As Machine Learning practitioners, it’s important to know how Machine Learning algorithms work. This isn’t just to impress your friends at parties (trust me, this will not impress your friends at parties). The reason you should know how Machine Learning algorithms work is that when they don’t work, you can use that knowledge to figure out why, and maybe even how to fix them.
A Stitch In Time
Suppose you have a simple dataset that tries to predict a variable based on the value of that variable in the past. For example, you might want to predict the price of a stock based on its 5, 10, 50, and 300-day moving averages (Note: this is just an example; doing this will probably not give you useful price predictions). Imagine you have data for two stocks, one with a long-term average price of around $10 and another with a long-term average price of around $100, without too much variability about those values.
If you feed data like this to a decision tree, how will it behave? At each of the leaf nodes in the tree, it will assign a price based on the training instances that reached that leaf node. Importantly, the assigned price will probably be close to either $10 or $100 because those are the values it saw in training. If you have a stock that averages $50 or $500, the prediction for the future prices of that stock will probably be especially inaccurate.
If you learn a linear regression, this will be less of a problem: Because the prediction is a linear combination of the input variables, the model should give good outputs even when the inputs aren’t near the training inputs, as long as the same linear relationship holds for the inputs you provide. If you only have data for a few stocks, and you still want your model to generalize to stocks with prices that are much different, linear regression might be a better choice. Better still would be if you realized that before the error surfaced in a production setting.
Computer Vision: More of the Same
Let’s see if we can make some similar deductions about our Object Detection algorithms. Here’s a brief summary of how many Object Detection algorithms, including BigML’s, go about their business: First, they break the image up into a coarse grid. At each square, they consider several different bounding box proposals. These are just rectangles of some size, typically two or three at each grid square. If one of those rectangles holds most of one of the objects we’re looking at, they say there is an object present in that rectangle, then try to translate or scale the rectangle so it fits the object as snuggly as possible. The prediction ends up being several values: The probability that there is an object in the box, the adjustments to the x, y, height, and width of the box, and the distribution over classes for that box.
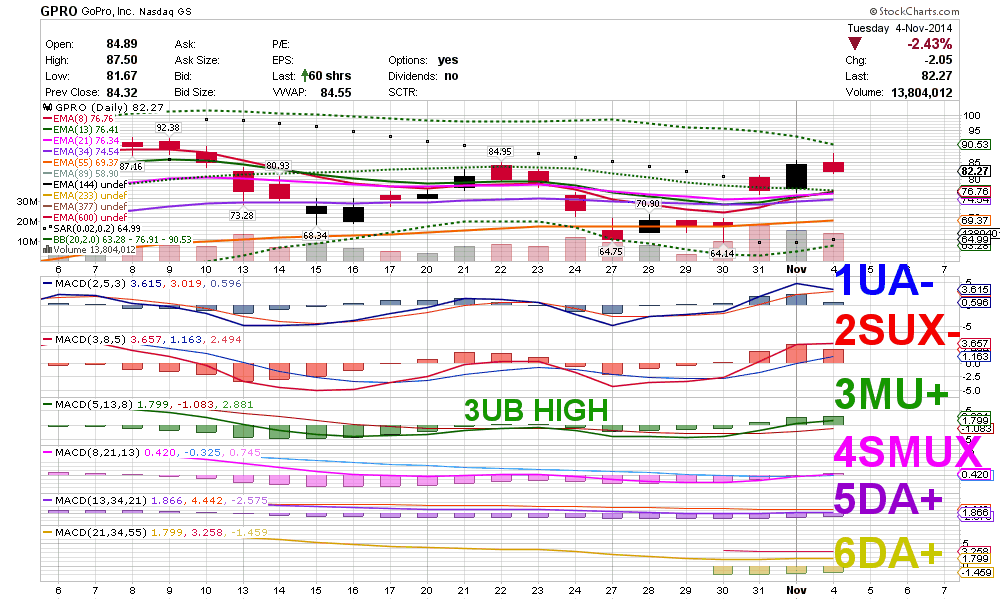
In this image, the detector would try each of the three bounding boxes shown at each square in the grid. You can see that at this particular location, one is very close to “containing” the chair. However, the box needs to shift a bit down and to the left for the chair to be properly centered. Our Object Detection model simultaneously predicts the presence and class of the chair, along with the adjustments needed to make the box fit properly.
All fine so far, but where do the bounding box proposals come from? In practice, we get much better results from these models if we learn the bounding box proposals from the training data. A simple way to do this is to cluster all of the bounding boxes in the training data by their dimensions, then take the centroid of each cluster as our list of proposals. The astute reader will probably see the implication: If you only see small objects in the training set, the set of proposals assures that you will only be looking for things of that size.
