We could also try configuring their parameters to improve their fitness or we can use an automated procedure to do that for us: OptiML
OptiML is BigML’s automated smart process to search for the Supervised Model that optimizes the evaluation metric of choice. But how does it work for Imbalanced Datasets? Can we provide our own validation dataset to ensure a correctly stratified sample will be used? Can we configure it to optimize a particular minority class? Are oversampling and undersampling compatible with OptiML’s search and evaluation process?
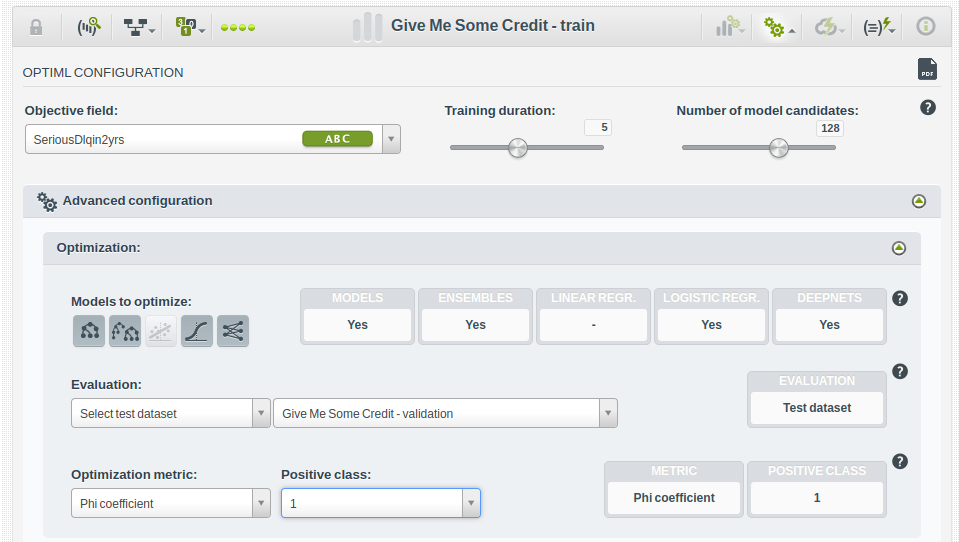
The good news is that the OptiML configuration panel offers options to choose a Validation Dataset to be used in the evaluations that guide the model tuning search. It also allows selecting both the optimization metric and positive class, which in this case should be the minority class. Also, the optimization process will try to use different weights to balance the classes in the objective field. That means oversampling will be tried by default as one more possible tuning option in the search for the best model. You don’t need to worry about it. The OptiML process will apply oversampling and see if it helps. In our example, we’re able to assert that it does, because the top-performing model we find uses the oversampling weight.
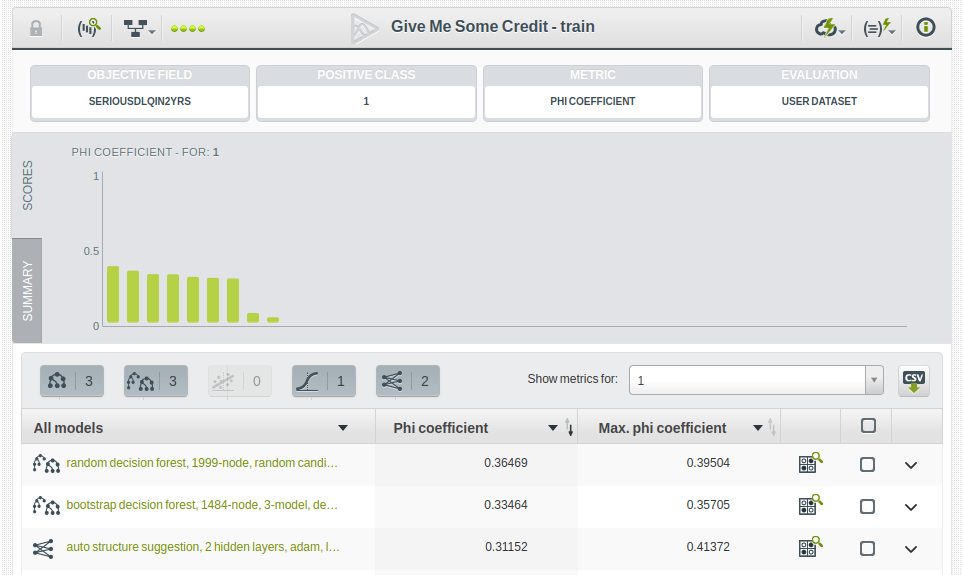
And it shows an improvement of the phi coefficient with respect to the baseline oversampled model, at least when evaluated against the Validation Dataset.
As for undersample, we can apply the technique to the dataset before creating the OptiML process on it and still use the same Validation Dataset to guide the optimization. In fact, we did that for five different undersamples and got similar results using the balanced-optiml scripts published in the WhizzML examples repository.
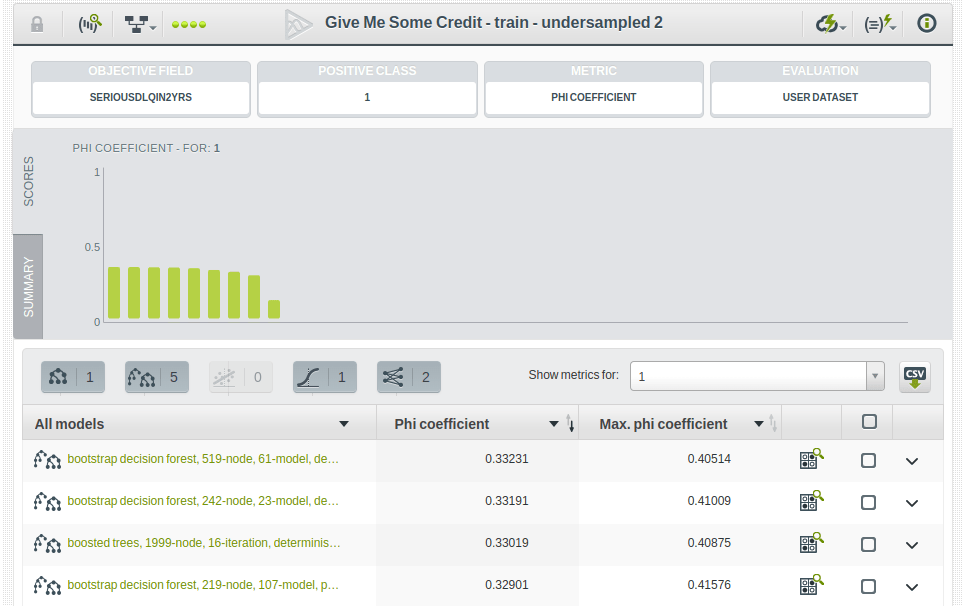
Once again, these evaluations correspond to the Validation Dataset results. To compare their performance with that of the baseline models, we use the Test Dataset to evaluate them. Results are slightly lower when using that dataset, but they still improve significantly over the ones obtained in the baseline scenario.

Conclusion
We’ve seen a simple example showing how to apply oversampling and undersampling techniques to an imbalanced dataset to optimize the performance of models that predict the minority class. Our evaluations showed both techniques seem to be improving performance similarly. However, oversampling is far easier to use thanks to BigML’s balance_objective configuration option, which can be set as needed and will be automatically tried by default by the OptiML smart search process. All in the name of making Machine Learning beautiful and easy for everyone!

3 comments