Ready, Set, Fail
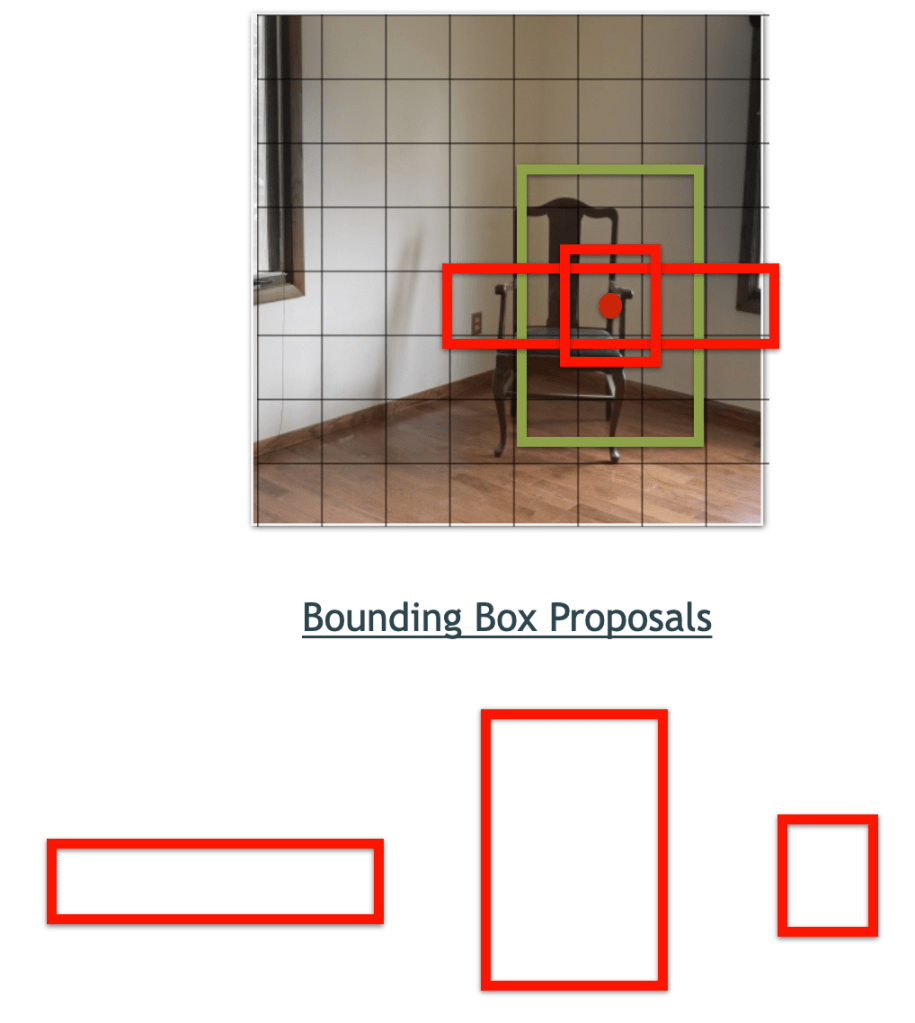
Let’s train an object detector to recognize some chess pieces. The images we’re using for training all have this view of the board:
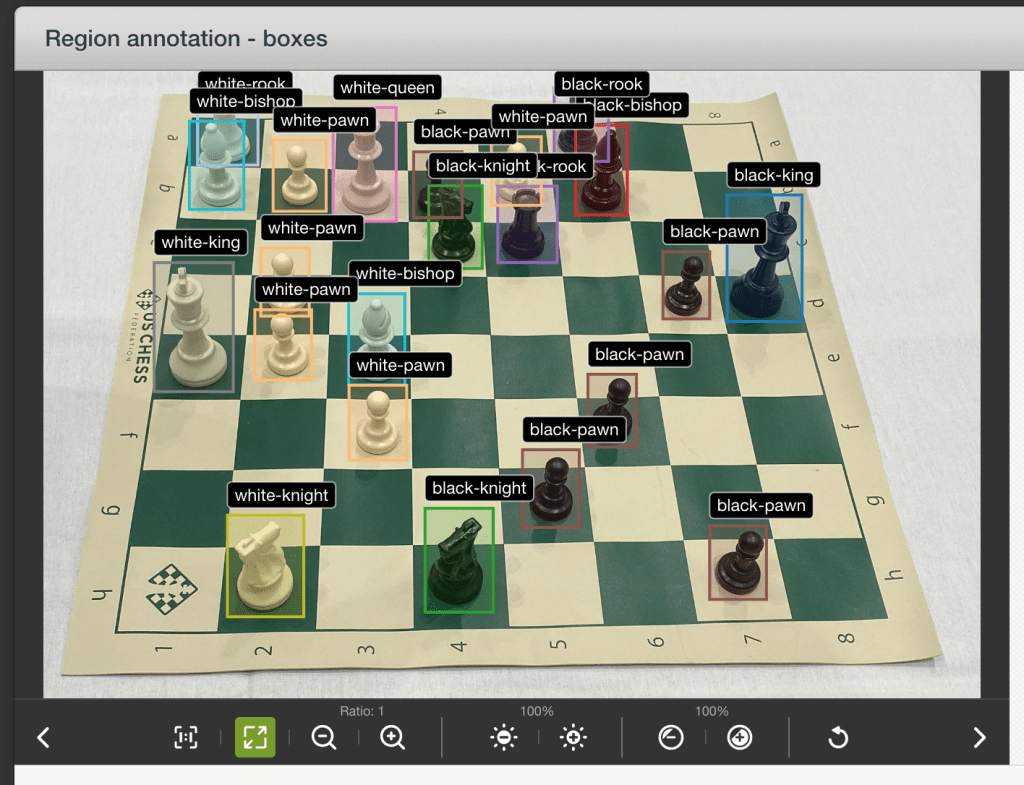
An evaluation shows that the model we train is very capable of recognizing black kings:
And in that case, this should be easy:

Wait, what?
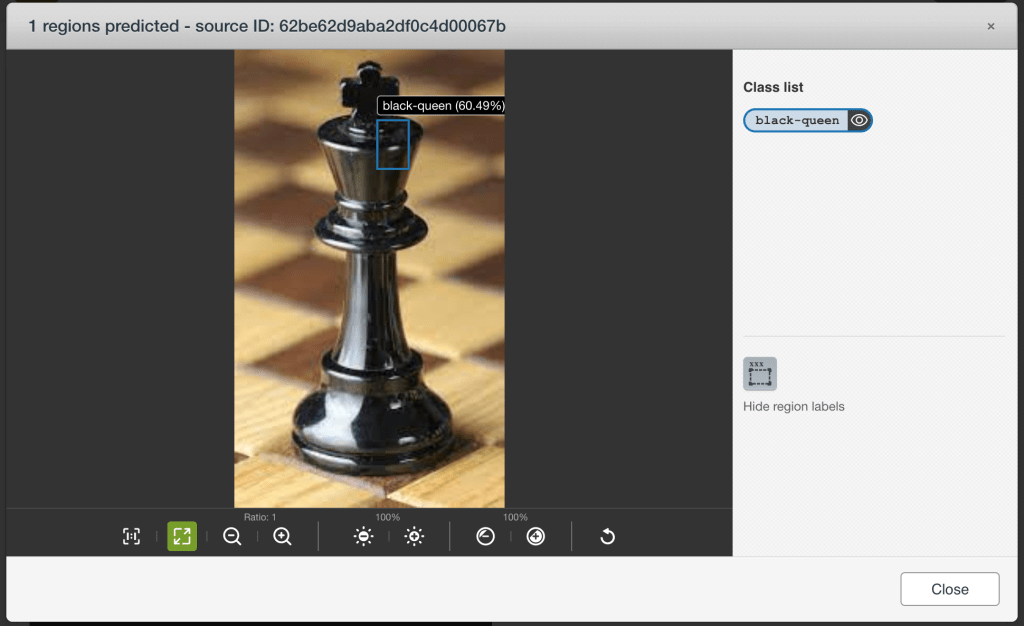
But let’s think about this for a second. All of the pieces that we saw in training were small relative to the image. Here we’re feeding it a chess piece that takes up nearly the entire image. There is no bounding box in the training data even close to this size. This, in the vocabulary that the model has learned, is absolutely not a chess piece of any kind. It’s way too big (though that little bit on the edge looks a bit like a black queen).
Looked one way, the model has failed. Why can’t our chess piece model detect chess pieces? Looked at in a more useful way though, we have failed. If we wanted our model to perform properly on this view of a chess piece, why didn’t we show it this view of a chess piece? Why did we expect the model to perform well in this situation that it’s never seen before?
The skeptical reader might balk at this line of thought: “So in order to get a general recognizer for chess pieces, I have to add every possible view of a chess piece to my training dataset. That’s impossible!” There is an unfortunate grain of truth to this: The more general you want a model to be, the more data you need. You can get around this a bit with tricks like data augmentation and using large pre-trained models, but you often can’t get all the way around.
However, you often don’t need to. If you can make guarantees on the input data, then it’s possible that a less than general recognizer will work just fine for the inputs you have in mind and it will take less data to train to boot. For example, if you only want to analyze images from a single view of a chess board, it makes no difference if you can recognize kings that take up the entire image because it’s never going to happen. In monitoring applications, where you’ve got a fixed camera looking at basically the same scene all the time, this can be an easy task.
As I’ve said before, writing code that works with machine-learned models is hard. You need to anticipate their failures and plan for their inaccuracies. Like any powerful tool, Machine Learning can give near-miraculous results, but only when handled with care. With some patience, onward and upward!
